
Combining tables is a key component in data science and analytics. And SQL is really good at it! Of course each case is different, but I run into data science tasks all the time in which joining two multi-million-row data tables took ~20-30 minutes in Python or bash… and not more than ~10-20 seconds in SQL. I’m not saying I couldn’t have done those tasks in Python or bash at all… But for sure SQL JOIN was the easiest and fastest solution!
So let’s learn how to use SQL JOIN to step up your analytics projects!
Note: to get the most out of this article, you should not just read it, but actually do the coding part with me! So if you are on the phone, I suggest saving this article and continuing on your computer!
But before we start…
… I highly recommend going through these articles first – if you haven’t done so yet:
- Set up your own data server to practice: How to install Python, SQL, R and Bash (for non-devs)
- Install SQL Workbench to manage your SQL stuff better: How to install SQL Workbench for postgreSQL
- SQL for Data Analysis ep1 (SQL basics)
- SQL for Data Analysis ep2 (SQL WHERE clause)
- SQL for Data Analysis ep3 (SQL functions and GROUP BY)
- SQL for Data Analysis ep4 (SQL best practices)
What is SQL JOIN?
What does it mean to JOIN two tables? Here’s a simple example.
Let’s say we have these two datasets:
TABLE #1
| INVENTION | INVENTOR |
|---|---|
| Rubik’s Cube | Erno Rubik |
| Carburetor | Janos Csonka |
| Carburetor | Donat Banki |
| Ballpen | Laszlo Biro |
| Dynamo | Anyos Jedlik |
TABLE #2
| INVENTOR | PROFESSION |
|---|---|
| Erno Rubik | architect |
| Janos Csonka | engineer |
| Donat Banki | engineer |
| Laszlo Biro | journalist |
| Anyos Jedlik | engineer |
In TABLE #1 we have inventors and inventions and in TABLE #2 we have the same inventors and their original professions. Let’s say we want to see which inventions was invented by an inventor with what original profession. To query that, we have to merge the two tables, based on the column that shows up in both: inventor.
And this is what SQL JOIN is good for. After joining the two tables, this is what we will get:
| INVENTION | INVENTOR | PROFESSION |
|---|---|---|
| Rubik’s Cube | Erno Rubik | architect |
| Carburetor | Janos Csonka | engineer |
| Carburetor | Donat Banki | engineer |
| Ballpen | Laszlo Biro | journalist |
| Dynamo | Anyos Jedlik | engineer |
Now we can finally see that the Rubik’s Cube was invented by an architect!
(Extra (not SQL-related) task: find out what these 5 inventions have in common!)
Perfect, but what does this look like in practice?
Get some data!
To put SQL JOIN into practice, we will get some data first.
Open up SQL Workbench! We are gonna create two new temporary data tables: playlist and toplist. Run these two queries in SQL Workbench one by one.
CREATE TABLE playlist ( artist VARCHAR, song VARCHAR);
CREATE TABLE toplist ( tophit VARCHAR, play INT);
The new SQL tables have been created. Now, load some data into them!
Run these two queries one by one in your SQL Workbench:
INSERT INTO playlist (artist,song) VALUES
('ABBA','Dancing Queen'),
('ABBA','Gimme!'),
('ABBA','The Winner Takes It All'),
('ABBA','Mamma Mia'),
('ABBA','Take a Chance On Me'),
('Tove Lo','Cool Girl'),
('Tove Lo','Stay High'),
('Tove Lo','Talking Body'),
('Tove Lo','Habits'),
('Tove Lo','True Disaster'),
('Avicii','Wake Me Up'),
('Avicii','Waiting For Love'),
('Avicii','The Nights'),
('Avicii','Hey Brother'),
('Avicii','Levels'),
('Zara Larsson','Lush Life');
INSERT INTO toplist (tophit,play) VALUES
('Dancing Queen',95145796),
('Gimme!',32785696),
('The Winner Takes It All',34458597),
('Mamma Mia',47901900),
('Take a Chance On Me',30654536),
('Cool Girl',227055115),
('Stay High',263901766),
('Talking Body',272334711),
('Habits',214685822),
('True Disaster',27028538),
('Wake Me Up',520259542),
('Waiting For Love',399906192),
('The Nights',278063930),
('Hey Brother',321270703),
('Levels',206004691),
('Despacito',519689490);
Note: This is actually real data that I pulled from Spotify when I wrote this article.
Let’s see whether everything works fine… Query the tables with:
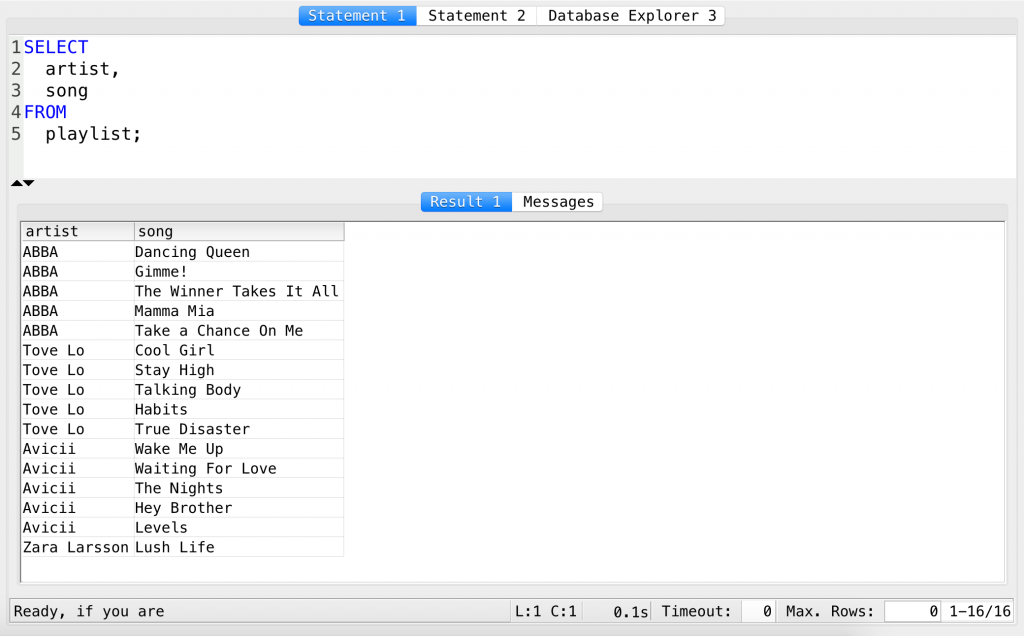
SELECT artist, song FROM playlist;
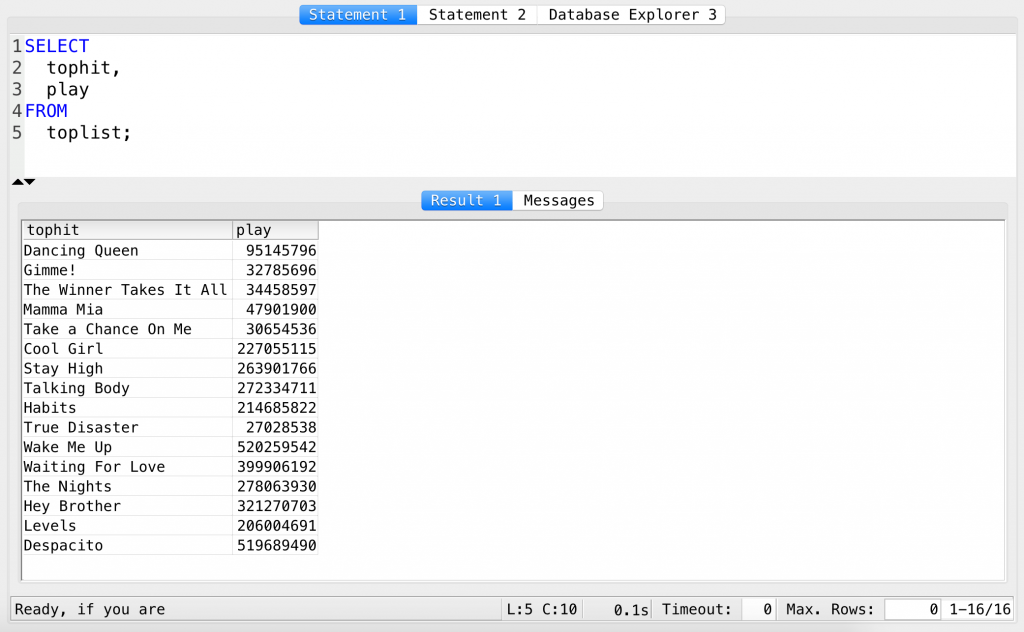
SELECT tophit, play FROM toplist;
Note: Why did I use the column names and why didn’t I use SELECT * instead? Find out from my SQL best practices article!
Ah, cool, some nice songs from some nice artists, that people have played a lot already…
An important note: when you close SQL Workbench, these temporary data tables will disappear. If you do so, you have to CREATE them again and then INSERT data into them! If you want to keep them, just type and run this command in SQL Workbench:
COMMIT;
SQL JOIN – the basics
Let’s perform our first SQL JOIN!
SELECT * FROM toplist JOIN playlist ON tophit = song;
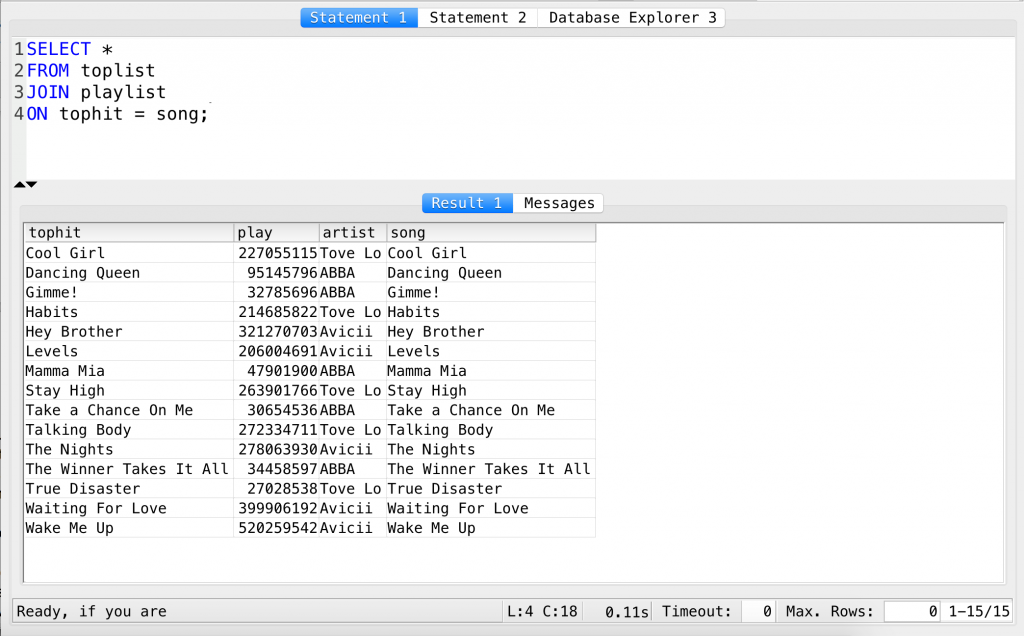
First of all, take a look at the results!
We have four columns, two plus two from the two tables. Makes sense, right?
The values in the song and tophit columns are the same. In fact, that was the column that we have joined on, so this is not a big surprise. But hey, we have just merged two tables!
Let’s see what has happened code-wise:
SELECT *–» We want to select every column…FROM toplist–» …from thetoplistdata table…JOIN playlist–» …but we also want to merge theplaylisttable to the thetoplisttable…ON tophit = song;–» …and we want to connect those lines, where the value of thetophitcolumn is matching with the value of thesongcolumn.
Not that complicated… Yet. 🙂
Now there is one important question here…
If you haven’t realized it yet: there is one song (Zara Larsson: Lush Life) that exists in the playlist table, but not in the toplist table. And there is another one (Despacito, 519689490) that exists in the toplist table, but not in the playlist table. I did this on purpose, because I wanted to demonstrate what happens when you have to deal with partially missing data, which actually happens quite often in real-life data science projects.
To understand that, take a look at this Venn-diagram. It shows what happens with the data after JOIN-ing the two SQL tables.
When you use the default JOIN, your query will manage your data like this:
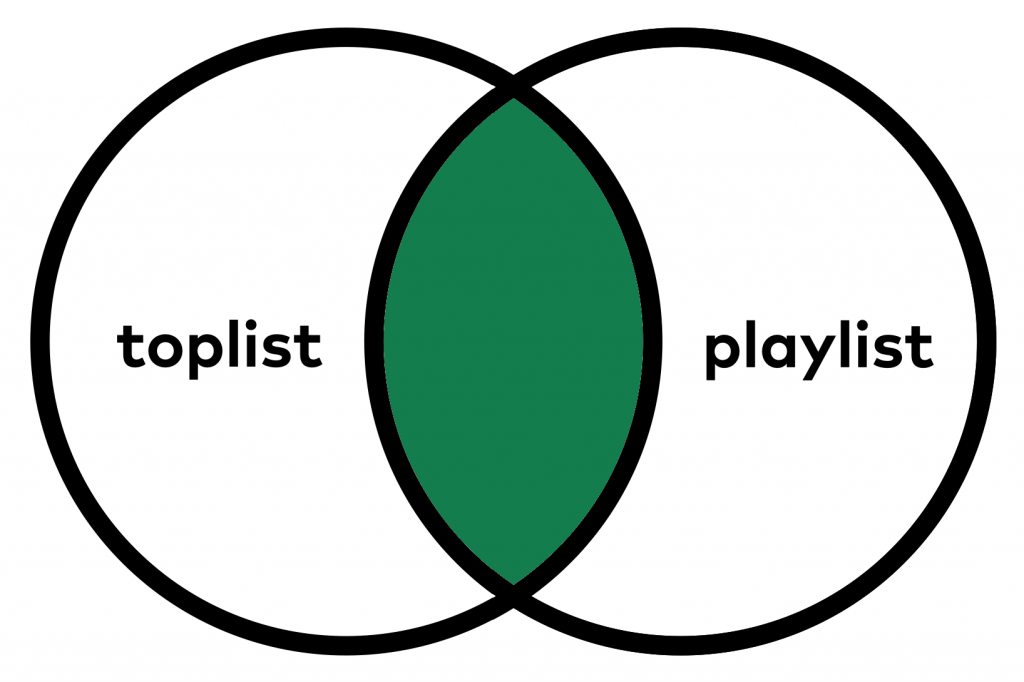
As you can see: the default SQL JOIN keeps only the data that occurs in both tables. So Despacito and Zara Larsson were removed.
This method is called INNER JOIN but since this is what we use most often, in SQL it has been implemented as the default behaviour of the JOIN keyword.
SQL JOIN – same query, better syntax
Remember that in the SQL best practices article I strongly recommended not to use * in a SELECT statement… It’s better to use the actual names of the columns instead. And it’s even more important when you use JOINs in your queries!
Instead of this query…
SELECT * FROM toplist JOIN playlist ON tophit = song;
…I recommend using this one:
SELECT tophit, play, artist, song FROM toplist JOIN playlist ON tophit = song;
And to be honest, this is still not the most bulletproof syntax.
The problem is that when you look at this code, you can’t instantly see what columns belong to which table. Thus I like to add the table names also to the column names. It works with dot notation and it’s really simple.
For instance:
If the tophit column is in the toplist table, then instead of tophit, I’ll write: toplist.tophit.
If you apply this to all column names in the above query:
SELECT toplist.tophit, toplist.play, playlist.artist, playlist.song FROM toplist JOIN playlist ON toplist.tophit = playlist.song;
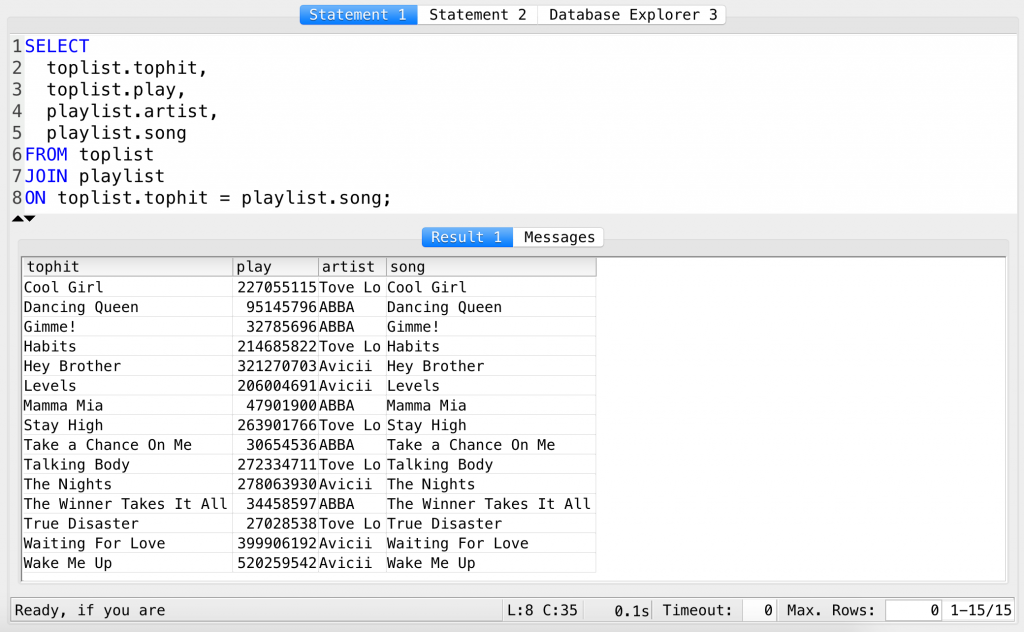
Much better. But one last small tweak! The playlist.song and the toplist.tophit columns are actually the same. We don’t need both of them… so I’ll remove one:
SELECT toplist.tophit, toplist.play, playlist.artist FROM toplist JOIN playlist ON toplist.tophit = playlist.song;
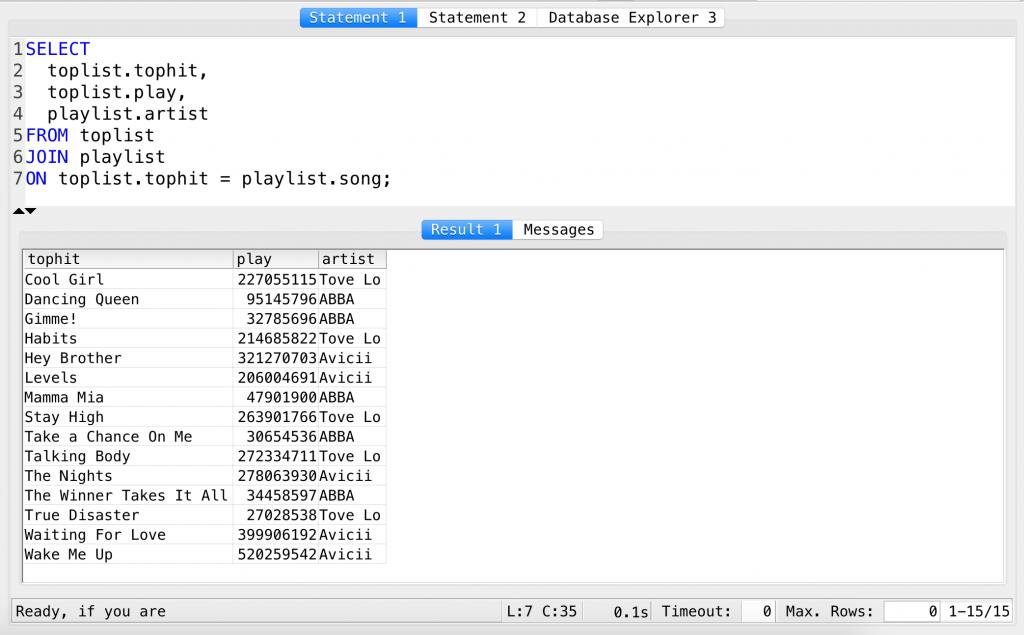
Now this is finally a pretty decent SQL JOIN.
FULL JOIN
But you might ask: ”What should we do to keep Despacito and Zara Larsson in the data set, even though they don’t show up in both data tables?” And I’d answer: great question!
Get back to our Venn-diagram… This time, this is what we want to achieve:
This version of the SQL JOINs is called FULL JOIN, and to execute it, you should change only one tiny thing in our previous query: add the FULL keyword before the JOIN keyword.
SELECT toplist.tophit, toplist.play, playlist.artist, playlist.song FROM toplist FULL JOIN playlist ON toplist.tophit = playlist.song;
Boom! The magic has happened!
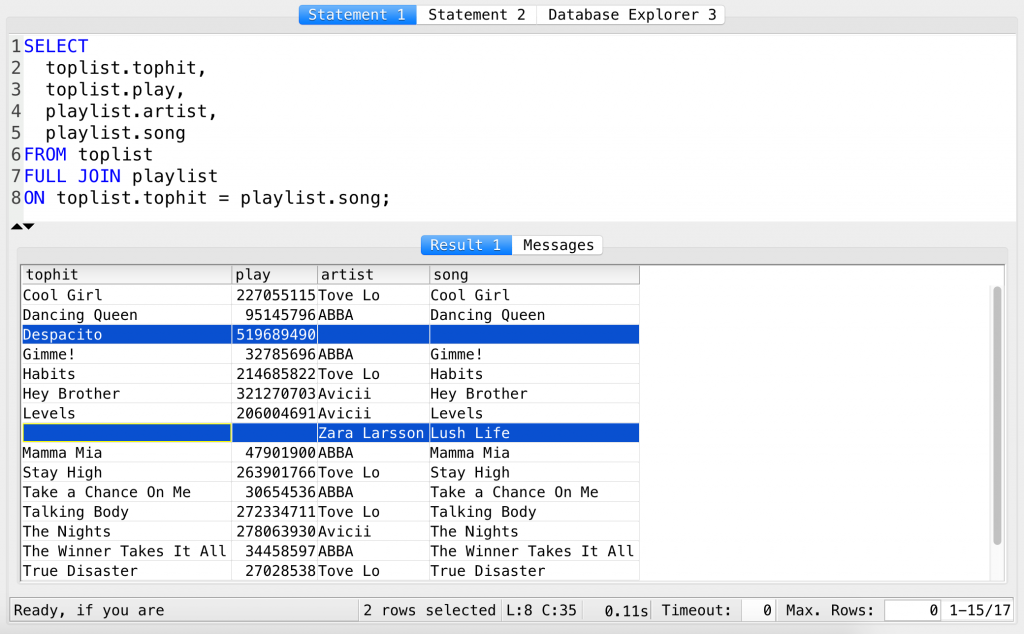
As you can see, Zara Larsson and Despacito are there, but those fields that don’t have data, stay empty. These empty fields are called NULL values in SQL. I have already mentioned briefly NULL and its importance (in the SQL functions article) but I’ll get back to that in more detail later!
However, now you know: the fact that a given value doesn’t exist in both data tables, doesn’t mean that you can’t JOIN them. You can with a FULL JOIN, but if you do so, the cells of the missing values will stay empty.
LEFT JOIN AND RIGHT JOIN
And this brings us right to the next question.
What if we want to apply the concept of FULL JOIN — but keeping the missing values only from one of the SQL tables?
Back to the Venn-diagram! Either this…
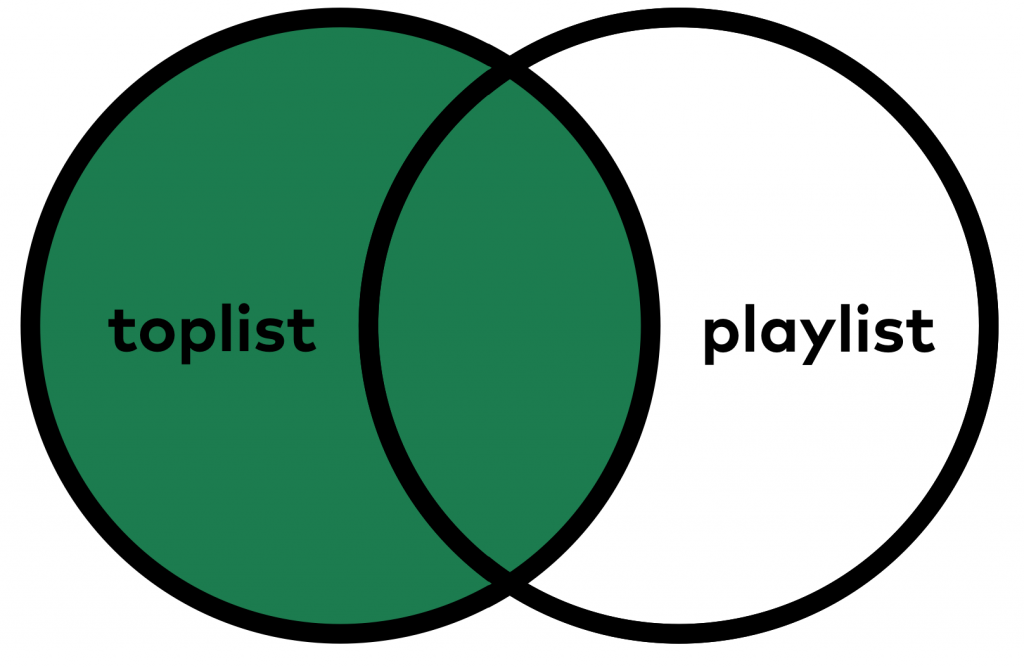
… or this:
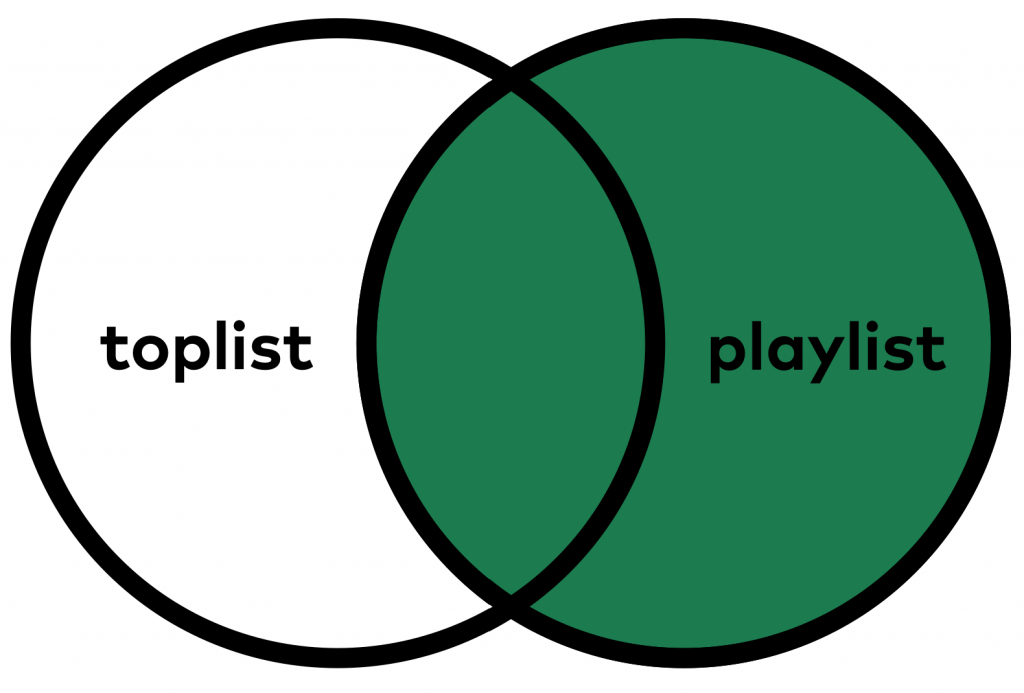
Before I reveal the the “big secret,” I’d like to emphasize that this problem occurs quite often in real data projects too.
E.g. let’s say, you are running an A/B test in which you have two data tables.
TABLE #1
| USER | BUCKET |
|---|---|
| user1 | A |
| user2 | B |
| user3 | A |
| user4 | B |
TABLE #2
| USER | TIMESTAMP |
|---|---|
| user1 | 2018-02-01 19:00:00.000 |
| user2 | 2018-02-01 19:32:11.000 |
| user4 | 2018-02-01 19:44:54.000 |
| user5 | 2018-02-01 19:48:23.000 |
| user1 | 2018-02-01 19:59:01.000 |
| user5 | 2018-02-01 20:01:10.000 |
| user2 | 2018-02-01 20:04:32.000 |
| user4 | 2018-02-01 20:09:54.000 |
| user1 | 2018-02-01 20:12:32.000 |
You want to include only 80% of your audience (e.g. user1, user2, user3, user4 — but not user5) in your A/B test, and you put these selected users into a table with the info about which bucket (A or B) they belong to.
You have another table that works as a usage log (see more here: data collection) and collects the feature usage for all users (user1, user2, user3, user4 and also user5).
To evaluate your A/B test, you have to combine the two tables. You want to keep all users from TABLE #1 (even if they didn’t use the feature, ergo didn’t show up in the other table at all — like user3), but you don’t want to keep the users who showed up only in the second table (used the feature, but not part of the A/B test — like user5).
What do you do?
This:
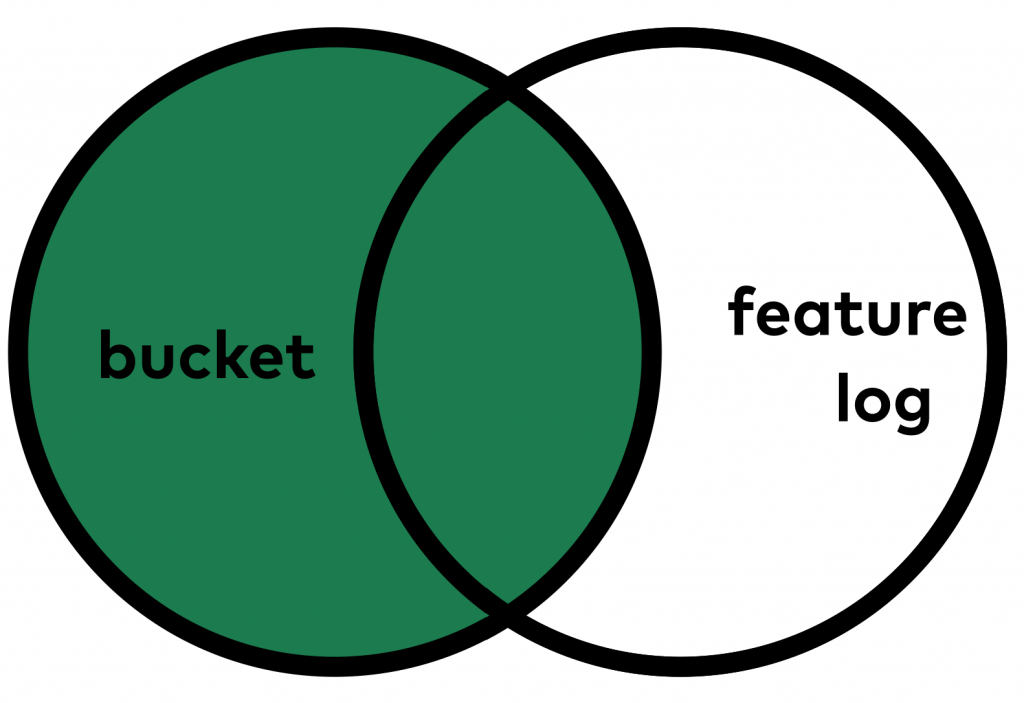
This is called LEFT JOIN. And if you want to perform a LEFT JOIN, you simply have to add a LEFT keyword to your JOIN keyword.
Getting back to our playlist + toplist data sets, try something like this:
SELECT toplist.tophit, toplist.play, playlist.artist FROM toplist LEFT JOIN playlist ON toplist.tophit = playlist.song;
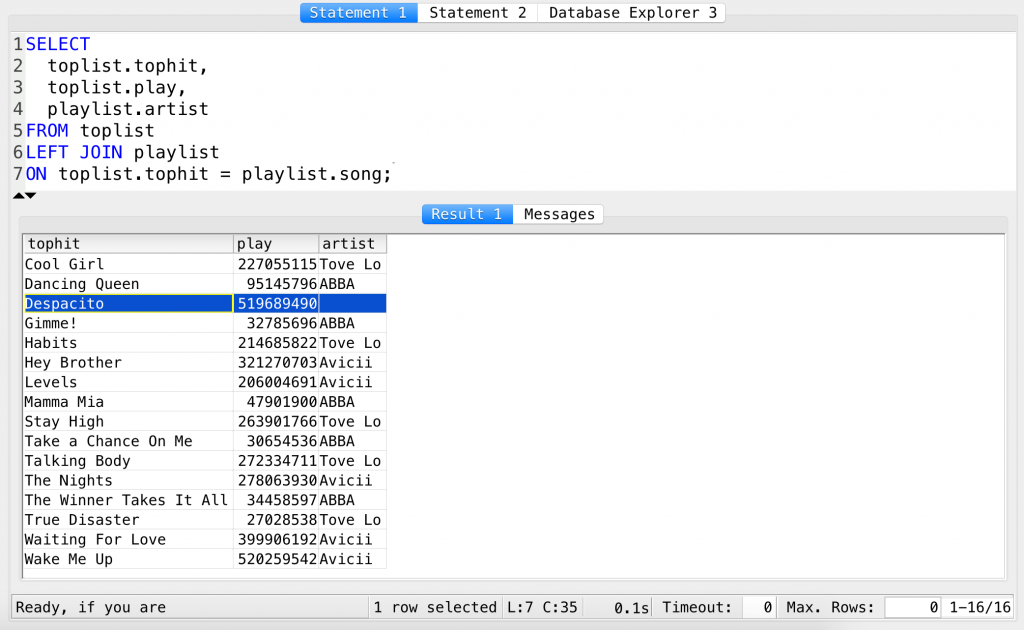
It keeps every line from the toplist table (that’s the LEFT table) even if it doesn’t exist in the playlist table (which is the RIGHT table). But it keeps only those lines from the playlist table that exist in the toplist table too. Good!
If you want to execute the opposite, you should do a RIGHT JOIN instead:
SELECT toplist.tophit, toplist.play, playlist.artist FROM toplist RIGHT JOIN playlist ON toplist.tophit = playlist.song;
Awesome!
Test yourself #1
You now know everything you have to know at this point about SQL JOIN! But the best way of learning is practicing! Here’s an analysis, that you should perform on our playlist and toplist tables:
Given the information in the playlist and toplist data tables:
How many plays does each artist have in total?
.
.
.
Here’s my solution:
SELECT playlist.artist, SUM(toplist.play) FROM playlist FULL JOIN toplist ON playlist.song = toplist.tophit GROUP BY artist;
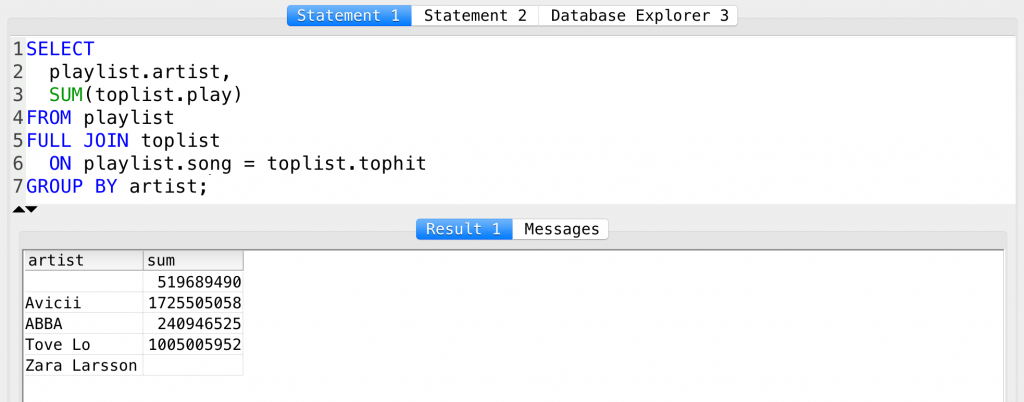
And a short explanation:
SELECT–» We select…playlist.artist,–» the artists from theplaylisttable…SUM(toplist.play)–» and we sum the number of plays from thetoplisttable…FROM playlist–» we actually specify that we will use theplaylisttable…FULL JOIN toplist–» and we also want to merge thetoplisttable (using the empty fields too)…ON playlist.song = toplist.tophit–» theJOINmatches those lines where thesongandtophitcolumns have the same data…GROUP BY artist;–» andGROUP BYrefers to theSUMfunction, above – we want to see the sums by artist.
Test yourself #2
One more test, before I let you go!
Print the top 5 ABBA songs ordered by number of plays!
.
.
.
And the solution is:
SELECT playlist.artist, playlist.song, toplist.play FROM playlist FULL JOIN toplist ON playlist.song = toplist.tophit WHERE playlist.artist = 'ABBA' ORDER BY toplist.play DESC;
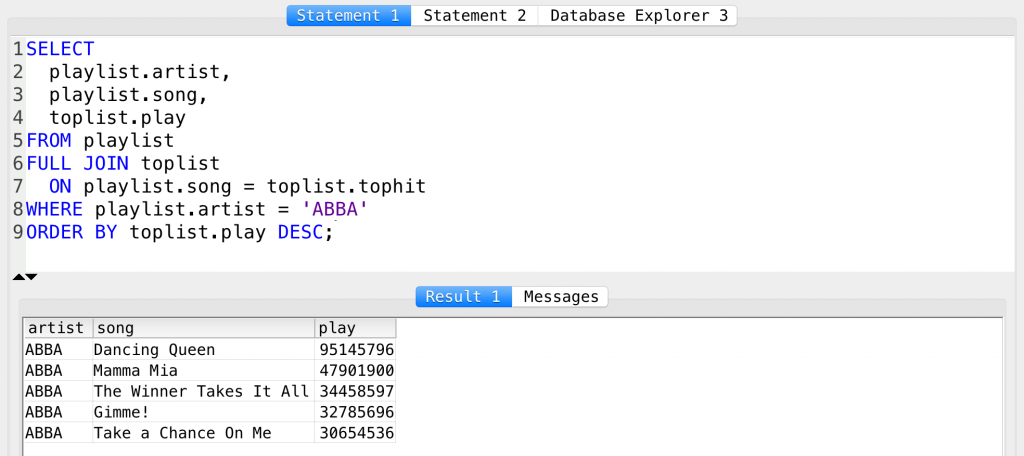
Well, nothing new here. 😉 (But if you need an explanation, just let me know and I’ll give you one!
Conclusion
SQL JOIN is really important and you will use it quite often as a data analyst or scientist. This article has given you a solid base of knowledge. Further down the road you will meet even more advanced applications, but using what you have learned from this article – combined with what you have learned from the previous ones – will cover most cases for now.
And there is only one more article left from my SQL for Data Analysis – Tutorial for Beginners series. In that one, I’ll introduce some intermediate SQL concepts:
- how to write a query-in-a-query — aka. subquery
- SQL
HAVINGand - SQL
CASE!
Continue here: Advanced SQL concepts.
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester