
This is the third episode of my pandas tutorial series. In this one I’ll show you four data formatting methods that you might use a lot in data science projects. These are: merge, sort, reset_index and fillna! Of course, there are many others, and at the end of the article, I’ll link to a pandas cheat sheet where you can find every function and method you could ever need. Okay! Let’s get started!
Note 1: this is a hands-on tutorial, so I recommend doing the coding part with me!
Note 2: some of my code examples will be broken into more lines (by my blog engine) to fit your screen, while in your Jupyter Notebook they should be written in one line. If you copy-paste, it won’t be a problem – but if you don’t: watch out for these lines! By the way, if you made it this far with my tutorials, I’m pretty sure, you can handle this issue easily by yourself (but screenshots are also there to help you.) 😉
Before we start
If you haven’t done so yet, I recommend going through these articles first:
- How to install Python, R, SQL and bash to practice data science
- Python for Data Science – Basics #1 – Variables and basic operations
- Python Import Statement and the Most Important Built-in Modules
- Top 5 Python Libraries and Packages for Data Scientists
- Pandas Tutorial 1: Pandas Basics (Reading Data Files, DataFrames, Data Selection)
- Pandas Tutorial 2: Aggregation and Grouping
Pandas Merge (a.k.a. “joining” dataframes)
In real life data projects, we usually don’t store all the data in one big data table. We store it in a few smaller ones instead. There are many reasons behind this; by using multiple data tables, it’s easier to manage your data, it’s easier to avoid redundancy, you can save some disk space, you can query the smaller tables faster, etc.
The point is that it’s quite usual that during your analysis you have to pull your data from two or more different tables. The solution for that is called merge.
Note: Although it’s called merge in pandas, it’s almost the same as SQL’s JOIN method.
Let me show you an example! Let’s take our zoo dataframe (from our previous tutorials) in which we have all our animals… and let’s say that we have another dataframe, zoo_eats, that contains information about the food requirements for each species.
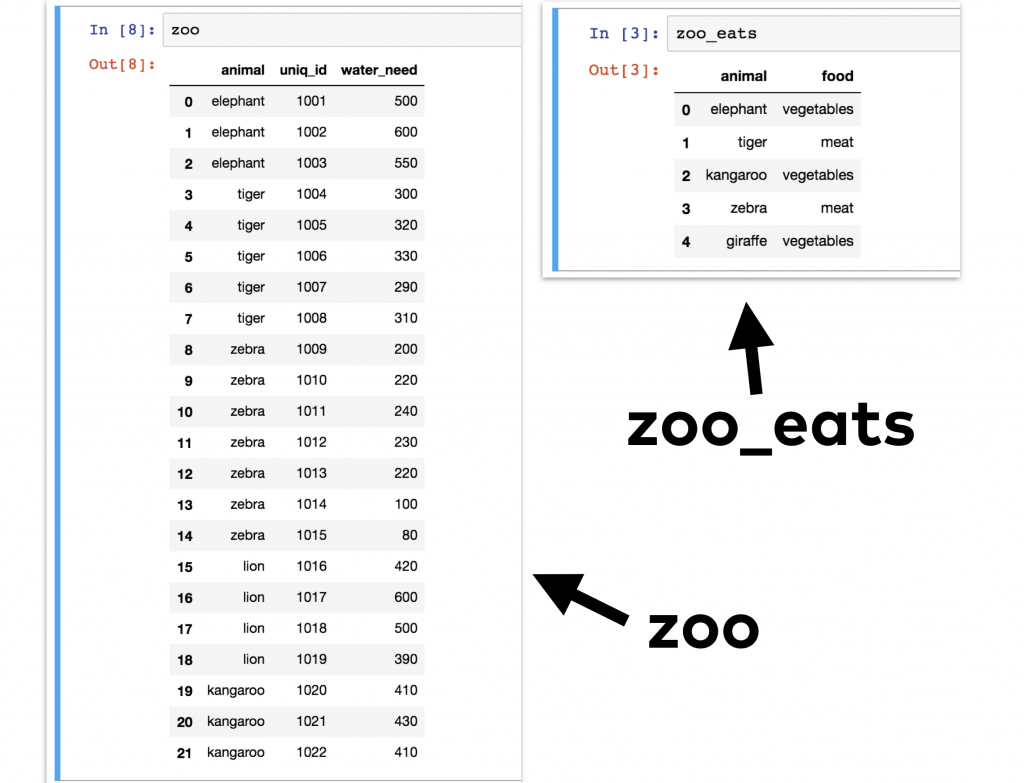
We want to merge these two pandas dataframes into one big dataframe. Something like this:
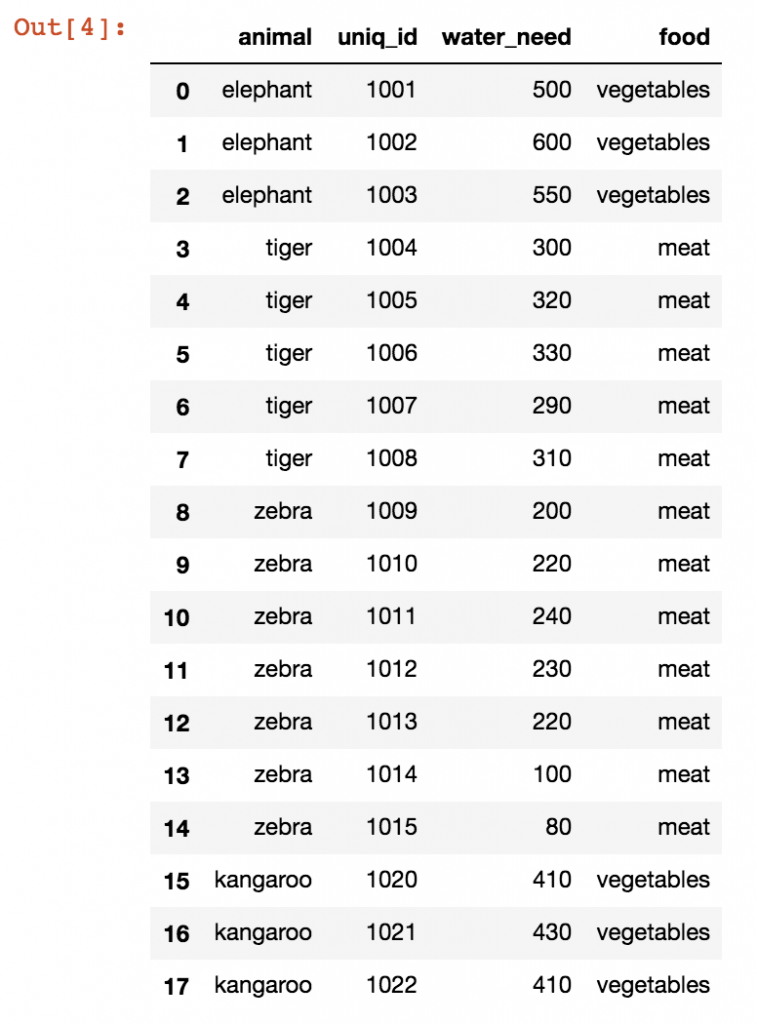
In this table, it’s finally possible to analyze, for instance, how many animals in our zoo eat meat or vegetables.
How did I do the merge?
First of all, you have the zoo dataframe already, but for this exercise you will have to create a zoo_eats dataframe, too. For your convenience, here’s the raw data of the zoo_eats dataframe:
animal;food elephant;vegetables tiger;meat kangaroo;vegetables zebra;vegetables giraffe;vegetables
If I were you, to put this into a proper pandas dataframe, I’d follow the process from the Pandas Tutorial 1 article, but if you want to do this the lazy way, here’s a shortcut. 😉 Just copy-paste this (really long) one line into the pandas_tutorial_1 Jupyter Notebook we made in the first Pandas tutorial:
zoo_eats = pd.DataFrame([['elephant','vegetables'], ['tiger','meat'], ['kangaroo','vegetables'], ['zebra','vegetables'], ['giraffe','vegetables']], columns=['animal', 'food'])
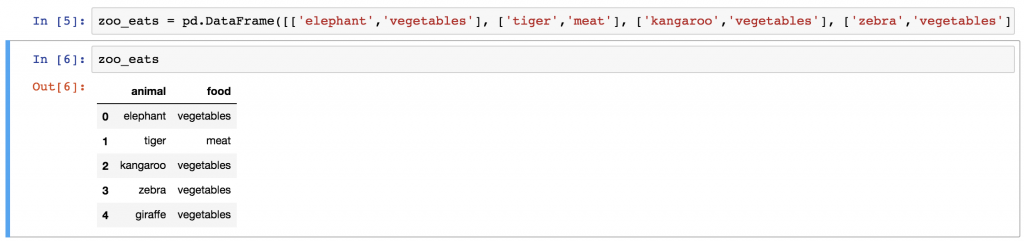
And there is your zoo_eats dataframe!
Okay, now let’s see the pandas merge method:
zoo.merge(zoo_eats)
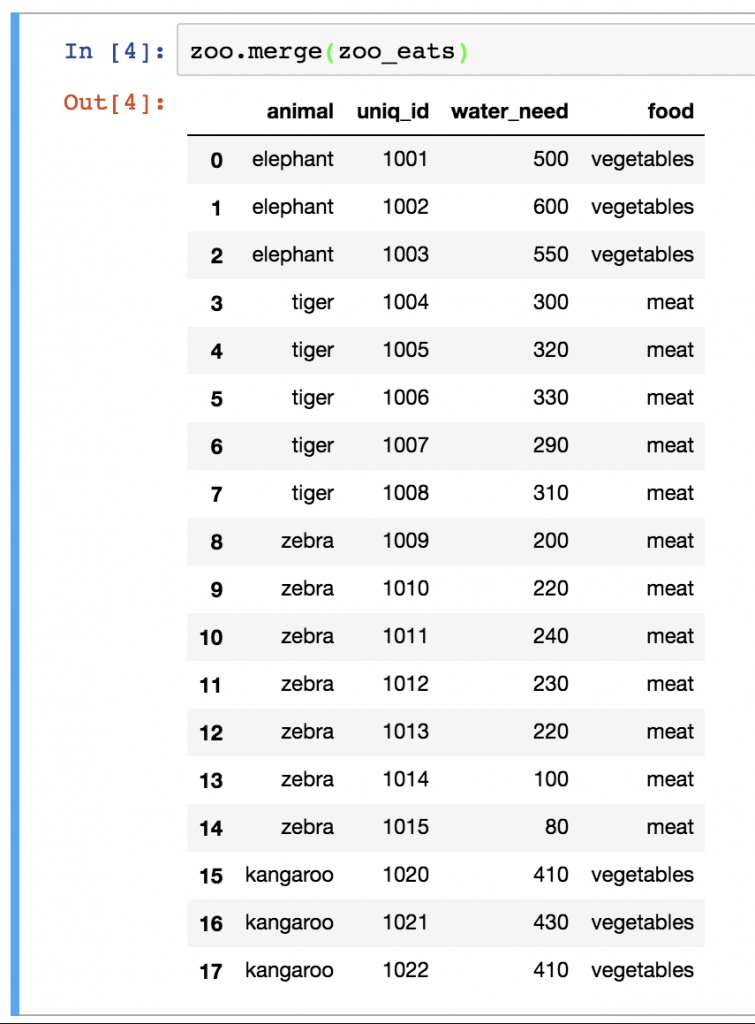
(Oh, hey, where are all the lions? We will get back to that soon, I promise!)
Bamm! Simple, right? Just in case, let’s see what’s happening here:
First, I specified the first dataframe (zoo), then I applied the .merge() pandas method on it and as a parameter I specified the second dataframe (zoo_eats). I could have done this the other way around:
zoo_eats.merge(zoo)
is symmetric to:
zoo.merge(zoo_eats)
The only difference between the two is the order of the columns in the output table. (Just try it!)
Pandas Merge… But how? Inner, outer, left or right?
As you can see, the basic merge method is pretty simple. Sometimes you have to add a few extra parameters though.
One of the most important questions is how you want to merge these tables. In SQL, we learned that there are different JOIN types.
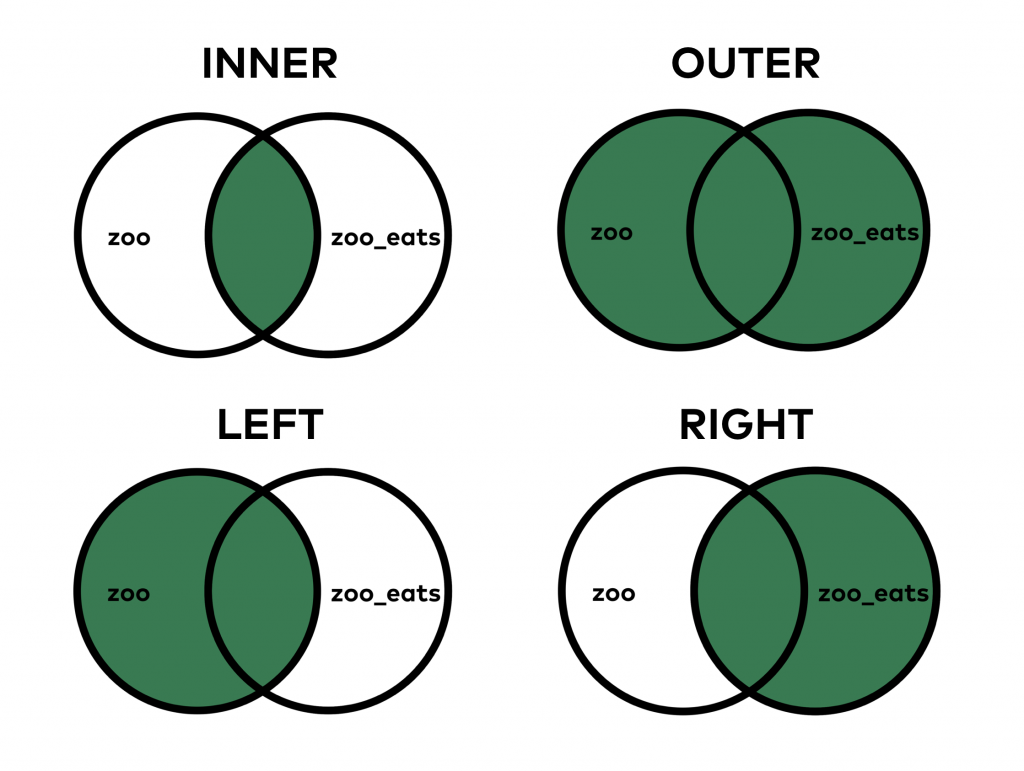
The theory is exactly the same for pandas merge.
When you do an INNER JOIN (that’s the default both in SQL and pandas), you merge only those values that are found in both tables. On the other hand, when you do the OUTER JOIN, it merges all values, even if you can find some of them in only one of the tables.
Let’s see a concrete example: did you realize that there is no lion value in zoo_eats? Or that we don’t have any giraffes in zoo? When we did the merge above, by default, it was an INNER merge, so it filtered out giraffes and lions from the result table. But there are cases in which we do want to see these values in our joined dataframe. Let’s try this:
zoo.merge(zoo_eats, how = 'outer')
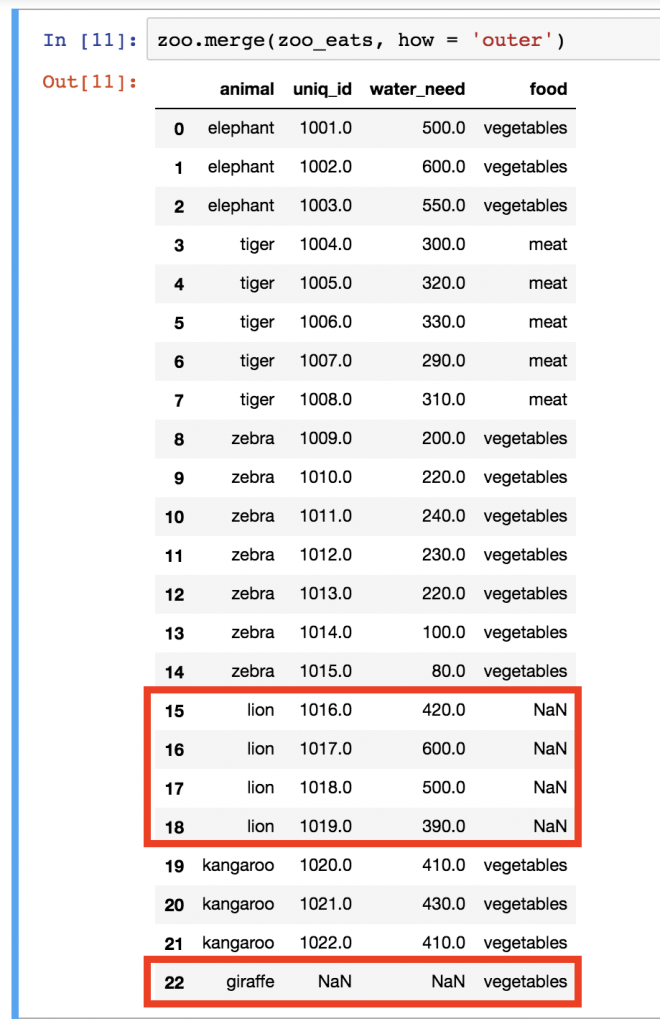
See? Lions came back, the giraffe came back… The only thing is that we have empty (NaN) values in those columns where we didn’t get information from the other table.
In my opinion, in this specific case, it would make more sense to keep lions in the table but not the giraffes… With that, we could see all the animals in our zoo and we would have three food categories: vegetables, meat and NaN (which is basically “no information”). Keeping the giraffe line would be misleading and irrelevant since we don’t have any giraffes in our zoo anyway. That’s when merging with a how = 'left' parameter becomes handy!
Try this:
zoo.merge(zoo_eats, how = 'left')
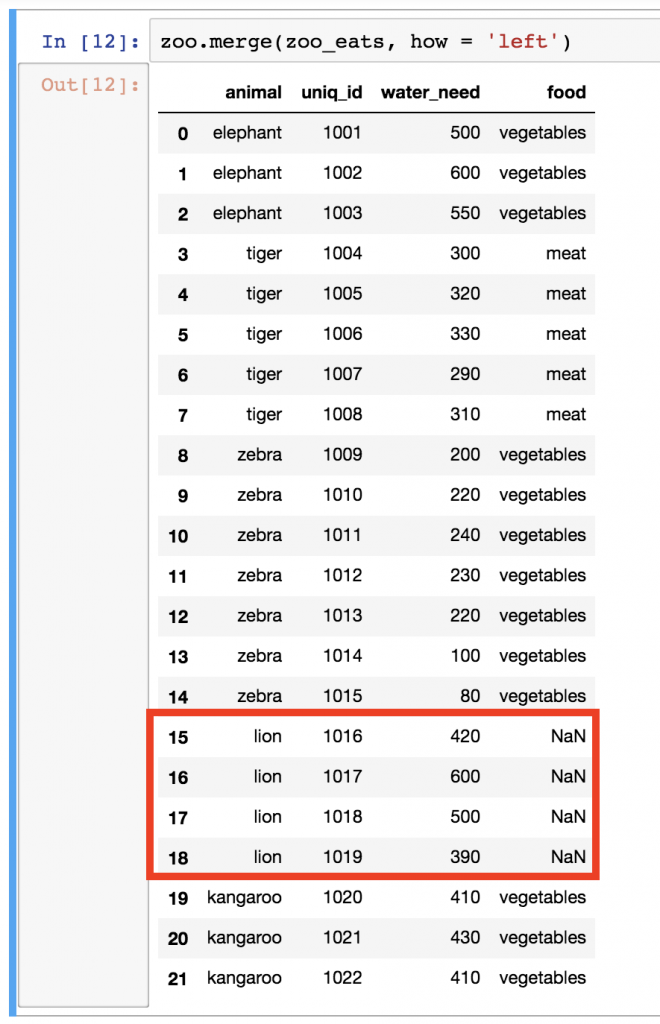
Everything you do need, and nothing you don’t… The how = 'left' parameter brought all the values from the left table (zoo) but brought only those values from the right table (zoo_eats) that we have in the left one, too. Cool!
Let’s take a look at our merge types again:
Note: a common question I get is “What’s the “safest” way of merging? Should you go with inner, outer, left or right, as a best practice?” My answer is: there is no categorical answer for this question. While inner is the default merge type in pandas, whether you should go with that, or change to outer, left or right, really depends on the task itself.
Pandas Merge. On which column?
For doing the merge, pandas needs the key-columns you want to base the merge on (in our case it was the animal column in both tables). If you are not so lucky that pandas automatically recognizes these key-columns, you have to help it by providing the column names. That’s what the left_on and right_on parameters are for!
For example, our latest left merge could have looked like this, as well:
zoo.merge(zoo_eats, how = 'left', left_on = 'animal', right_on = 'animal')
Note: again, in the previous examples pandas automatically found the key-columns anyway… but there are many cases when it doesn’t. So keep left_on and right_on in mind.
Okay, pandas merge was quite complex; the rest of the methods I’ll show you here will be much easier.
Sorting in pandas
Sorting is essential. The basic sorting method is not too difficult in pandas. The function is called sort_values() and it works like this:
zoo.sort_values('water_need')

Note: in the older version of pandas, there is a sort() function with a similar mechanism. But it has been replaced with sort_values() in newer versions, so learn sort_values() and not sort().
The only parameter I used here was the name of the column I want to sort by, in this case the water_need column. Quite often, you have to sort by multiple columns, so in general, I recommend using the by keyword for the columns:
zoo.sort_values(by = ['animal', 'water_need'])

Note: you can use the by keyword with one column only, too, like zoo.sort_values(by = ['water_need']).
sort_values sorts in ascending order, but obviously, you can change this and do descending order as well:
zoo.sort_values(by = ['water_need'], ascending = False)
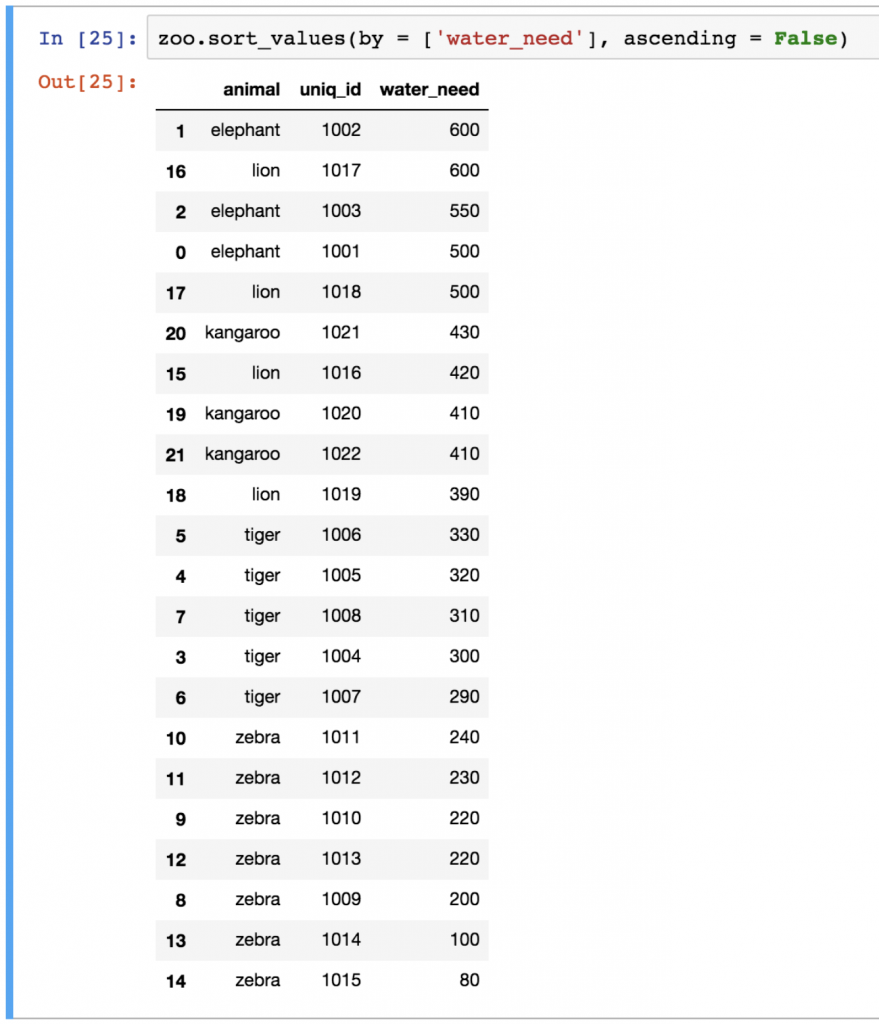
Am I the only one who finds it funny that defining descending is possible only as ascending = False? Whatever. 🙂
Reset_index
(This section is especially important for you if you participate in the Junior Data Scientist’s First Month video course.)
What a mess with all the indexes after that last sorting, right?
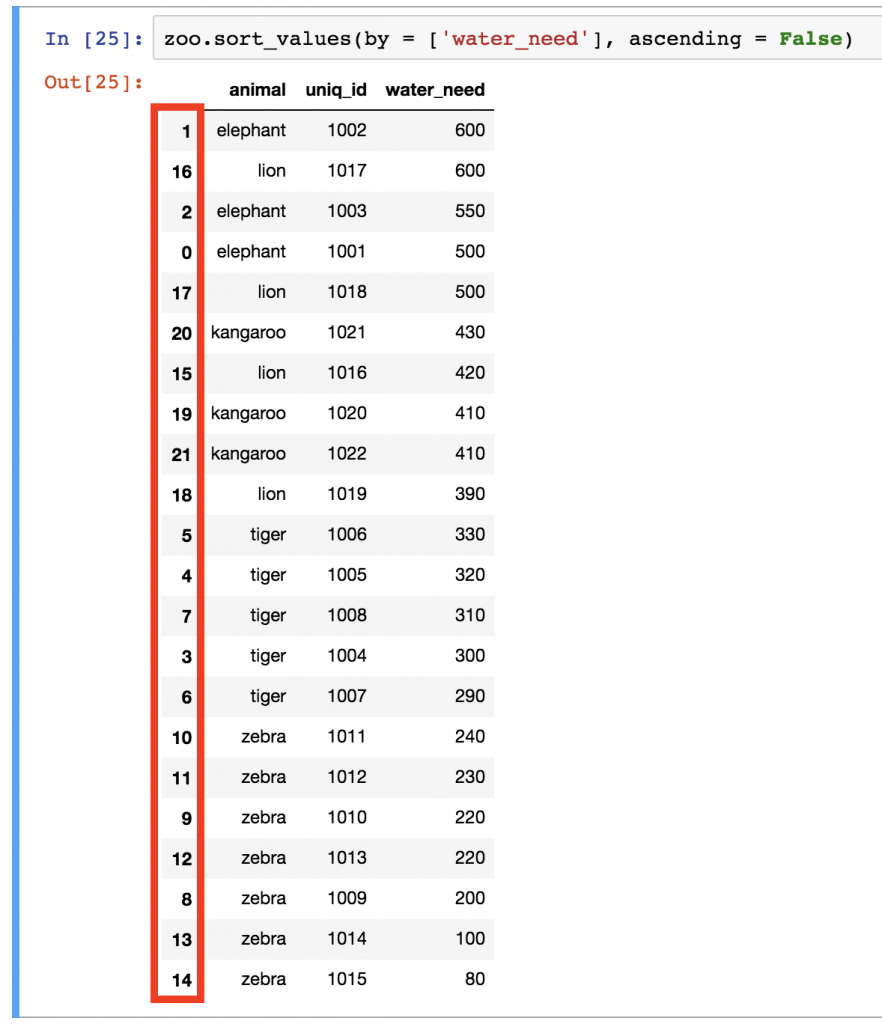
It’s not just that it’s ugly… wrong indexing can mess up your visualizations (more about that in my matplotlib tutorials) or even your machine learning models.
The point is: in certain cases, when you have done a transformation on your dataframe, you have to re-index the rows. For that, you can use the reset_index() method. For instance:
zoo.sort_values(by = ['water_need'], ascending = False).reset_index()
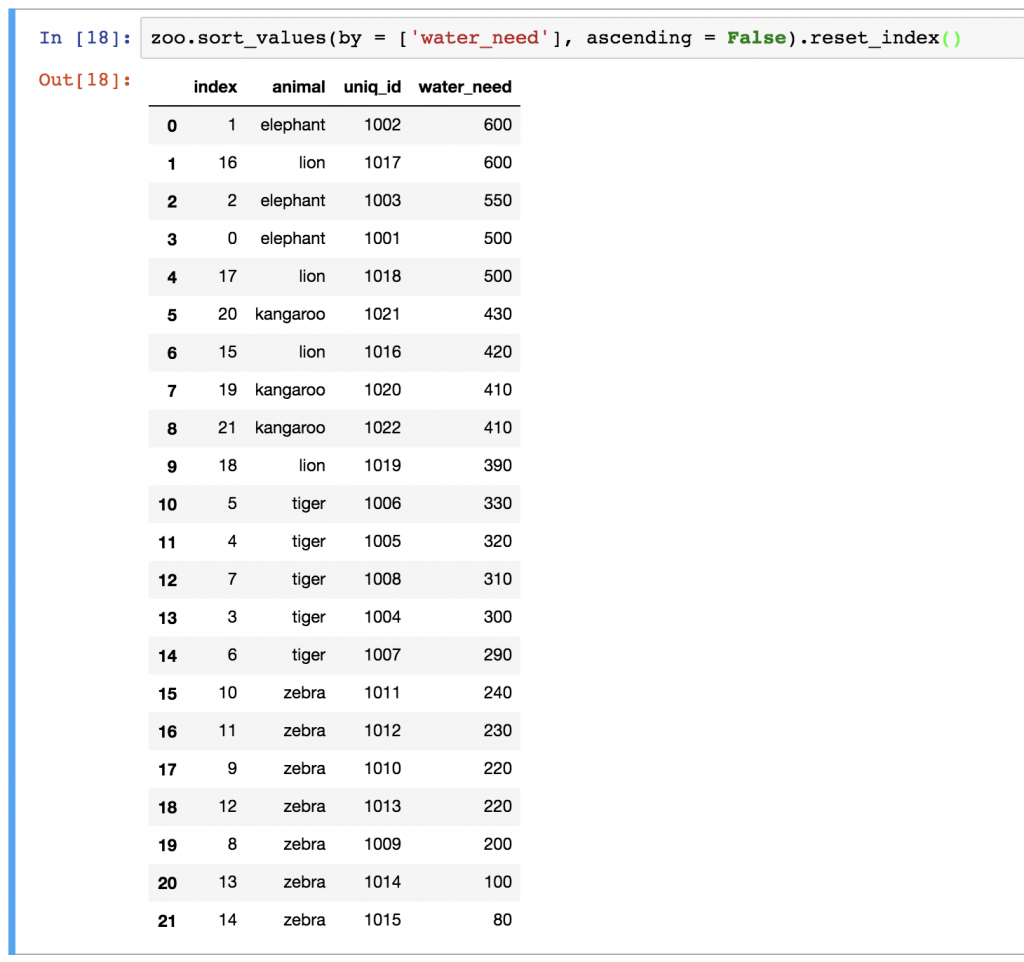
Nicer? For sure!
As you can see, our new dataframe kept the old indexes, too. If you want to remove them, just add the drop = True parameter:
zoo.sort_values(by = ['water_need'], ascending = False).reset_index(drop = True)
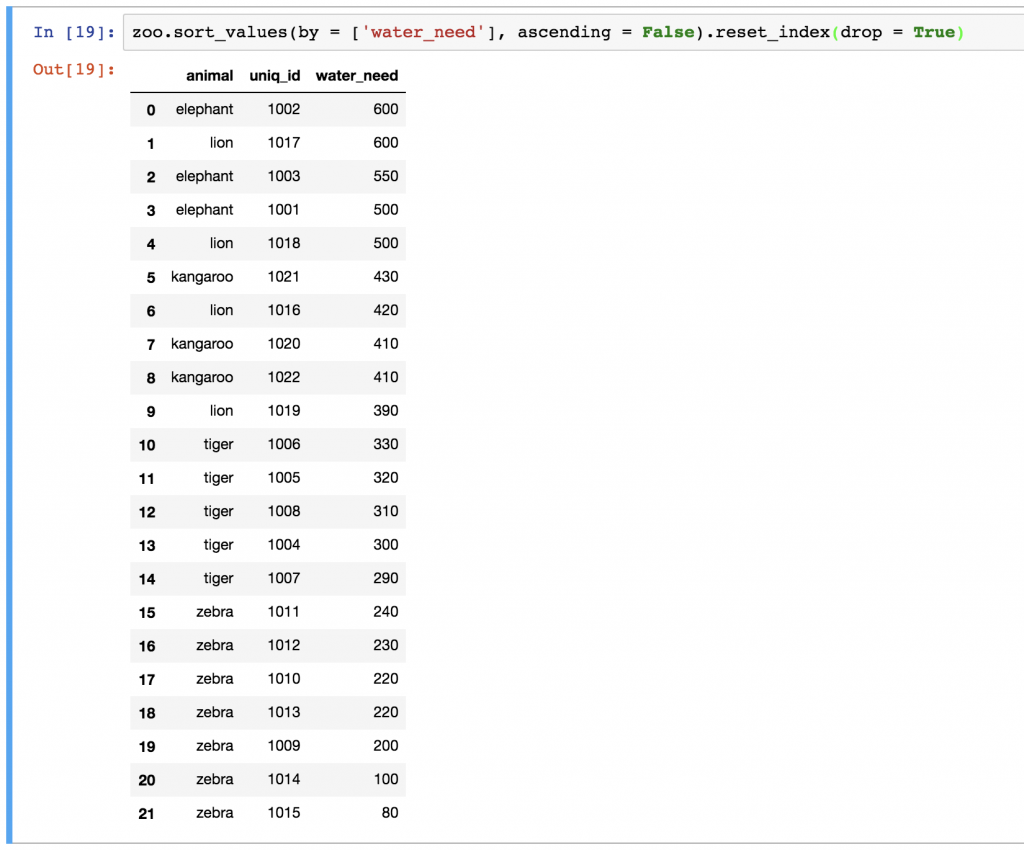
Fillna
(Note: fillna is basically fill + na in one word. If you ask me, it’s not the smartest name, but this is what we have.)
Let’s rerun the left-merge method that we have used above:
zoo.merge(zoo_eats, how = 'left')
Remember? These are all our animals. The problem is that we have NaN values for lions. NaN itself can be really distracting, so I usually like to replace it with something more meaningful. In some cases, this can be a 0 value, or in other cases a specific string value, but this time, I’ll go with unknown. Let’s use the fillna() function, which basically finds and replaces all NaN values in our dataframe:
zoo.merge(zoo_eats, how = 'left').fillna('unknown')
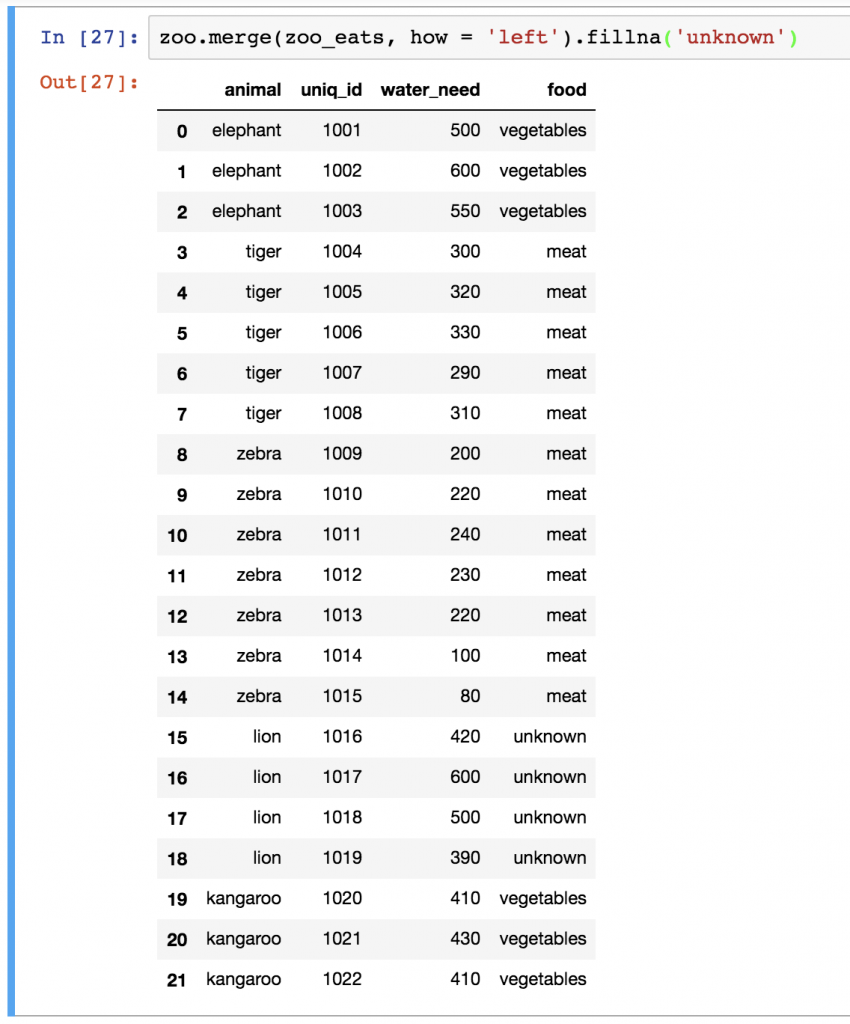
Note: since we know that lions eat meat, we could have written zoo.merge(zoo_eats, how = 'left').fillna('meat'), as well.
Test yourself
Okay, you’ve gotten through the article! Great job!
Here’s your final test task!
Let’s get back to our article_read dataset.
(Note: Remember, this dataset holds the data of a travel blog. If you don’t have the data yet, you can download it from here. Or you can go through the whole download, open, store process step by step by reading the first episode of this pandas tutorial.)
Download another dataset, too: blog_buy. You can do that by running these two lines in your Jupyter Notebook:
!wget 46.101.230.157/dilan/pandas_tutorial_buy.csvblog_buy = pd.read_csv('pandas_tutorial_buy.csv', delimiter=';', names = ['my_date_time', 'event', 'user_id', 'amount'])
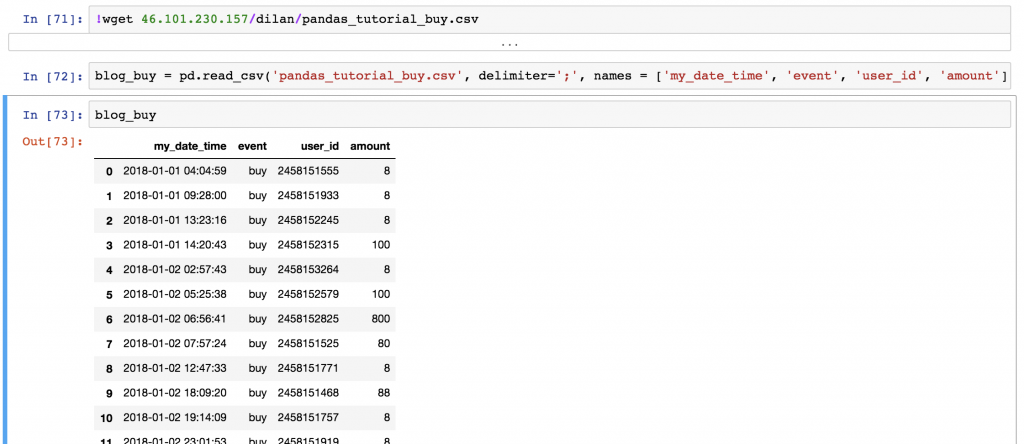
The article_read dataset shows all the users who read an article on the blog, and the blog_buy dataset shows all the users who bought something on the very same blog between 2018-01-01 and 2018-01-07.
I have two questions for you:
- TASK #1: What’s the average (mean) revenue between
2018-01-01and2018-01-07from the users in thearticle_readdataframe? - TASK #2: Print the top 3 countries by total revenue between
2018-01-01and2018-01-07! (Obviously, this concerns the users in thearticle_readdataframe again.)
SOLUTION for TASK #1
The average revenue is: 1.0852
Here’s the code:
step_1 = article_read.merge(blog_buy, how = 'left', left_on = 'user_id', right_on = 'user_id') step_2 = step_1.amount step_3 = step_2.fillna(0) result = step_3.mean() result
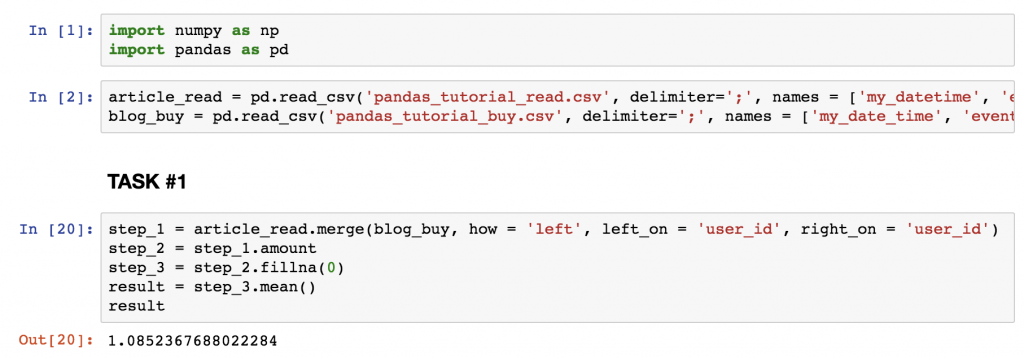
Note: for ease of understanding, I broke this down into “steps” – but you could also bring all these functions into one line.
A short explanation:
- (On the screenshot, at the beginning, I included the two extra cells where I import pandas and numpy, and where I read the csv files into my Jupyter Notebook.)
- In step_1, I merged the two tables (
article_readandblog_buy) based on theuser_idcolumns. I kept all the readers fromarticle_read, even if they didn’t buy anything, because0s should be counted in to the average revenue value. And I removed everyone who bought something but wasn’t in thearticle_readdataset (that was fixed in the task). So all in all that led to a left join. - In step_2, I removed all the unnecessary columns, and kept only
amount. - In step_3, I replaced
NaNvalues with0s. - And eventually I did the
.mean()calculation.
SOLUTION for TASK #2
The code is:
step_1 = article_read.merge(blog_buy, how = 'left', left_on = 'user_id', right_on = 'user_id')
step_2 = step_1.fillna(0)
step_3 = step_2.groupby('country').sum()
step_4 = step_3.amount
step_5 = step_4.sort_values(ascending = False)
step_5.head(3)
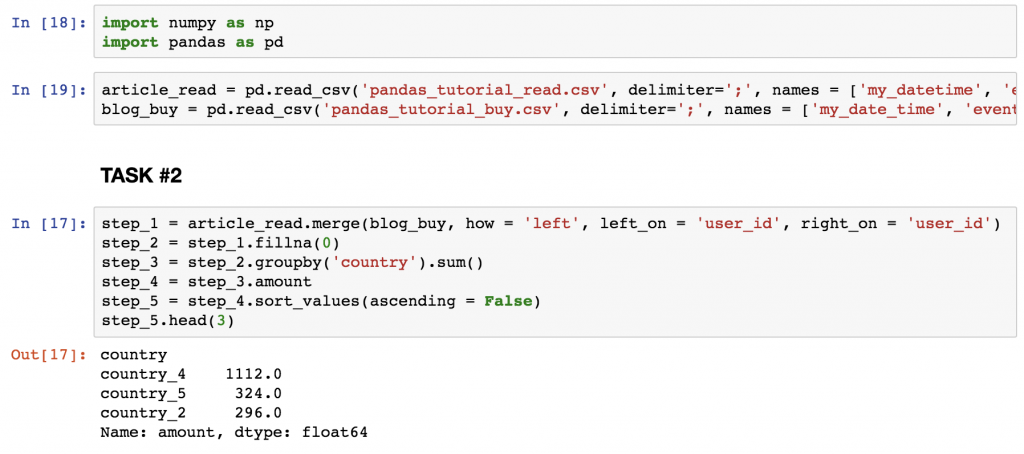
And find the top 3 countries on the screenshot below.
A short explanation:
- At step_1, I used the same merging method that I used in TASK #1.
- At step_2, I filled up all the
NaNvalues with0s. - At step_3, I summarized the numerical values by countries.
- At step_4, I took away all columns but
amount. - And at step_5, I sorted the results in descending order, so I can see my top list!
- Finally, I printed the first 3 lines only.
Solved!
Conclusion
This was the third episode of my pandas tutorials where I showed you my favorite data formatting tools in pandas: merge, sort, reset_index and fillna. If you want to see more, take a look at this cool pandas cheat sheet .
And continue here, with episode #4 which is about plotting histograms with Python + pandas.
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester