
Python is one of the, if not the, most essential Data Science languages. It’s fairly easy to learn, it’s free, many companies are using it, and it has a tons of powerful statistical and data visualization libraries. In one sentence: if you are looking for a Data Science career, sooner or later you have to learn Python.
So I put together a Python for Data Science tutorial series starting from the very basics. As far as I know, this is one of the few Python tutorials online that’s:
- in Python 3 and not in Python 2 (see why this is important below)
- written for those who are just starting with coding
- started from the basics, then guides you all the way through to advanced things like using pandas and other analytical data science libraries
- 100% dedicated to being practical
- and free…
Here are the articles!
Note: I’m continuously writing new articles and adding them to the list.
Need a free Python Cheat Sheet first?
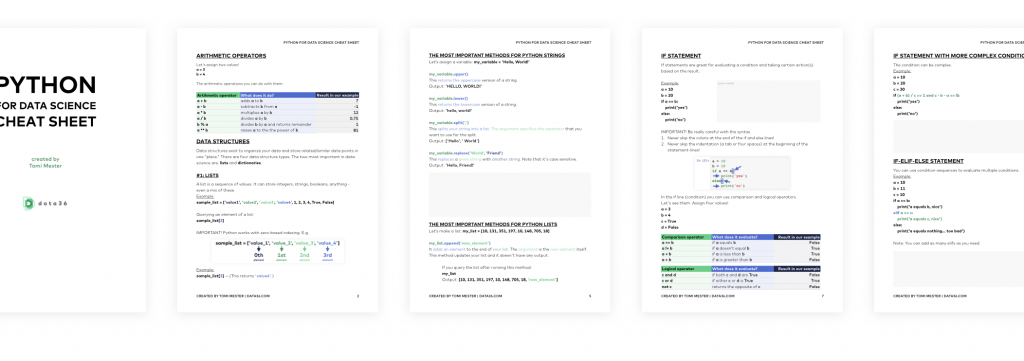
Get it in my FREE MATERIALS section. Here.
Python Basics (10 articles)
1) Install Python, SQL, R and Bash (for non-devs)
The very first step will be to set up your own Python environment. This article will show you how to do that. Plus, as an extra, if you go through the whole process, you will have bash, SQL and R too. The setup comes with the famous iPython and Jupyter Notebook Python extensions that will make your data-coding-life much easier! READ>>
2) Python Basics: the environment, Python variables and data types
I introduce the Jupyter Notebook, your soon-to-be-favorite interactive Python workspace. After that, we dig into the basics of Python: variables and data types (integers, strings, booleans, etc.). At the end of the episode you will find a quick exercise too! READ>>
3) Python Data Structures
The next article is about the most important data structures in Python: lists, dictionaries and tuples. You will learn how to create and modify these – and also how to access or update their elements. READ>>
4) Python Built-in Functions and Methods
Functions and methods are the one of the greatest advantages of Python. Using them, you can carry out simple but important data processes (like counting the number of elements, calculating the sum of integers, making strings upper- or lowercase, and so on…). In this article, I introduce the whole concept and give you a list of the most essential built-in functions and methods of Python. READ>>
5) Python if statements
Let’s get back to coding! The next chapter presents the if statements. You can learn about the logic of Python if statement – as well as the syntax and advanced applications. READ>>
6) Python for loops
For loops in Python are perfect for processing repetitive programming tasks. In this article, I’ll show you everything you need to know about them: the syntax, the logic, advanced applications and best practices too! READ>>
7) Python For Loops and If Statements Combined
Now that you know how if statements and for loops work, it’s time to combine them. I’ll show you how to build nested for loops, put if statements within for loops, and at the end of the article I’ll give you an intermediate Python task to test the skills you’ve gathered so far. READ>>
8) Python Syntax Essentials and Best Practices
In my Python workshops and online courses I see that one of the trickiest things for newcomers is the syntax itself. It’s very strict and many things might seem inconsistent at first. In this article I’ve collected the Python syntax essentials you should keep in mind as a data professional — and I added some formatting best practices as well, to help you keep your code nice and clean. READ>>
9) Python Import Statement and the Most Important Built-in Modules for Data Scientists
So far we have worked with the most essential concepts of Python: variables, data structures, built-in functions and methods, for loops, and if statements. These are all parts of the core semantics of the language. But this is far from everything that Python knows. Actually this is just the very beginning and the exciting stuff is yet to come. Because Python also has tons of modules and packages that we can import into our projects… READ>>
10) The 5 most important Python libraries and packages for Data Scientists
In this article, I’ll introduce the five most important data science libraries and packages that do not come with Python by default. These are: Numpy, Pandas, Matplotlib, Scikit-Learn and Scipy. At the end of the article, I’ll also show you how to get (download, install and import) them. READ>>
Pandas Basics: Data Wrangling and Visualization with Python/pandas (5 articles)
11) Pandas Tutorial 1: Pandas Basics (Reading Data Files, DataFrames, Data Selection)
Pandas is one of the most popular Python libraries for Data Science and Analytics. I like to say it’s the “SQL of Python.” Why? Because pandas helps you manage two-dimensional data tables in Python. Of course, it has many more features. In this episode we will start with the pandas basics! READ>>
12) Pandas Tutorial 2: Aggregation and Grouping
I’ll introduce aggregation (such as min, max, sum, count, etc.) and grouping in pandas. Both are very commonly used methods in analytics and data science projects. READ>>
13) Pandas Tutorial 3: Important Data Formatting Methods (merge, sort, reset_index, fillna)
In the 3rd episode of the pandas tutorial, I’ll show you four data formatting methods that you might use a lot in data science projects. These are: merge, sort, reset_index and fillna! READ>>
14) Pandast Tutorial 4: How to Plot a Histogram using Pandas
The 4th episode of the pandas tutorial series is about data visualization. I show you how you can create a histogram using pandas and matplotlib. And as an intro, I’ll also show you how you can draw a line chart and a bar chart, too. READ>>
15) Pandas Tutorial 5: How to Plot a Scatter Plot using Pandas
And I couldn’t miss from these articles one of the favorit charts of data scientists: the scatter plot. It’s a pretty cool way to discover and show correlations between two or more variables in a dataset. In this episode, I’ll demonstrate how you can create your first scatter plot using pandas and matplotlib. READ>>
Machine Learning with Python, pandas, numpy and scikit-learn (6 articles)
16) Linear Regression in Python (the most Basic Machine Learning Model)
Pandas and Python are very popular for machine learning. Machine learning is only ~5% of the job for junior data scientists. Regardless, I wanted to give you a brief intro into the most basic machine learning model: linear regression. Here, you’ll learn the statistics behind it, how it works — and of course, how to get it done in Python and Pandas… or well, in this case using numpy. READ>>
17) Polynomial Regression in Python using scikit-learn
Oftentimes you’ll encounter data where the relationship between the feature(s) and the response variable can’t be best described with a straight line. So linear regression won’t be enough. To curve your lines, here’s another widely-used – and more flexible – machine learning model: Polynomial Regression. Let’s see how to implement it with Python, pandas and scikit-learn. READ>>
18) Coding a Decision Tree in Python Using Scikit-learn, Part #1: Regression Trees
Classification is an important task when it gets to Machine Learning. And building a decision tree model is the easiest first step to understand this world. (Also the fundaments of more complex and better performing models like random forest.) Creating a decision tree model in Python is not that hard as it seems. The learning process starts with understanding what a regression tree is and how can you build one. This article will show you everything: the brief theory and then the code in Python + pandas + scikit. READ>>
19) Coding a Decision Tree in Python Using Scikit-learn, Part #2: Classification Trees and Gini Impurity
Following the previous tutorial, in this one, you’ll learn about the concept behind classification trees and Gini Impurity… And of course about how to implement all these with Python + pandas + scikit-learn. Putting together the knowledge from the previous regression tree article and form this one, you’ll be able to build your fully functioning decision tree models! READ>>
20) Random Forest in Python (and coding it with Scikit-learn)
Random Forest is one of the most popular classification models. It’s not by an accident: it’s easy to implement it and it performs very well. The name is very descriptive: a random forest is a bunch of different decision trees that overcome overfitting. More about the concept and the implementation of it in Python/pandas/scikit in the article. READ>>
21) K-means Clustering with scikit-learn (in Python)
K-means clustering is one of the most popular and easy-to-grasp unsupervised machine learning models. This article will show you the difference between supervised and unsupervised ML; it will teach you the basics of clusterin; and it’ll guide you through the implementation of a K-means clustering model with Python + scikit. READ>>
This is a continuously expanding article. So check back time to time!
Check out the SQL and the bash tutorials, too!
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester