
Note: to get the most out of this article, you should not just read it, but actually do the coding part with me!
If you don’t have the data infrastructure yet, you can install it on your own in roughly 30-60 minutes. Simply read and follow my previous article: How to Install Python, SQL, R and Bash (for non-devs)
Let’s get into this! Here are the first steps to learn the most basic data coding language: bash.
What is bash and why should you learn it?
Bash (often referred to as “the command line”) is not a language directly built for data science. It’s a command language which lets you interact with your operating system (in this case Ubuntu). You can type commands and bash will interpret them. Without going into further technical details, the one thing you should understand: you don’t need to learn bash just because of data science. You will use it for so much more!
- To move, copy or rename files between folders and computers.
- To integrate and/or automate your SQL, Python and R scripts.
- To set up new data tools on your data server.
- Etc…
But besides all these above: it’s a very powerful tool for data analysis as well.
In this article, I’ll guide you through the first steps of learning bash!
Open your Terminal! Meet the prompt.
If you read the above-mentioned installation guide, you should be familiar with Terminal. So open it up, log in to your data server and you will see something like this.
Without typing any commands, let’s take a look at the command line itself:
tomi@data36-learn-server:~$
In bash you will have this $ sign on every line.
The text before the dollar sign is called the prompt, which usually tells you more about your username, the current folder you are located in your remote computer and other things you can set (but we don’t care about those in this article).
The prompt changes when you go to Python (>>>), R (>) or SQL (postrgres=#), so you will know whether you are using bash or any other language. (That’s useful!)

The point is that all the bash commands I’ll show you in this article should be typed after the $ character.
Get some data!
To practice a bit, we will download an open data set. “Open” means that it’s free to use. There is a beautiful data set (originally published here) with 7.000.000+ lines of data that you can simply download by typing this to the command line:
wget http://stat-computing.org/dataexpo/2009/2007.csv.bz2
UPDATE: As of 29 December 2019, I realized that the dataset has been removed from its original place. I’ve just reached out to the webmaster of the website. Until then, you can (temporary) download the dataset using this code:wget 46.101.230.157/sql_tutorial/2007.csv
Remember, you logged into your data server! So when you are in the Terminal, you are on your remote server. That means this will be downloaded there and not to your local computer! So don’t worry, you can’t make a mess there! 😉
Once it’s downloaded, you will have a very cool data set containing the arrival and departure details of all commercial flights in the US from 2007. (Yes, this data is open to the public.)
Where am I now? Orientation in bash.
Per definition you are in your user’s folder (in my case it’s /home/tomi). I’ll get back to this soon, but first, let’s see what we have in our current folder. Type this bash command:
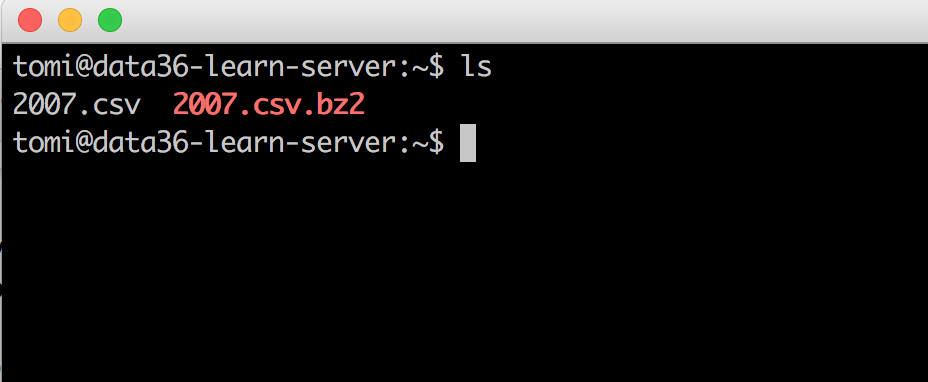
ls
ls stands for “list” and it literally lists out all the files in your folder. It’s not a surprise that you have 1 file only: 2007.csv
Note: If you have done this article before the 2019 update, you’ll have two files: one is the one you’ve just downloaded (2007.csv.bz2) and the other is what you have just unpacked (2007.csv). Either way, we’ll work with 2007.csv only.
Note: If you are here from the Junior Data Scientist’s First Month video course, check out the ls -v command, too. The -v parameter adds a small (but important) modification to the original command: it will print everything in “natural” order! Learn more about that in the course itself!
I know you are very excited to see what data we have in our 2007.csv file, but let me show you some more important “orientation” related bash commands before that.
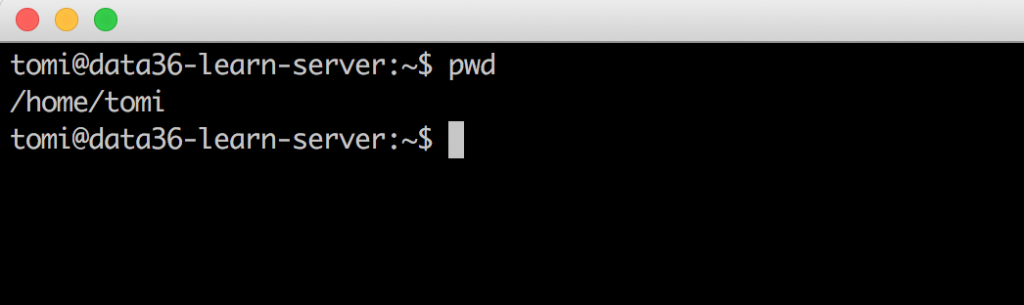
pwd
(pwd stands for “print working directory”) This will show you, where exactly you are on your remote computer. I’m in the /home/tomi folder – as I’ve already mentioned before.
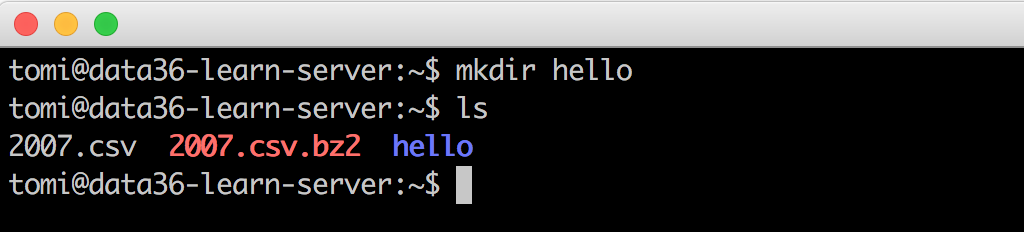
mkdir hello
(Stands for “make directory.”) This created a new folder in your folder called “hello.” Obviously, you can type anything instead of “hello.” mkdir [folder name] is the general folder-creator command on bash. Let’s use ls to double-check your new folder. Oh, it’s there! Yay!
It’s a folder, so you can go into it. The bash command to do that is:cd [folder name]
(cd means “change directory”)
So in this case:cd hello
If you use ls again, you will see that this folder is empty. And if you use pwd, you will see that you are indeed in the hello folder.
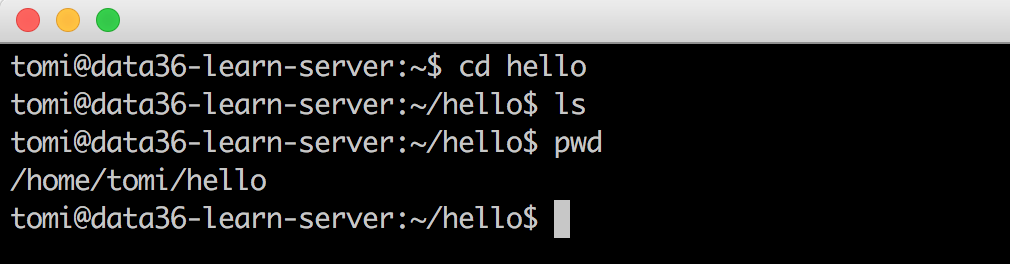
If you want to go one folder up, use:
cd ..
You can try ls and pwd again to make sure that you know where you are.
Now try out how copying files works in the command line:
cp [folder/file_to_copy] [folder/new_file_name]
As you can see, you need to give two parameters here. The first one is the name and the location of the original file, the second is the preferred new name and the location of the new file. Let’s do it:
cp /home/tomi/2007.csv /home/tomi/hello/delay2007.csv
This bash command copied from our original folder into our hello folder the 2007.csv file. Plus the new file’s name won’t be 2007.csv anymore, but delay2007.csv.
Note: when you use cp, you don’t necessarily need to type the whole (absolute) path of the file. You can use the so-called “relative paths” instead. So as I’m in the /home/tomi/ folder I can just type:
cp 2007.csv hello/anothercopy.csv
Same result! (Except that the new filename in this case will be anothercopy.csv)
Test yourself #1
Here’s a quick assignment if you want to test yourself! Try to solve the case by yourself! Nothing else will be needed but the bash commands I’ve described above. Once you are done, you can check out how I’d do it.
Exercise:
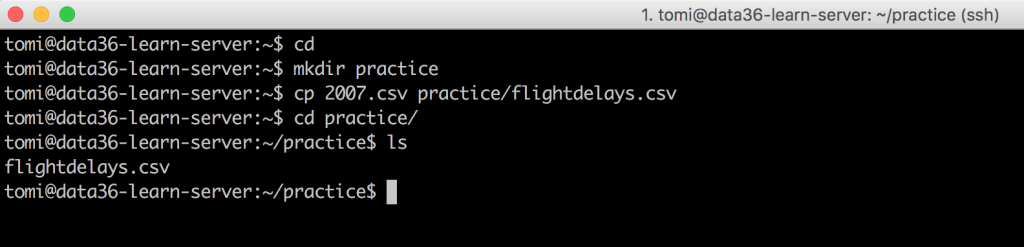
Create a new folder with the name practice!
Copy your 2007.csv file into this new practice folder and name it flightdelays.csv.
…
…
Solution:
Type this into the command line one by one:
cd– (optional) this command will automatically move you to your main folder (/home/tomi)mkdir practice– this will create the folderpracticecp 2007.csv practice/flightdelays.csv– this command will copy the file into the folder with the new namecd practice– with that you can go into your new folderls– this command will list the files in the practice folder, you will have only one:flightdelays.csv
DONE!
Printing files in bash
Okay!
No more boring stuff, let’s dig into the raw data! I’ll continue with the new file we’ve copied into the practice folder. Our next bash command will print our whole .csv file.
cat flightdelays.csv
Here’s a video about what happens:
Okay, it might be nerdy to say this… but: how cool does this look? Like we could be in the Matrix. Well, Neo, this is our data file line by line – and as I said it’s over 7 million lines, so it might take some time to print the whole file on your screen. In the video above I interrupted this process. You can do the same for yourself by pressing CTRL + C on your keyboard.
The cat command wasn’t really meaningful at this time, but at least now you have a sense of what kind of data you have in this file. In data science it’s usually an important first step to spend some time discovering your raw data. However if you want to do this more easily, you can print the first 10 lines or the last 10 lines of your file by typing these to the command line:
head flightdelays.csvtail flightdelays.csv
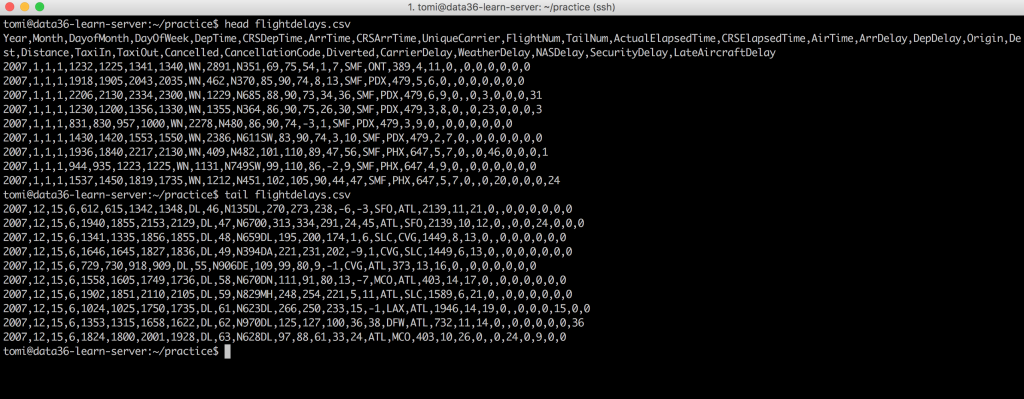
When you typed head, you got back 10 lines, and the first one was the header of your data table. Depending on the file you use, sometimes you have this, sometimes you don’t.
The last bash command for today’s article: word count!wc flightdelays.csv
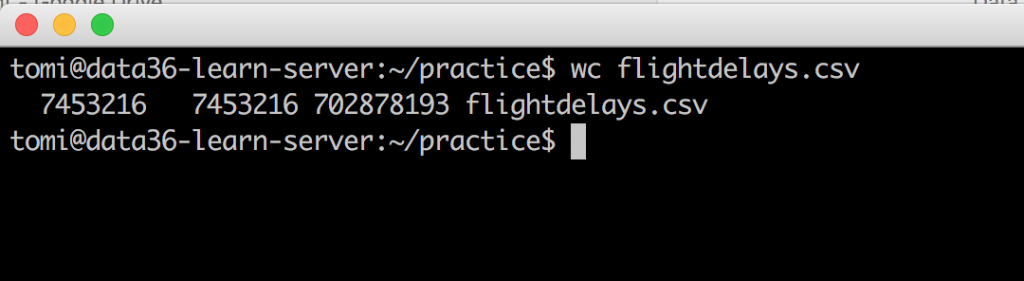
Three numbers are showing up on your screen:
7453216: The number of lines in your file.7453216: The number of words in your file. (Some explanation: bash defines “words” separated by spaces, tabs or line-breaks. As you saw before, in this file the words were separated by commas. So bash understands one line as one word. We will fix this issue later.)702878193: The number of all the characters (spaces included) in your file.
So it’s not just word count, but line count and character count too.
CONCLUSION
Hey! You’ve just started to work with a 7 million+ line data file!
This is awesome!
(But before you start to tell your friends that you are practicing with “big data,” I have to draw your attention to the fact: this is not yet big data at all.)
You’ve also made the first important steps to learn data coding and become a data scientists!
I’ll continue from here! UPDATE: for episode 2, click here!
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester
Sources:
- http://stat-computing.org/dataexpo/ — shout out for the awesome dataset!