
This is the second episode of my web scraping tutorial series. In the first episode, I showed you how you can get and clean the data from one single web page. In this one, you’ll learn how to scrape multiple web pages (3,000+ URLs!) automatically, with one 20-line long bash script.
This is going to be fun!
Note: This is a hands-on tutorial. I highly recommend doing the coding part with me! If you haven’t done so yet, please go through these articles first:
- Web Scraping Tutorial episode #1
- How to install Python, R, SQL and bash to practice data science!
- Introduction to Bash episode #1
- Introduction to Bash episode #2
- Introduction to Bash episode #3
- Introduction to Bash episode #4
- Introduction to Bash episode #5
- Introduction to Bash episode #6
Where did we leave off?
Scraping TED.com…
In the previous article, we scraped a TED talk’s transcript from TED.com.
Note: Why TED.com? As I always say, when you run a data science hobby project, you should always pick a topic that you are passionate about. My hobby is public speaking. But if you are excited about something else, after finishing these tutorial articles, feel free to find any project that you fancy!
This was the code that we used:
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text | sed -n '/Details About the talk/,$p' | sed -n '/Programs &. initiatives/q;p' | head -n-1 | tail -n+2 > proto_text.csv
And this was the result we got:
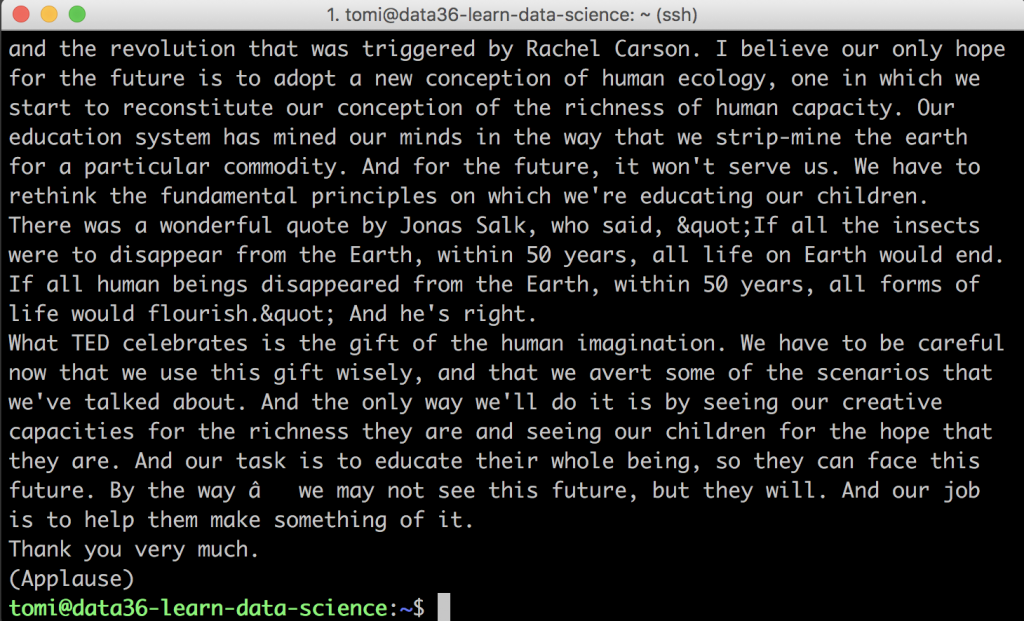
Let’s continue from here…
By the end of this article you won’t scrape only one but all 3,000+ TED talk transcripts. They will be downloaded to your server, extracted and cleaned — ready for data analysis.
I’ll guide you through these steps:
- You’ll extract the unique URLs from TED.com’s html code — for each and every TED talk.
- You’ll clean and save these URLs into a list.
- You’ll iterate through this list with a for loop and you’ll scrape each transcript one by one.
- You’ll download, extract and clean this data by reusing the code we have already created in the previous episode of this tutorial.
So in one sentence: you will scale up our little web scraping project!
We will get there soon… But before everything else, you’ll have to learn how for loops work in bash.
Bash For Loops — a 2-minute crash course
Note: if you know how for loops work, just skip this and jump to the next headline.
If you don’t want to iterate through 3,000+ web pages one by one manually, you’ll have to write a script that will do this for you automatically. And since this is a repetitive task, your best shot is to write a loop.
I’ve already introduced bash while loops.
But this time, you will need a for loop.
A for loop works simply. You have to define an iterable (which can be a list or a series of numbers, for instance). And then you’ll use your for loop to go through and execute one or more commands on each element of this iterable.
Here’s the simplest example:
for i in {1..100}
do
echo $i
done
What does this code do?
It iterates through the numbers between 1 and 100 and it prints them to the screen one by one.
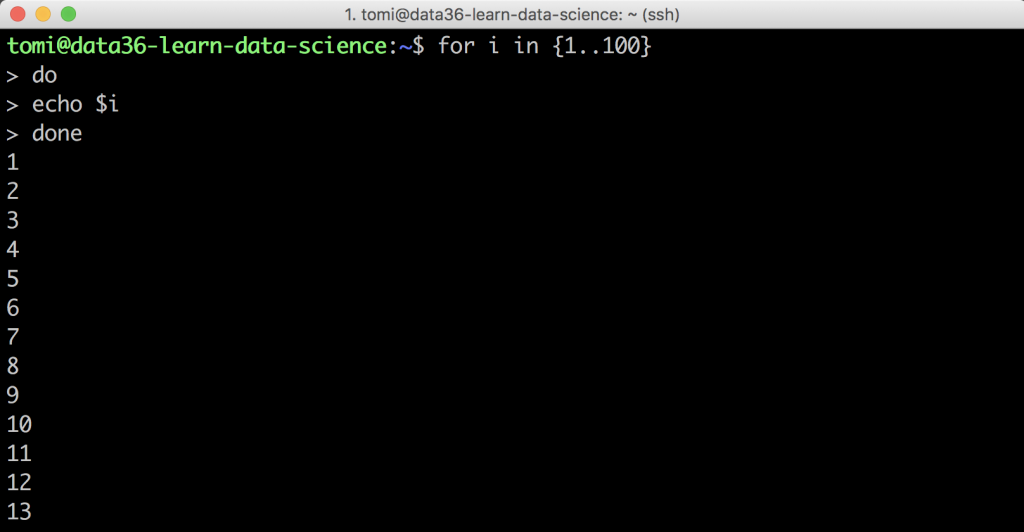
And how does it do that? Let’s see that line by line:
for i in {1..100}
This line is called the header of the for loop. It tells bash what you want to iterate through. In this specific case, it will be the numbers between1and100. You’ll useias a variable. In each iteration, you’ll store the upcoming element of your list in thisivariable. And with that, you’ll be able to refer to this element (and execute commands on it) in the “body” of your for loop.
Note: the variable name doesn’t have to be i… It can be anything:f,g,my_variableor anything else…do
This line tells bash that here starts the body of your for loop.
In the body of the for loop, you’ll add the command(s) that you want to execute on each element of the list.echo $i
The actual command. In this case, it’s the simplest possible example: returning the variable to the screen.done
This closes the body of the for loop.
Note: if you have worked with Python for loops before, you might recognize notable differences. E.g. indentations are obligatory in Python, in bash it’s optional. (It doesn’t make a difference – but we like to use indentations in bash, too, because the script is more readable that way.) On the other hand, in Python, you don’t need the do and done lines. Well, in every data language there are certain solutions for certain problems (e.g. how to indicate the beginning and the end of a loop’s body). Different languages are created by different people… so they use different logic. It’s like learning English and German. You have to learn different grammars to speak different languages. It’s just how it is…
By the way, here’s a flowchart to visualize the logic of a for loop:
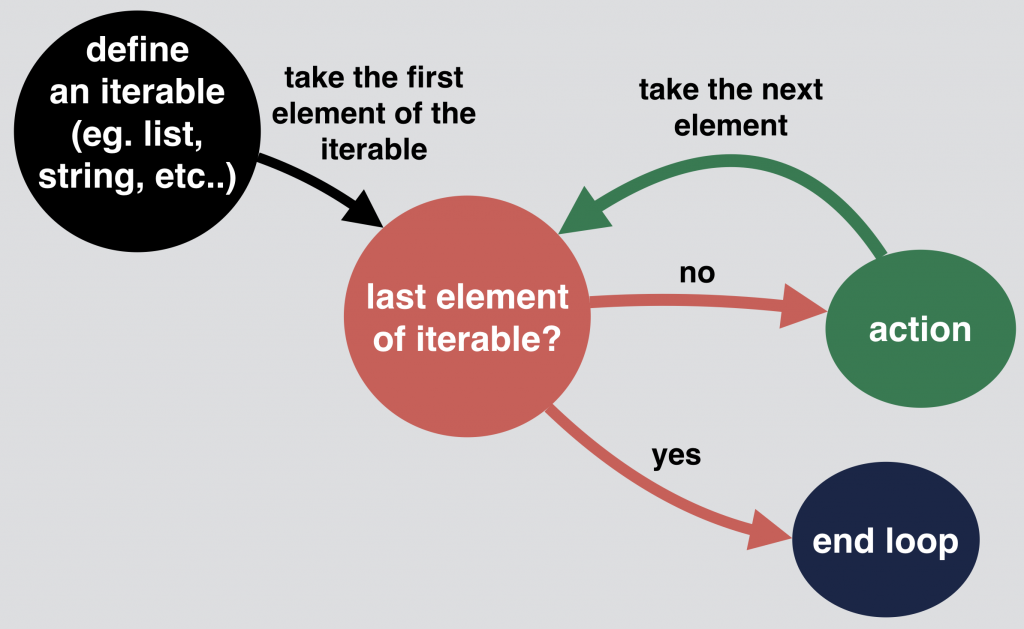
Quite simple.
So for now, I don’t want to go deeper into for loops, you’ll learn the other nuances of them throughout this tutorial series anyway.
Finding the web page(s) we’ll need to scrape
Okay!
Time to get the URLs of each and every TED talk on TED.com.
But where can you find these?
Obviously, these should be somewhere on TED.com… So before you go to write your code in the command line, you should discover the website in a regular browser (e.g. Chrome or Firefox). After like 10 seconds of browsing, you’ll find the web page you need: https://www.ted.com/talks
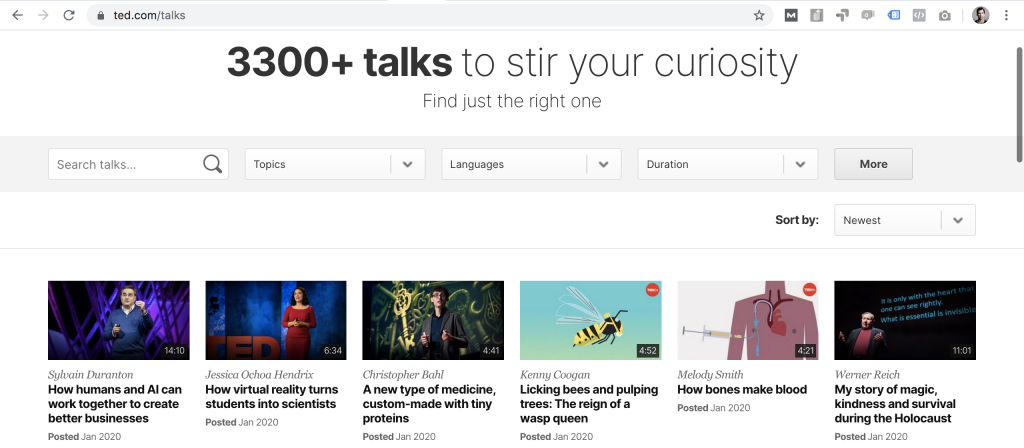
Well, before you go further, let’s set two filters!
- We want to see only English videos for now. (Since you’ll do text analysis on this data, you don’t want to mix languages.)
- And we want to sort the videos by the number of views (most viewed first).
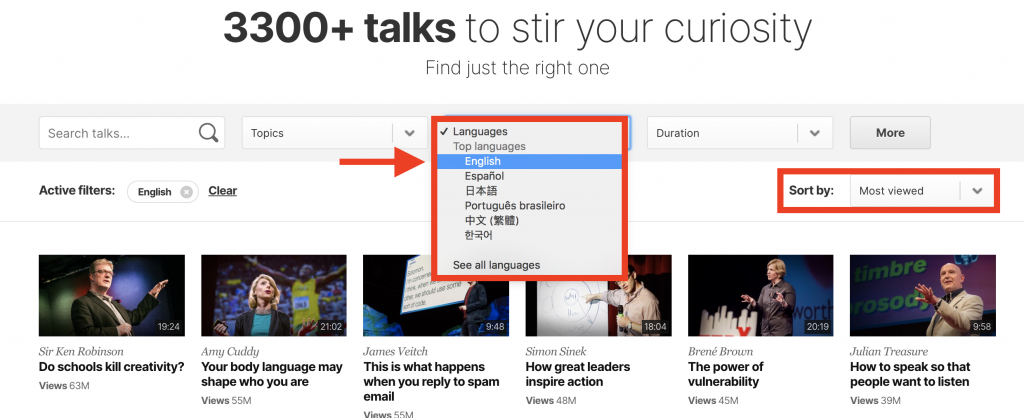
Using these filters, the full link of the listing page changes a bit… Check the address bar of your browser. Now, it looks like this:
https://www.ted.com/talks?sort=popular&language=en
Cool!
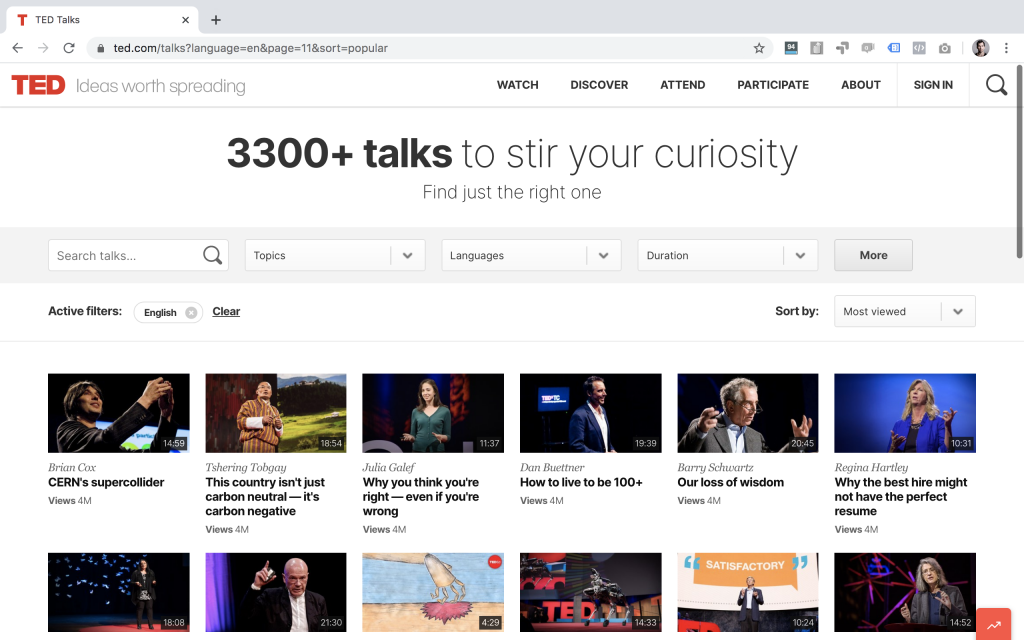
The unlucky thing is that TED.com doesn’t display all 3,300 videos on this page… only 36 at a time:
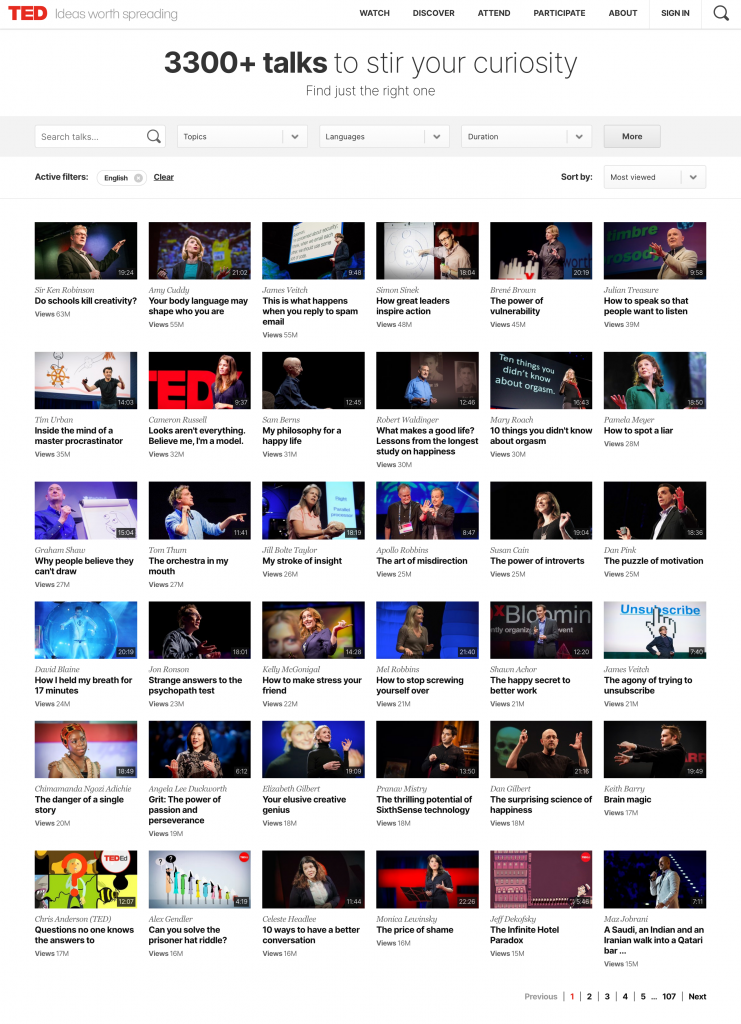
And to see the next 36 talks, you’ll have to go to page 2. And then to page 3… And so on. And there are 107 pages!
That’s way too many! But that’s where the for loops will come into play: you will use them to iterate through all 107 pages, automatically.
…
But for a start, let’s see whether we can extract the 36 unique URLs from the first listing page.
If we can, we will be able to apply the same process for the remaining 106.
Extracting URLs from a listing page
You have already learned curl from the previous tutorial.
And now, you will have to use it again!
curl "https://www.ted.com/talks?sort=popular&language=en"
Notice a small but important difference compared to what you have used in the first episode. There, you typed curl and the full URL. Here, you typed curl and the full URL between quotation marks!
Why the quotation marks? Because without them curl won’t be able to handle the special characters (like ?, =, &) in your URL — and your command will fail… or at least it will return improper data. Point is: when using curl, always put your URL between " quotation marks!
Note: In fact, to stay consistent, I should have used quotation marks in my previous tutorial, too. But there (because there were no special characters) my code worked without them and I was just too lazy… Sorry about that, folks!
Anyway, we returned messy data to our screen again:
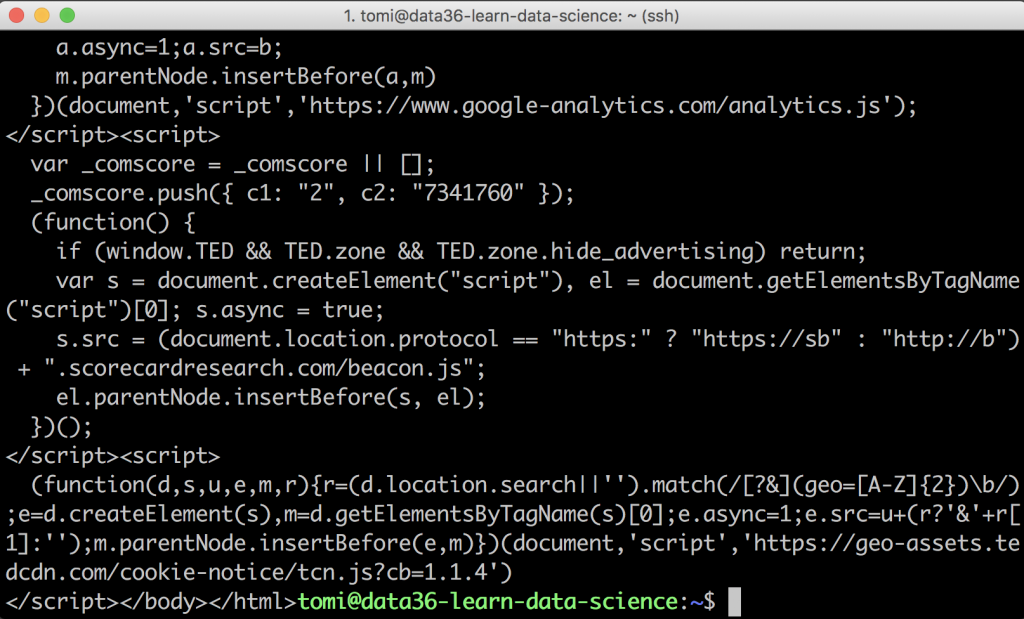
It’s all the html code of this listing page…
Let’s do some data cleaning here!
This time, you can’t use html2text because the data you need is not the text on the page but the transcripts’ URLs. And they are found in the html code itself.
When you build a website in html, you define a link to another web page like this:
href="https://www.example.com/"
So when you scrape an html website, the URLs will be found in the lines that contain the href keyword.
So let’s filter for href with a grep command! (grep tutorial here!)
curl "https://www.ted.com/talks?sort=popular&language=en" | grep "href"
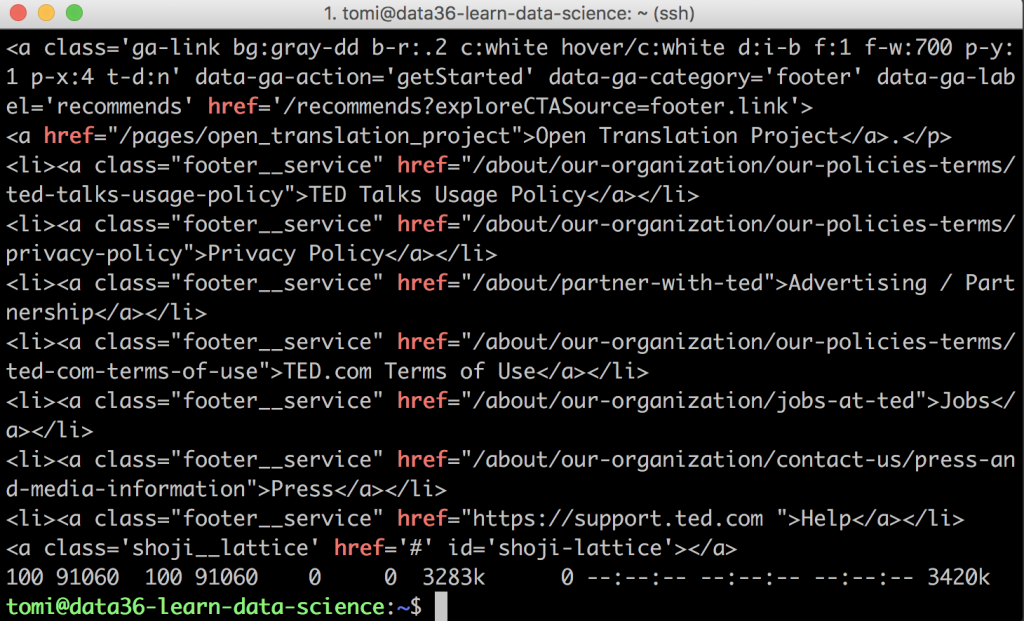
Cool!
If you scroll up, you’ll see URLs pointing to videos. Great, those are the ones that we will need!
But you’ll also see lines with URLs to TED’s social media pages, their privacy policy page, their career page, and so on. You want to exclude these latter ones.
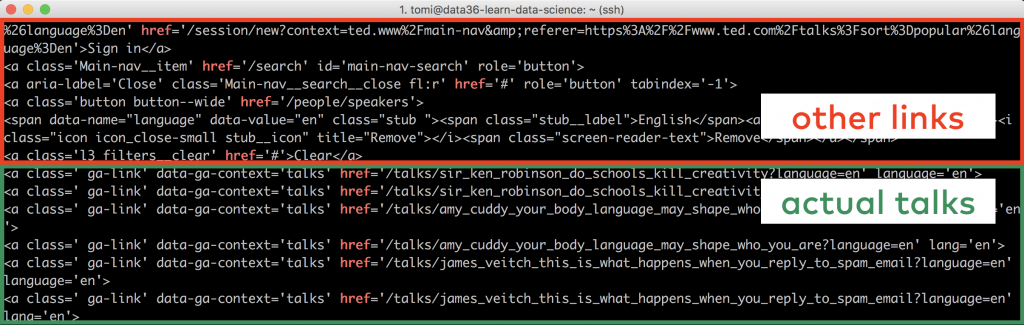
When doing a web scraping project this happens all the time…
There is no way around it, you have to do some classic data discovery. In other words, you’ll have to scroll through the data manually and try to find unique patterns that separate the talks’ URLs from the rest of the links we won’t need.
Lucky for us, it is a pretty clear pattern in this case.
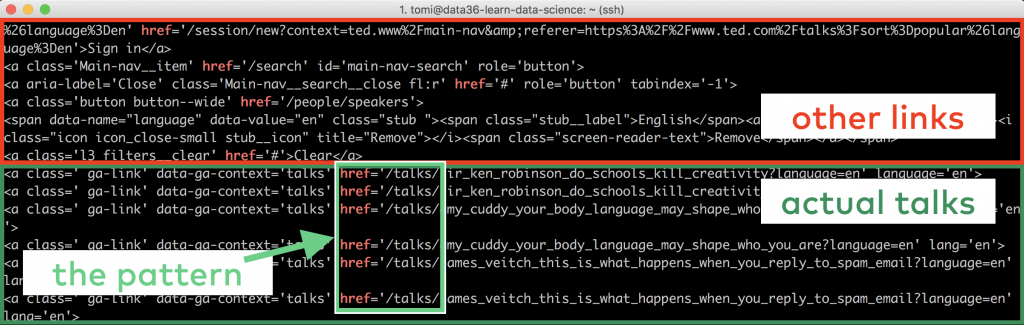
All the lines that contain:
href='/talks/
are links to the actual TED videos (and only to the videos).
Note: It seems that TED.com uses a very logical site structure and the talks are in the /talks/ subdirectory. Many high-quality websites use a similar well-built hierarchy. For the great pleasure of web-scrapers like us. 🙂
Let’s use grep with this new, extended pattern:
curl "https://www.ted.com/talks?sort=popular&language=en" | grep "href='/talks/"
And there you go:
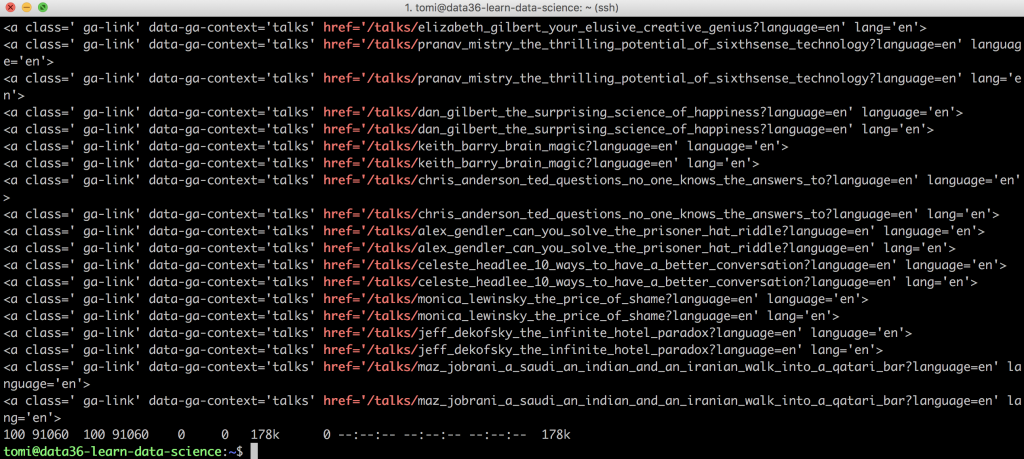
Only the URLs pointing to the talks: listed!
Cleaning the URLs
Well, you extracted the URLs, that’s true… But they are not in the most useful format. Yet.
Here’s a sample line from the data we got:
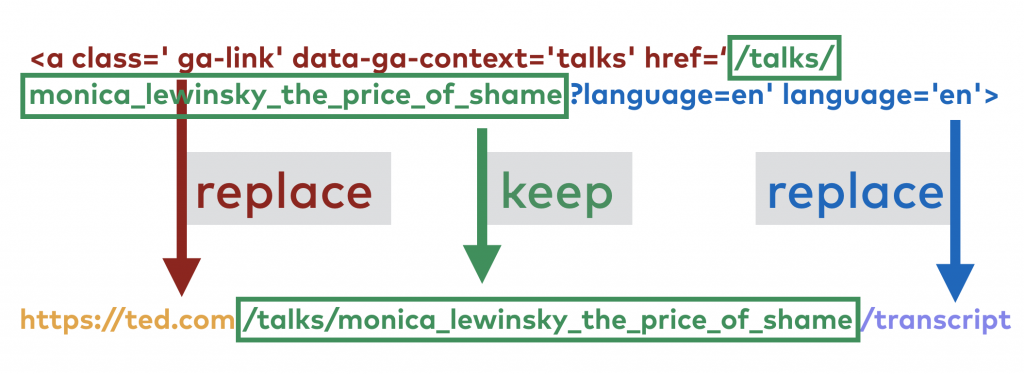
<a class=' ga-link' data-ga-context='talks' href='/talks/monica_lewinsky_the_price_of_shame?language=en' language='en'>

How can we scrape the web pages based on this? No way…
We are aiming for proper, full URLs instead… Something like this:
https://ted.com/talks/monica_lewinsky_the_price_of_shame/transcript

If you take a look at the data, you’ll see that this issue can be fixed quickly. The unneeded red and blue parts are the same in all the lines. And the currently missing yellow and purple parts will be constant in the final URLs, too. So here’s the action plan:
STEP #1:
Keep the green parts!
STEP #2:
Replace this:
<a class=' ga-link' data-ga-context='talks' href=
with this:
https://ted.com
STEP #3:
Replace this:
?language=en' language='en'>
with this:
/transcript
There are multiple ways to solve these tasks in bash.
I’ll use sed, just as in the previous episode. (Read more about sed here.)
Note: By the way, feel free to send in your alternative solutions in email, if you have any!
So for STEP #1, you don’t have to do anything. (Easy.)
For STEP #2, you’ll have to apply this command:
sed "s/^.*href='/https\:\/\/www\.ted\.com/"
And for STEP #3, this:
sed "s/?.*$/\/transcript/"
Note: again, this might seem very complicated to you if you don’t know sed. But as I mentioned in episode #1, you can easily find these solutions if you Google for the right search phrases.
So, to bring everything together, you have to pipe these two new commands right after the grep:
curl "https://www.ted.com/talks?sort=popular&language=en" | grep "href='/talks/" | sed "s/^.*href='/https\:\/\/www\.ted\.com/" | sed "s/?.*$/\/transcript/"
Run it and you’ll see this on your screen:
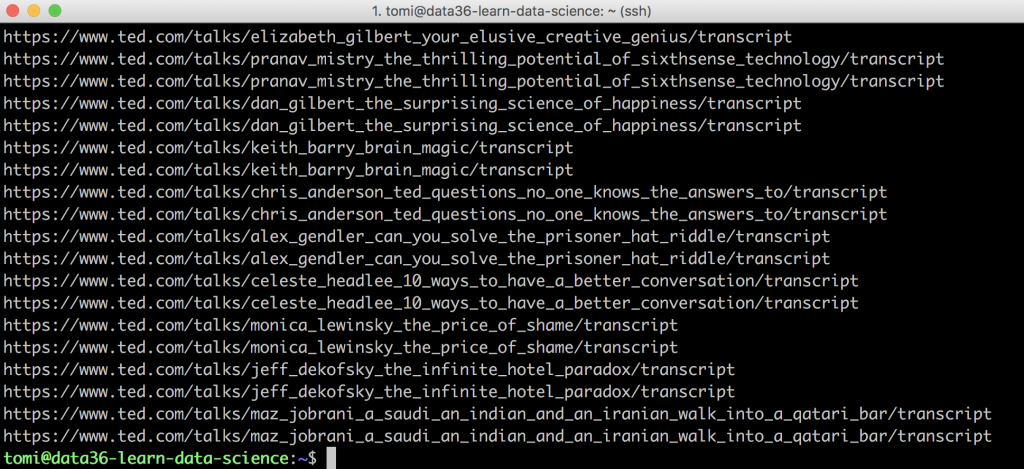
Nice!
There is only one issue. Every URL shows up twice… That’s an easy fix though. Just add one more command – the uniq command – to the end:
curl "https://www.ted.com/talks?sort=popular&language=en" | grep "href='/talks/" | sed "s/^.*href='/https\:\/\/www\.ted\.com/" | sed "s/?.*$/\/transcript/" | uniq
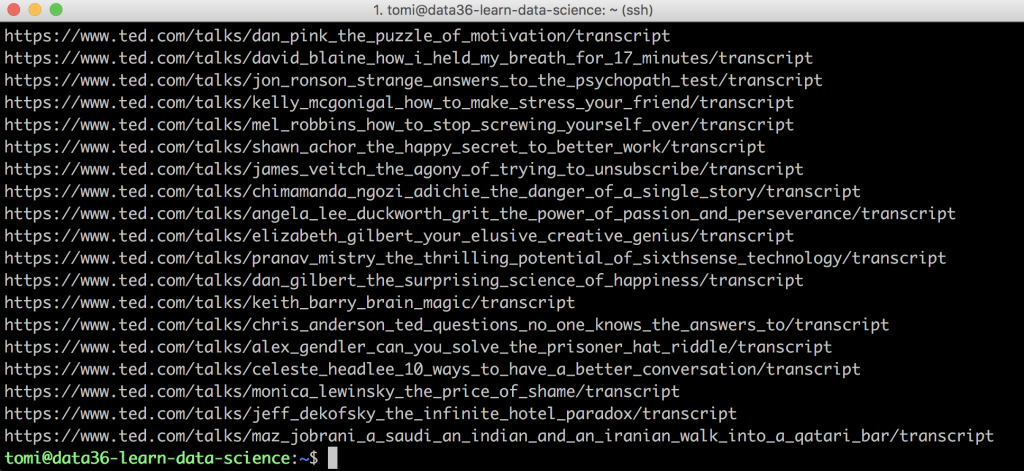
Awesome!
The classic URL trick for scraping multiple pages
This was the first listing page only.
But we want to scrape all 107!
So go back to your browser (to this page) and go to page 2…
You’ll see that this web page looks very similar to page 1 — but the structure of the URL changes a bit.

Now, it’s:
https://www.ted.com/talks?language=en&page=2&sort=popular
There is an additional &page=2 parameter there. And it is just perfect for us!
If you change this parameter to 1, it goes back to page 1:
https://www.ted.com/talks?language=en&page=1&sort=popular
But you can change this to 11 and it’ll go to page 11:
https://www.ted.com/talks?language=en&page=11&sort=popular
By the way, most websites (not just TED.com’s) are built by following this logic. And it’s perfect for anyone who wants to scrape multiple pages…
Why?
Because then, you just have to write a for loop that changes this page parameter in the URL in every iteration… And with that, you can easily iterate through and scrape all 107 listing pages — in a flash.
Just to make this crystal clear, this is the logic you’ll have to follow:

Scraping multiple pages (URLs) – using a for loop
Let’s see this in practice!
1) The header of the for loop will be very similar to the one that you have learned at the beginning of this article:
for i in {1..107}
A slight tweak: now, we have 107 pages — so (obviously) we’ll iterate through the numbers between 1 and 107.
2) Then add the do line.
3) The body of the loop will be easy, as well. Just reuse the commands that you have already written for the first listing page a few minutes ago. But make sure that you apply the little trick with the page parameter in the URL! So it’s not:
https://www.ted.com/talks?language=en&page=1&sort=popular
but:
https://www.ted.com/talks?language=en&page=$i&sort=popular
This will be the body of the for loop:
curl "https://www.ted.com/talks?language=en&page=$i&sort=popular" | grep "href='/talks/" | sed "s/^.*href='/https\:\/\/www\.ted\.com/" | sed "s/?.*$/\/transcript/" | uniq
4) And then the done closing line, of course.
All together, the code will look like this:
for i in {1..107}
do
curl "https://www.ted.com/talks?language=en&page=$i&sort=popular" |
grep "href='/talks/" |
sed "s/^.*href='/https\:\/\/www\.ted\.com/" |
sed "s/?.*$/\/transcript/" |
uniq
done
You can test this out in your Terminal… but in its final version let’s save the output of it into a file called ted_links.txt, too!
Here:
for i in {1..107}
do
curl "https://www.ted.com/talks?language=en&page=$i&sort=popular" |
grep "href='/talks/" |
sed "s/^.*href='/https\:\/\/www\.ted\.com/" |
sed "s/?.*$/\/transcript/" |
uniq
done > ted_links.txt
Now print the ted_links.txt file — and enjoy what you see:
cat ted_links.txt
Very nice: 3,000+ unique URLs listed into one big file!
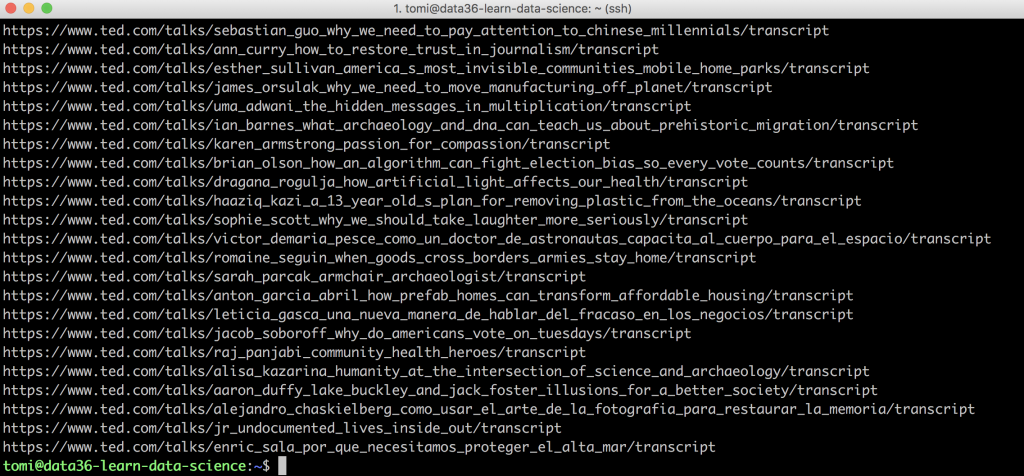
With a few lines of code you scraped multiple web pages (107 URLs) automatically.
This wasn’t an easy bash code to write, I know, but you did it! Congratulations!
Scraping multiple web pages again!
We are pretty close — but not done yet!
In the first episode of this web scraping tutorial series, you have created a script that can scrape, download, extract and clean a single TED talk’s transcript. (That was Sir Ken Robinson’s excellent presentation.)
This was the bash code for it:
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text | sed -n '/Details About the talk/,$p' | sed -n '/Programs &. initiatives/q;p' | head -n-1 | tail -n+2
And this was the result:
And inn this article, you have saved the URLs for all TED talk transcripts to the ted_links.txt file:
cat ted_links.txt
All you have to do is to put these two things together.
To go through and scrape 3,000+ web pages, you will have to use a for loop again.
The header of this new for loop will be somewhat different this time:
for i in $(cat ted_links.txt)
Your iterable is the list of the transcript URLs — found in the ted_links.txt file.
The body will be the bash code that we’ve written in the previous episode. Only, the exact URL (that points to Sir Ken Robinson’s talk) should be replaced with the $i variable. (As the for loop goes through the lines of the ted_links.txt file, in each iteration the $i value will be the next URL, and the next URL, and so on…)
So this will be the body:
curl $i | html2text | sed -n '/Details About the talk/,$p' | sed -n '/Programs &. initiatives/q;p' | head -n-1 | tail -n+2
If we put these together, this is our code:
for i in $(cat ted_links.txt) do curl $i | html2text | sed -n '/Details About the talk/,$p' | sed -n '/Programs &. initiatives/q;p' | head -n-1 | tail -n+2 done
Let’s test this!
After hitting enter, you’ll see the TED talks printed to your screen — scraped, extracted, cleaned… one by one. Beautiful!
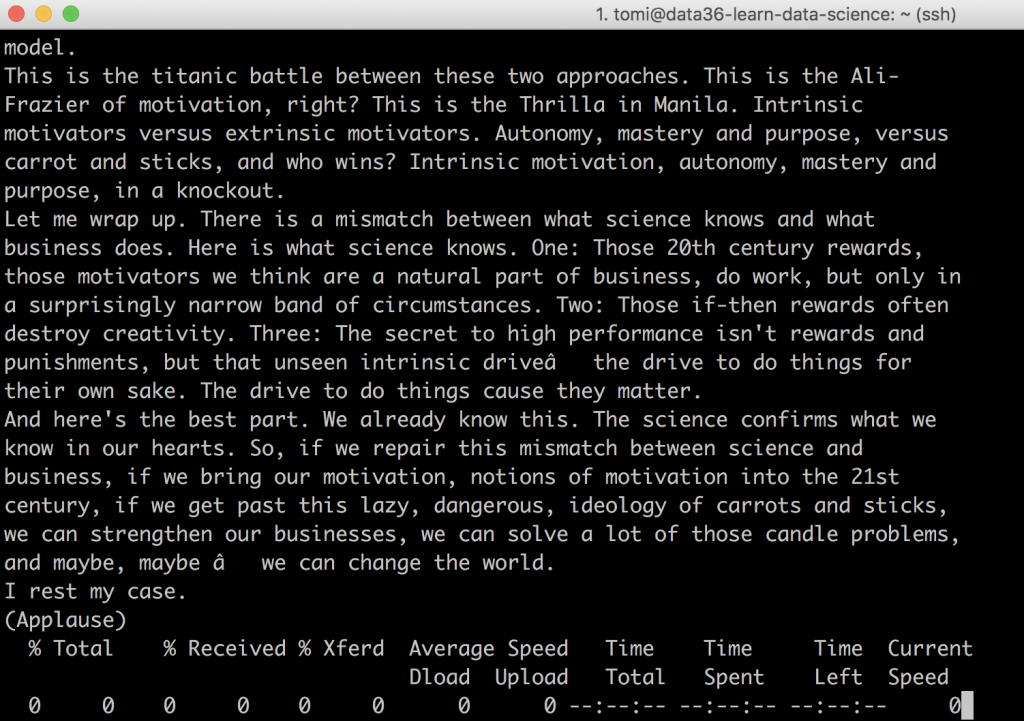
But we want to store this data into a file — and not to be printed to our screen… So let’s just interrupt this process! (Scraping 3,000+ web pages would take ~1 hour.) To do that, hit CTRL + C on your keyboard! (This hotkey works on Mac, Windows and Linux, too.)
Storing the data
Storing the transcripts into a file (or into more files) is really just one final touch on your web scraping bash script.
There are two ways to do that:
The lazy way and the elegant way.
1) I’ll show you the lazy way first.
It’s as simple as adding > ted_transcripts_all.txt to the end of the for loop. Like this:
for i in $(cat ted_links.txt) do curl $i | html2text | sed -n '/Details About the talk/,$p' | sed -n '/Programs &. initiatives/q;p' | head -n-1 | tail -n+2 done > ted_transcripts_all.txt
Just run it and after ~1 hour processing time (again: scraping 3,000+ web pages can take a lot of time) you will get all the transcripts into one big file (ted_transcripts_all.txt).
Great! But that’s the lazy way. It’s fast and it will be a good enough solution for a few simple text analyses.
2) But I prefer the elegant way: saving each talk into a separate file. That’s much better in the long term. With that, you will be able to analyze all the transcripts separately if you want to!
To go further with this solution, you’ll have to create a new folder for your new files. (3,000+ files is a lot… you definitely want to put them into a dedicated directory!) Type this:
mkdir ted_transcripts
And then, you’ll have to come up with a naming convention for these files.
For me talk1.txt, talk2.txt, talk3.txt(…) sounds pretty logical.
To use that logic, you have to add one more variable to your for loop. I’ll call it $counter, its value will be 1 in the first iteration — and I’ll add 1 to it in every iteration as our for loop goes forward.
counter=1 for i in $(cat ted_links.txt) do curl $i | html2text | sed -n '/Details About the talk/,$p' | sed -n '/Programs &. initiatives/q;p' | head -n-1 | tail -n+2 counter=$((counter+1)) done
Great — the only thing left is to add the file name itself:
talk$counter.txt
(In the first iteration this will be talk1.txt, in the second as talk2.txt, in the third as talk3.txt and so on — as the $counter part of it changes.)
Okay, so add the > character, your freshly created folder’s name (ted_transcripts) and the new file name (talk$counter.txt) into the right place of the for loop’s body:
counter=1 for i in $(cat ted_links.txt) do curl $i | html2text | sed -n '/Details About the talk/,$p' | sed -n '/Programs &. initiatives/q;p' | head -n-1 | tail -n+2 > ted_transcripts/talk$counter.txt counter=$((counter+1)) done
Let’s run it!
And in ~1 hour, you will have all the TED transcripts sorted into separate files!
You are done!
You have scraped multiple web pages… twice!
Saving your bash script — and reusing it later
It would be great to save all the code that you have written so far, right?
You know, just so that you’ll be able to reuse it later…
Let’s create a bash script!
Type this to your command line:
mcedit ted_scraper.sh
This will open our favorite command line text editor, mcedit and it will create a new file called ted_scraper.sh.
Note: We use .sh as the file extension for bash scripts.
You can copy-paste to the script all the code that you have written so far… Basically, it will be the two for loops that you fine-tuned throughout this article.
And don’t forget to add the shebang in the first line, either!#!/usr/bin/env bash
For your convenience, I put everything in GitHub… So if you want to, you can copy-paste the whole thing directly from there. Here’s the link.
This is how your script should look in mcedit:
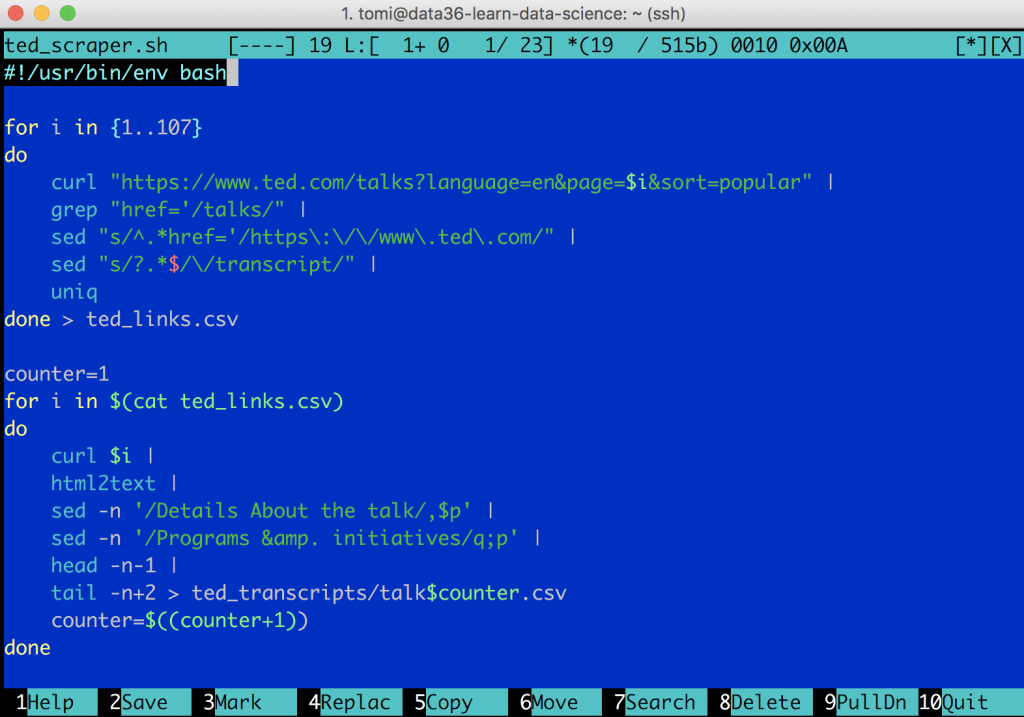
Click the 10-Quit button at the bottom right corner! Save the script!
And boom, you can reuse this script anytime in the future.
Even more, you can run this bash script directly from this .sh file.
All you have to do is to give yourself the right privileges to run this file:
chmod 777 ted_scraper.sh
And then with this command…
./ted_scraper.sh
you can immediately start your script.
(Note: if you do this, make sure that your folder system is properly prepared and you have indeed created the ted_transcripts subfolder in the main folder where your script is located. Since you’ll refer to this ted_transcripts subfolder in the bash script, if you don’t have it, your script will fail.)
One more comment:
Another text editor that I’ve recently been using quite often — and that I highly recommend to everyone — is Sublime Text 3. It has many great features that will make your coding life as a data scientist very, very efficient… And you can use it with a remote server, too.
In Sublime Text 3, this is how your script looks:
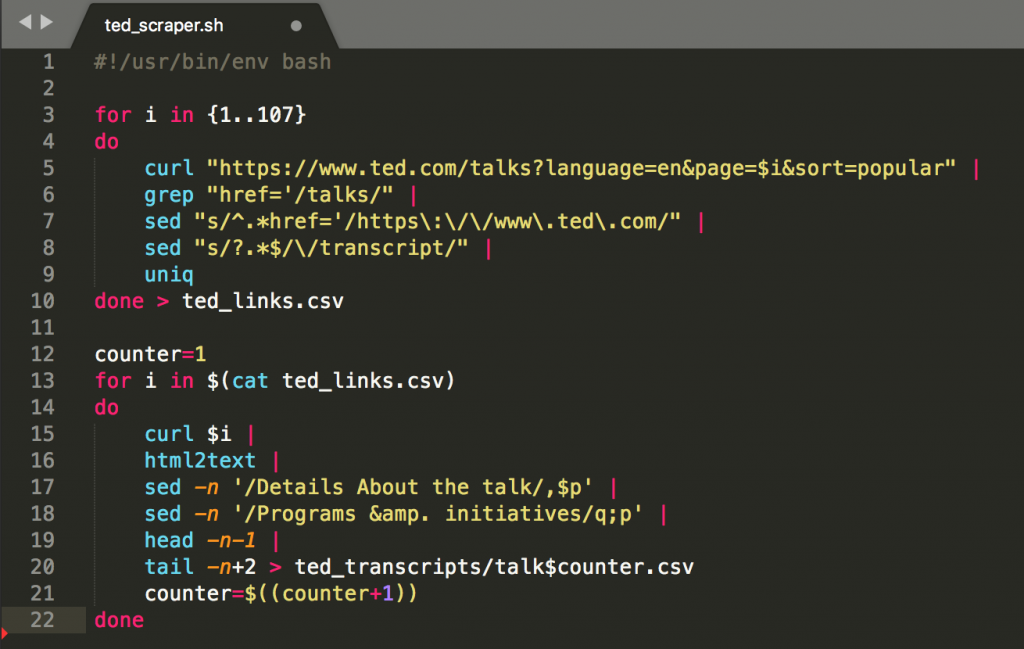
Pretty nice!
Conclusion
Whoaa!
Probably, this was the longest ever tutorial on the Data36 Blog, so far. Scraping multiple URLs can get complex, right? Well, we have written only ~20 lines of code… but as you can see, even that can take a lot of thinking.
Anyway, if you have done this with me — and you have all 3,800+ TED talks scraped, downloaded, extracted and cleaned on your remote server: be really proud of yourself!
It wasn’t easy but you have done it! Congratulations!
Your next step, in this web scraping tutorial, will be to run text analyses on the data we got.
We will continue from here in the web scraping tutorial episode #3! Stay with me!
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester