
This is the last piece of my “Data Coding 101: Introduction to Bash” series, where I introduce the very basics of how to use the command line for data science. If you read all 6 articles – including this one – you will have a good enough base knowledge to start your first data hobby project. Today I’ll show you 4 more command line tools that we frequently use for data analysis:sed, awk, join and date.
And if you haven’t read the previous articles, I recommend starting here:
- Data Coding 101 – Install Python, R, SQL and bash!
- Data Coding 101 – Intro to Bash ep#1
- Data Coding 101 – Intro to Bash ep#2
- Data Coding 101 – Intro to Bash ep#3
- Data Coding 101 – Intro to Bash ep#4
- Data Coding 101 – Intro to Bash ep#5
sed – substitute characters and strings
As we have discussed before, bash handles all your data as text. This means that if you want to clean your data, you should think about the process as you would do it with a text file. sed stands for “stream editor” and it’s a very cool tool for modifying text based on common patterns across your whole file.
Let’s see a concrete example. Go back to your flightdelays.csv file! (If you don’t know what’ that is, check out this article and download it!)
head flightdelays.csv
You already know that head will print the first 10 rows of your file to the screen.
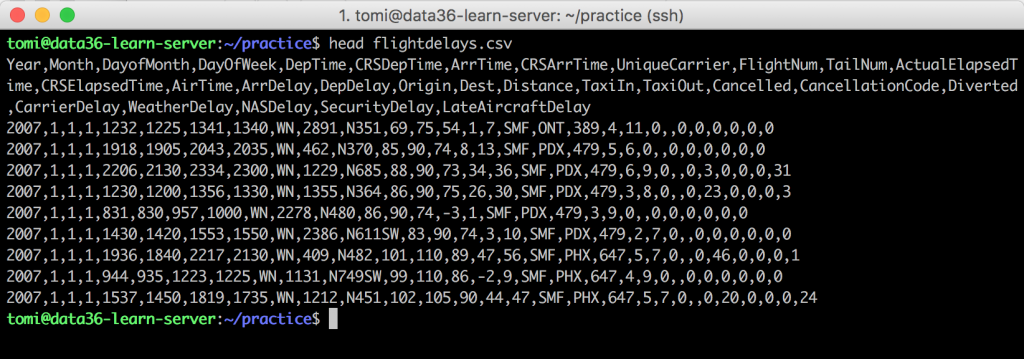
As you can see the field separator is ,. It’s not the most useful delimiter, usually, so let’s try to change it to something else. First try to use spaces instead. Here comes sed into play:
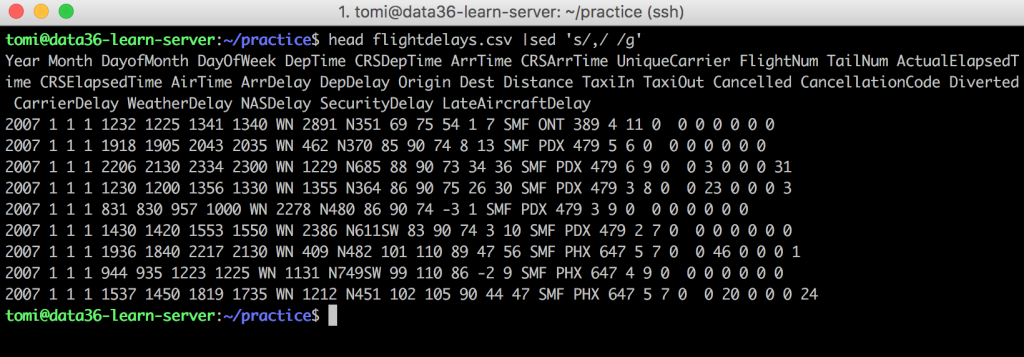
head flightdelays.csv |sed 's/,/ /g'
Note: In episode 2 I’ve already explained the role of the | (pipe) character. If you are not sure what’s happening, read it first!
We have printed the first 10 lines, then modified the output with sed! What happens step by step:
sed ‘s/,/ /g’ –» After sed you have to specify what and how would you like to modify in your file. You can do that with an expression between apostrophes. In this case: s refers to “substitute” and it defines that we want to remove something and put something else instead. / is usually just the delimiter between the different parameters of the sed command. , is the character you want to remove, and (the space after the second /) is the character that you want to see instead. And g (for “global“) tells bash that this should happen for every appearance of the , character. (If you don’t add g, sed will change only the first , in each line.) Here’s the same explanation in a picture:

some more cool things with sed
Most people use sed only for substituting characters, but it has so much more potential.
First of all, you can change whole strings. E.g. try this:head flightdelays.csv |sed 's/SMF/DATA36_TUTORIALS/g'
See? All the SMF strings have been replaced with DATA36_TUTORIALS.
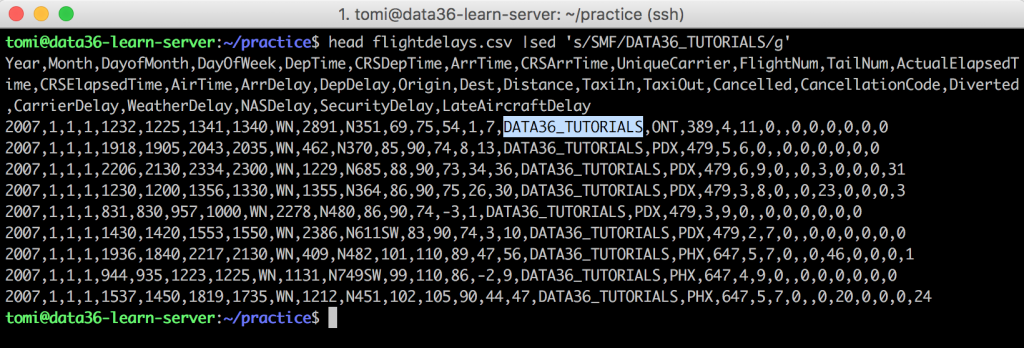
Okay, maybe this is not the most useful thing you could do with your file… But you get the point!
One important thing that you have to know about sed is that it works with regular expressions (also known as regexp or regex).
I’ll write a whole article about regexp, but for now, here’s the wikipedia article about it. Please be aware that if you want to do special modifications with sed (e.g. change all the numbers to x), you can do it, but you have to be familiar with regexp. (Or you have to be really good at googling! ;-)) By the way, the above example (change all the numbers in your file to x) would look something like this:head flightdelays.csv |sed 's/[0-9]/x/g'
Where [0-9] is a regular expression for all the numbers.
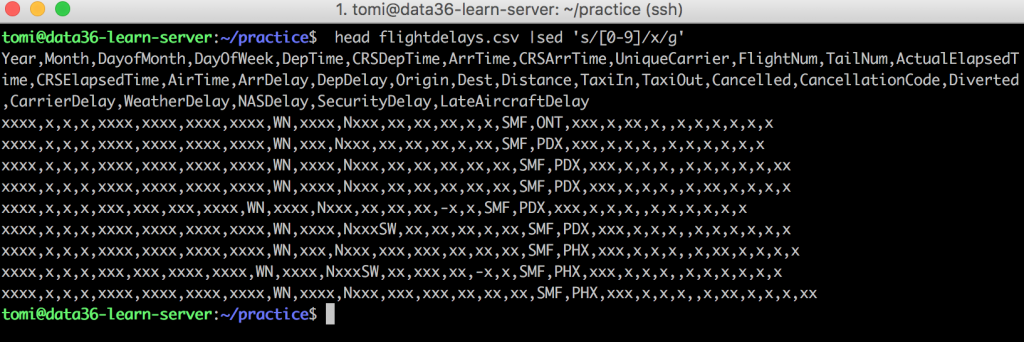
It’s also good to know that sed is not just good for substitution, but also for deleting specific lines. E.g. here’s a hobby project of mine that I published on Medium: Learning languages very quickly — with the help of some very basic Data Science. In this project I removed all the empty lines from my file with this command:
sed '/^$/d' –» where ^$ is a regular expression for empty lines and d refers to “delete”
You can similarly:
- insert a line before another line with a matching pattern (by using
i) - insert a line after another line with a matching pattern (by using
a) - change a line with another line by using
c - etc…
sed is a cool tool! Use it!
Note: this is the best online tutorial about sed that I’ve ever read: http://www.grymoire.com/Unix/Sed.html
date – using dates in the command line
A much simpler tool: date. With this command line tool, you can print dates in every format. Here are 3 examples:
Bash Command:date
Result:
Sun Apr 2 23:12:45 UTC 2017
Bash Command:date +%D
Result:
04/02/17
Bash Command:date +%Y-%m-%d
Result:
2017-04-02
Note: I wrote this article on the 2nd of April so it printed the current date and time.
As you can see, there’s a pretty wide range of formatting here. The only thing you need to do is to type date, then a + character (which means that you want to add an attribute to specify your format), then simply add the formatting options (eg. %Y or %m) and any other characters (usually between apostrophes), that you want to see there. Example:
Bash Command:date +%Y-%m-%d': '%A
Result:
2017-04-02: Sunday
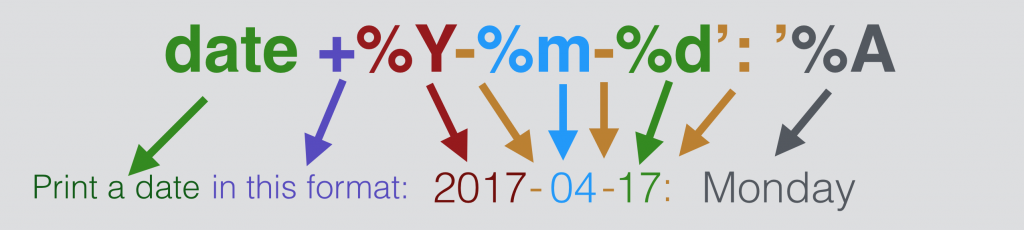
I encourage you to go into the manual for date using the man date command line tool. Here you will find all the possible formats.
join – to join two text files
join is a command that is very useful in SQL as well. But for now let’s stay with the command line. Here’s a little example. You can just follow along here, but you can also try this on your own data server, if you create these files:
file1.csv
animal weight elephant 500 monkey 300 tiger 300 tiger 320 zebra 200 zebra 220
file2.csv
animal color elephant grey tiger yellow zebra white zebra black
Now apply join on these two files…join file1.csv file2.csv
…and you will get these results:
animal weight color elephant 500 grey tiger 300 yellow tiger 320 yellow zebra 200 white zebra 200 black zebra 220 white zebra 220 black
So what happened here?
The two files have been merged based on the first column!
A bit more detail:
First things first, join automatically recognized the delimiter (it was a space) and identified the columns. If your delimiter is not a space or a tab, you have to define this value with the -t option (same as with sort, for instance).
Secondly it automatically picked the first column of both files as the field that we should join on. That’s just perfect in this case. But if you would like to use another column you can specify that with an option as well (I’ll get back to that later).
And third: the join did just happen. All the animals have colors and weights in one file. As you can see the monkey didn’t show up after the merge; this is because there’s no monkey in the second file at all. And as you can also see, we have 4 zebras after the join. The merge created all the possible combinations of colors and weights.
Note: the biggest difference between bash’s join and SQL’s JOIN is that in bash you merge text files and in SQL you merge tables. From our human perspective it looks pretty much the same, but from the computer’s perspective it’s quite different. Because of this…
…it’s very important to know that bash join only works properly with sorted files! If you don’t sort your files, you will get an error message – and fake results. Takeaway: before join always sort.
For now it’s enough if you know only these very basic things about join. I’ll show you some more exciting things about it below.
But first, get familiar with one last command line tool:
awk – for expert text-processing
awk is like another programming language on top of bash – and you don’t have to know this one in detail either. But it’s still good to keep in mind that you can call this language from bash and you can pipe it into your other command line tools.
Usually awk is really great for advanced line-based processing. E.g. if you want to print only those lines in which the 3rd column is greater than 2500, your tool will be awk.
I’ll give you here only 2 practical examples of how awk can be useful to you.
awk – reorder columns
Let’s say we want to have 4 specific columns from our good old flightdelays.csv file:
ArrDelayDepDelayOriginDest
Easy. We’ll just use cut:cut -d',' -f15,16,17,18 flightdelays.csv
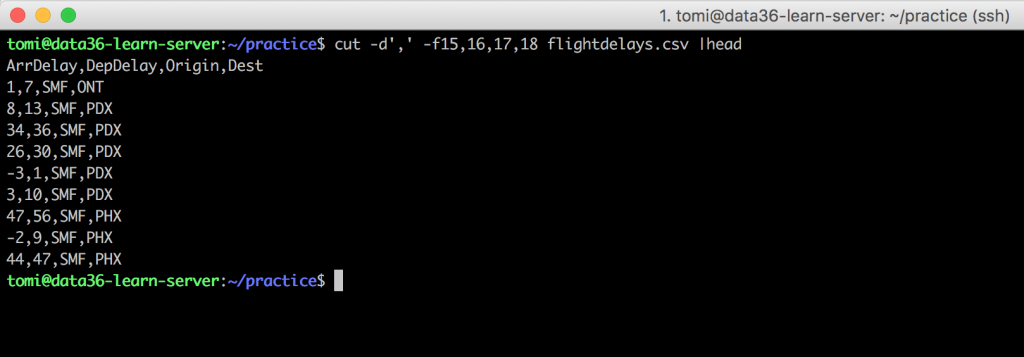
Cool. But the order of the columns would be better like this: Origin, ArrDelay, Dest, DepDelay. You might try to switch the columns in your cut command like this:cut -d',' -f17,15,18,16 flightdelays.csv
But I have bad news. With cut you can’t change the order of the columns.
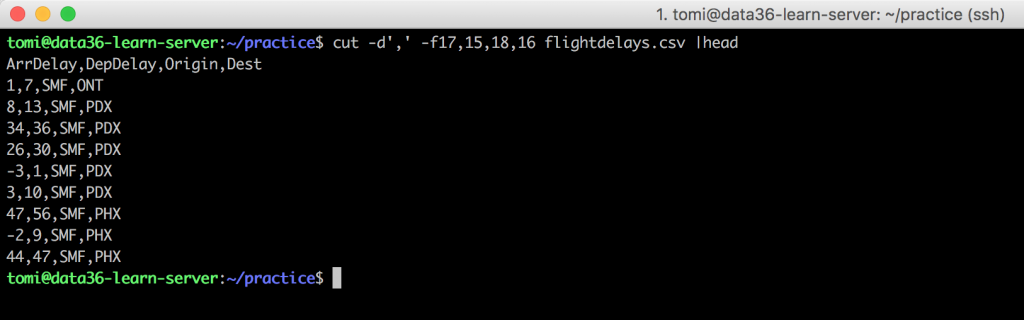
See? Same order! Why? Well, I don’t know, but this is the limitation of the cut command and you can solve it simply by using awk. Try this:awk -F',' '{print $17,$15,$18,$16}' flightdelays.csv
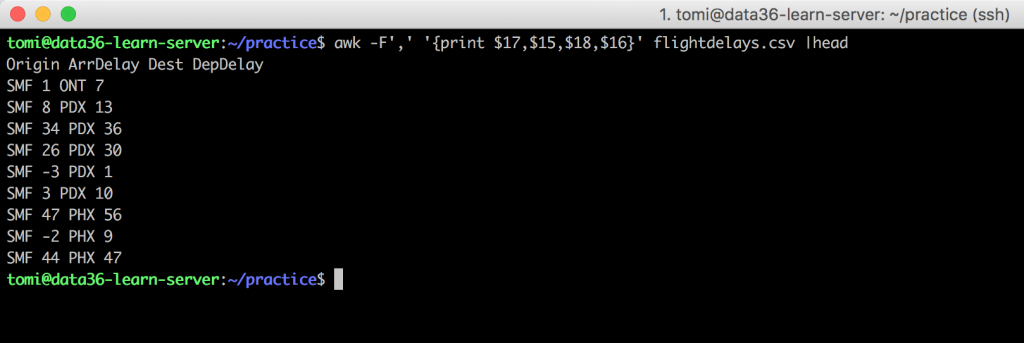
Very similar to cut! Except that here the option for the delimiter will be -F (standing for “field-separator”) and not -d. And the way you define the fields themselves is a bit different too: '{print $17,$15,$18,$16}'. As you might have noticed, the output’s separators won’t be commas anymore, but spaces – this is a default setting of awk. But like with date or echo, you can add anything here, if you put it between quotation marks. E.g.:
awk -F',' '{print $17"___"$15"---"$18","$16}' flightdelays.csv |head
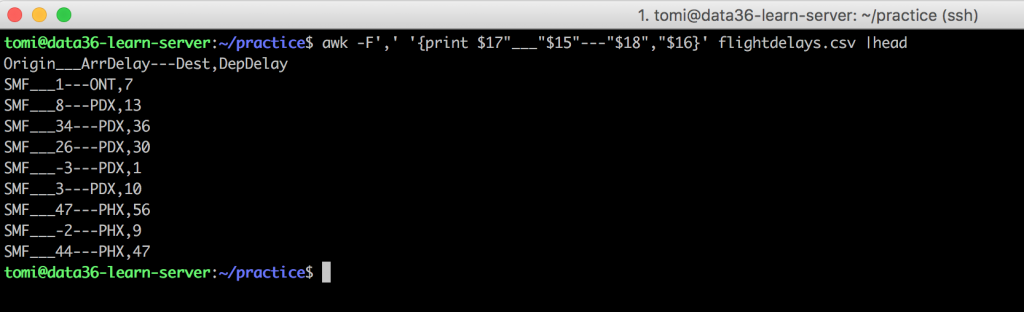
Neat!
awk – sum rows
This is a more straightforward one. Let’s say you want to sum up all the ArrDelays (like you would do in Excel with the SUM command.) First, you have to cut the 15th column. Then you have to make the sum with awk. Here’s the whole command:
cut -d',' -f15 flightdelays.csv |awk '{sss+=$1} END {print sss}'
The result is: 74151049
You might ask, why have we used the cut command first, why didn’t we do everything with one awk command – since we just saw that awk is good for cutting columns too. The answer here is computing time. awk works a bit differently than cut. awk basically goes through your file line by line and always adds the next value to a variable (called sss in this case). That’s what sss+=$1 is there for. This is okay until you have only one column, but when awk has to find this one column in each line… Well that can take forever. So that’s why! We use the best tools for the given task – so we don’t have to wait forever to get the results…
Note: If you are curious, I still recommend trying to get this number purely with awk… And you will see the difference…
Test yourself
Nice. We got through four new tools. It’s time to wrap them up in one ultimate exercise.
It goes like this:
Take the flightdelays.csv file and calculate the summary of all the ArrDelays that happened on Mondays! For the sake of practicing, let’s say you can only use these four columns:
- 1st column:
Year - 2nd column:
Month - 3rd column:
Day - 15th column:
ArrDelay
Hint: You will have to use sed, date and awk for sure. And in my solution I’ll use join as well!
.
.
.
And the solution is here!
Put the whole stuff into a script called arrdelay_calculator.sh
#!/usr/bin/env bash
cut flightdelays.csv -d',' -f1,2,3,15 |sed 's/,/-/' |sed 's/,/-/' |sed 's/,/\t/' > tmp1.csv
a=0
while [ $a -le 364 ]
do
i=$a'day'
date -d'2007-1-1'+$i +%Y-%-m-%-d' '%A >> tmp2.csv
a=$((a+1))
done
sort tmp1.csv > tmp3.csv
grep 'Monday' tmp2.csv |sort > tmp4.csv
join tmp3.csv tmp4.csv |cut -d' ' -f2 |awk '{sss+=$1} END {print sss}'
rm tmp1.csv
rm tmp2.csv
rm tmp3.csv
rm tmp4.csv
If you want to understand the script, run it line by line!
But of course, I’ll give you a little bit of explanation here:
cut flightdelays.csv -d',' -f1,2,3,15 |sed 's/,/-/' |sed 's/,/-/' |sed 's/,/\t/' > tmp1.csv
First, I have cut the columns I need and formatted the output to be a bit more readable. Then I’ve printed the whole thing into a temporary file.
a=0
while [ $a -le 364 ]
do
i=$a'day'
date -d'2007-1-1'+$i +%Y-%-m-%-d' '%A >> tmp2.csv
a=$((a+1))
done
I’ve printed all the dates in 2007 into another temporary file. I made sure that the date format is the exact same as what I have on my other file (2007-1-1)!
sort tmp1.csv > tmp3.csv
grep 'Monday' tmp2.csv |sort > tmp4.csv
I’ve sorted my temporary files and put them into other temporary files – and at the same time I removed every day but Monday from my date file.
join tmp3.csv tmp4.csv |cut -d' ' -f2 |awk '{sss+=$1} END {print sss}'
Eventually I made the join and calculated the sum of the ArrDelays!
rm tmp1.csv
rm tmp2.csv
rm tmp3.csv
rm tmp4.csv
I’ve also removed all my temporary files (this is gonna be important when you want to run the script for the second time).
The result is, by the way: 11436525
Conclusion
I’ll have some more exercises on bash/command line in the future – maybe in a video format! But for now, I have good news! You made it! You got through all six bash articles and you have learned the essentials of the command line! Now I recommend starting to:
- learn SQL and/or
- learn Python
These tutorials are pretty similar to this one: very easy to understand for everyone, and starting from the very basics.
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester