
The first step for every data science project is data collection, that is, getting the actual raw data.
There are two ways to do this:
A) You can pick one or more “smart tools” to use. These services will collect the data for you automatically. You only need to copy-paste a snippet of code into your website and you are ready to go. (E.g. Google Analytics, Hotjar, Google Optimize, CrazyEgg, etc.)
B) You can collect the data for yourself. (E.g. via a javascript code snippet that sends data to a .csv plain text file on your server.) It’s a bit more difficult to implement since it requires some coding skills. But in the long term this solution will serve you much better (and it will be more profitable, too) than version A.
Why? For several reasons that I’ve already written about in this article. But here’s a quick summary:
- You’ll have your own data – you won’t depend on Google Analytics, Hotjar, etc…
- You’ll have one unified data warehouse. No need for integrations, API hacks, and so on.
- There won’t be any limitations on how you can use your data or how you can connect different data points. (E.g. you can’t use your raw data in Google Analytics to implement machine learning models, but you can do it if you have your own database.)
- You can trust your data 100%. (No more black boxes. You know your data since you own it.)
- Data server costs are significantly lower than 3rd party tools’ monthly fees.
Either way you choose, it’s worth understanding how raw data collection works in general — and how you can collect data from your website visitors’ behaviour.
Do it for yourself or using a 3rd party tool… very similar things are happening under the hood!
How does data collection work?
Let’s go with the simplest example!
You have a website and you would like to collect every visitor mouse click for an upcoming data science project.
How do you do that?
First, implement an invisible tracking script (aka “data collection script”) on every clickable element of your site! From that point on, when a website visitor clicks on a specific element (e.g. a link or a button), the click causes two things to happen:
- Obviously, the button will do what it should do. E.g. it will land the user on the page she clicked.
- The data collection script will send a small data package to your data warehouse.
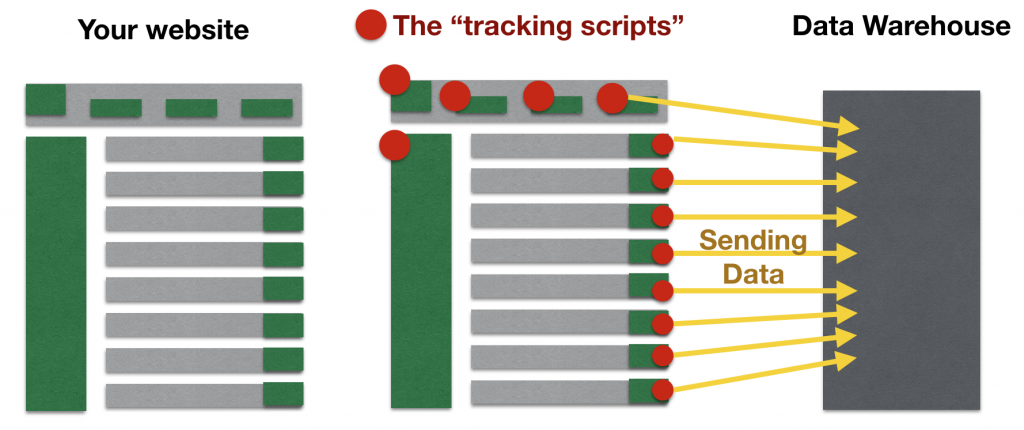
As simple as that.
You could track every user interaction (let’s call them “events“) on your website (or in your mobile app): page views, feature usage, clicks, taps — even mouse movements, if you need to.
A more general illustration to help you imagine what’s happening here:
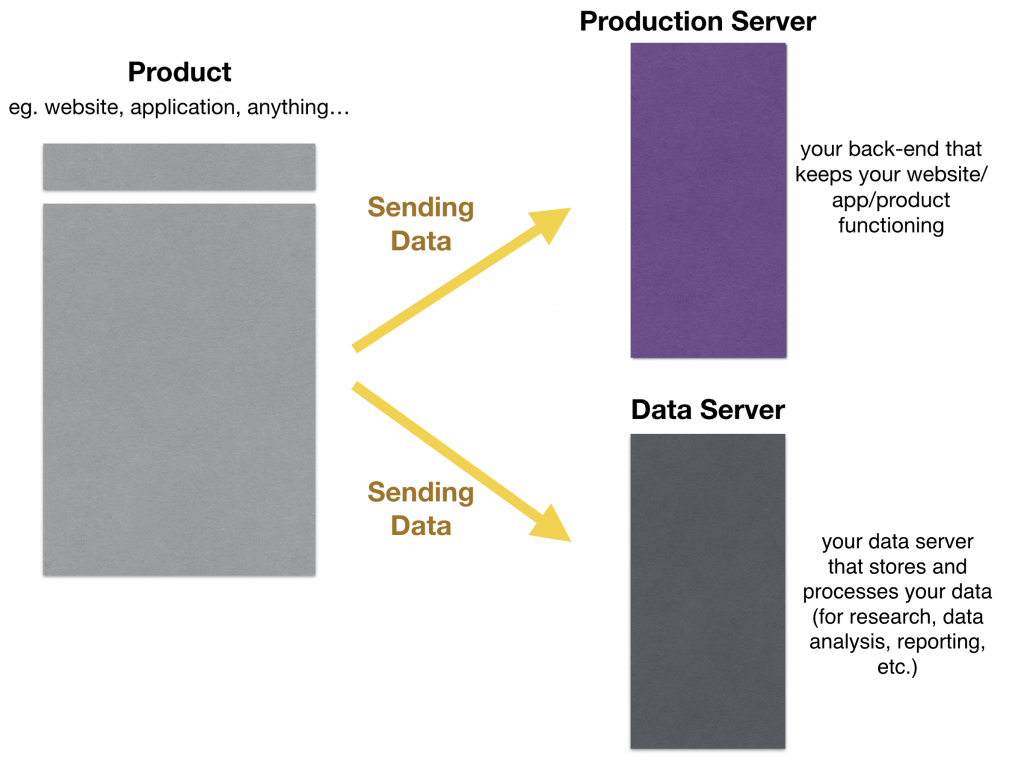
How to store the collected raw data
When the collected raw data hits your data warehouse, it can be stored in different formats.
For startups the best format is the plain text format as it is very flexible. You can imagine this as a simple .txt, .csv or .tsv file with text in it. Many companies follow this model.
But it’s also worth mentioning that many other companies (e.g. almost all multinational companies) like to collect their data directly into SQL databases (or to other similar structured formats).
And there are several other ways to store your data. (Graph databases, noSQL databases, etc.)
In this example I’ll keep it simple and will go with the most common solution: plain text format.
Remember that each event from a website visitor (e.g. a click on your website) creates one line of data using your previously implemented data collection scripts. This line goes into a file on your data server. We call this file with a bunch of events in it a log. You can have more than one log, but almost all of them will have the same format. Something like this:
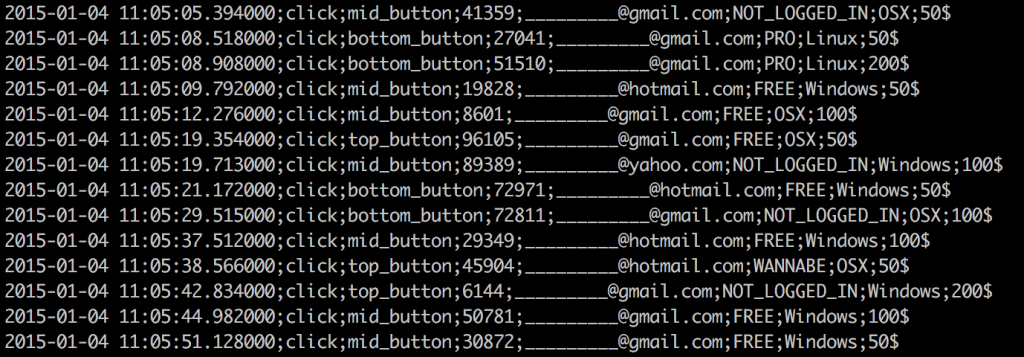
Look messy?
Maybe at first, but go through that column by column! (This is a .csv file which means that the field-separator is a semicolon.)
- the date and the time: when the event happened
- the event itself (in this case: “click”)
- the specifics of the event, e.g. what exact button has been clicked
These are the most basic data points that every event log should contain.
But you can add even more dimensions. Just a few examples:
- visitor’s unique ID (really important!)
- visitor’s email address
- visitor segment (if you have any)
- visitor’s operation system
- last payment amount
- visitor’s device type
- acquisition channel (source, medium, etc.)
- previous site visited
- etc…
What kind of raw data should you collect?
If you run an online business, you can collect and store a virtually infinite amount of data. Infinite vertically (the number of different events you can log) as well as horizontally (the number of dimensions you can collect about one event in one line).
This raises the obvious question: what you should collect and what you shouldn’t.
The principle here is very simple: collect everything you can. Every click, every pageview, every feature usage, everything.
It’s interesting to note that (according to market benchmarks) most startups who follow this collect-everything-principle actually end up using less than 10% of their data. 90% is not even touched by their data scientists!
So why do they collect everything? The answer is: because you can never know what data you will need in the future for your data projects.
Let’s say you want to change a 3-year-old key feature of your online product. You don’t want to mess anything up, so before the change, you will spend some time to understand the exact role of that 3-year-old key feature. For that you will need to analyze your data retrospectively. Whoops, you realize that you didn’t collect any data about it. Game over, you’ve just lost 3-years worth of information… Get it?
If you start thinking about collecting a specific data point when it’s actually needed for a data science project, you are already too late.
And that’s the reason behind the principle “collect everything you can”.
What kind of data should you not collect?
There are some obvious limitations, of course.
But the price of storing data is not one of those. Storing data (in the cloud at least) is very cheap today.
The real limitations are:
- engineering time: The developers need to spend time to implement your tracking scripts. And if you have a complex data warehouse, you will need a full-time person to build and maintain the data infrastructure, too. So if your developers spend more time collecting raw data than implementing new features, fixes or design ideas, then maybe you are too data focused.
- common sense: yes, even if it’s cheap, you can still overload your database if you do foolish things. E.g. if you log every mouse movement of every user every millisecond. You should not do that.
- forgot-to-think-about-it: in most cases, the main reason why people don’t collect particular data points is that they simply forget that they should be collected. It happens, don’t worry. If you want to avoid it, I recommend setting up a workshop in which you sit together and talk through how and what data to collect and why. I wrote more about that in this article.
- legal questions: You should consider legal questions, too. They differ from country to country, so I recommend consulting with a legal professional in your country. (Update in 2018: mind GDPR if you have EU users.)
- And one more comment here. Some countries have strict legal restrictions about data collection, others don’t. Regardless of the regulations: always consider ethics. Never collect data from your website visitors that you wouldn’t want collected about you.
Conclusion
This is how raw data collection works at a high level. Google Analytics, Mixpanel, Crazyegg or your own data warehouses — all are based on these principles. Of course there are small differences, but now you understand what happens in the background and you can be more confident when talking about raw data collection with your co-workers!
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester