
As a data scientist or data analyst, sooner or later you’ll come to a point where you have to collect large amounts of data. Be it a hobby project or a freelance job, when APIs are just not available, one of your best options is web scraping… And one of the best web scraping tools is Beautiful Soup!
What is web scraping?
To put it simply, web scraping is the automated collection of data from websites (to be more precise, from the HTML content of websites).
In this article you’ll learn the basics of how to pull data out of HTML. You’ll do that by extracting data from Book Depository’s bestsellers page. To accomplish this, you’ll also have to make use of a little bit of your pandas and Python knowledge.
But enough talking now, let’s walk the walk! 🙂
Meet your new best friends: Beautiful Soup and Requests
Beautiful Soup is one of the most commonly used Python libraries for web scraping. You can install it in the usual way from the command line:
sudo -H pip3 install beautifulsoup4
Note: if you don’t have a server for your data projects yet, please go through this tutorial first: How to Install Python, SQL, R and Bash (for non-devs)
To get the full Beautiful Soup experience, you’ll also need to install a parser. It is often recommended to use lxml for speed, but if you have other preferences (like Python’s built-in html.parser), then feel free to go with that.
Throughout this article, we’ll use lxml, so let’s install it (also from the command line):
sudo -H pip3 install lxml
Nice! One more thing is needed for us to start scraping the web, and it’s the Requests library. With Requests – wait for it – we can request web pages from websites. Let’s install this library, too:
sudo -H pip3 install requests
Now, our setup for web scraping is complete, so let’s scrape our first page, shall we?
Scraping your first web page
In this article, we’ll work with Book Depository’s first page of its bestsellers list.
IMPORTANT UPDATE 2023-05-02: Book Depository has unfortunately closed. We are sorry to see that for two reasons. 1) It was a great online store. 2) This article was based on their e-commerce store’s online data. Until we update the article, please note that the methods described in this article still work, but they won’t work with Book Depository specifically from now on, for obvious reasons.
Keep in mind that this list is updated daily, so it is highly likely that you’ll see different books from these:
But don’t lose sleep over it: you’ll fully be able to follow and complete this tutorial regardless of what books you scrape. 🙂
Disclaimer: this article is for educational purposes only and we use Book Depository as an example — because we love their website and their service. Although web scraping isn’t illegal, if you want to do it at scale or to profit from it in any way (e.g. building a startup around a web scraping solution), we recommend speaking to a qualified legal advisor.
Disclaimer 2: We are not affiliated with Book Depository in any way.
So without further ado, let’s fire up a Jupyter Notebook and import the libraries we’ve just installed (except for lxml, it doesn’t have to be imported):
from bs4 import BeautifulSoup as bs
import requests
Now, we’re ready to request our first web page. It’s nothing complicated – we save the URL we want to scrape to the variable url, then request the URL (requests.get(url)), and save the response to the response variable:
url = "https://www.bookdepository.com/bestsellers"
response = requests.get(url)
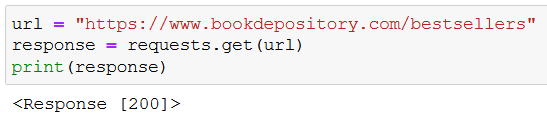
By printing response, you can see that the HTTP response status code is 200, which means that the request for the URL was successful:
But we need the HTML content of the requested web page, so as the next step we save the content of response to html:
html = response.content
Again, print out what we’ve got with print(html):
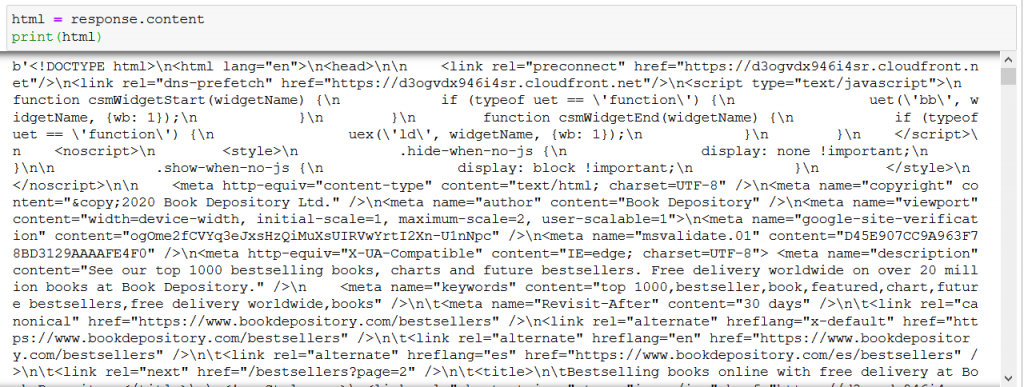
The result is the HTML content of the bestsellers’ page, but it is really hard to read with the human eye… :/
Lucky for us, we’ve got Beautiful Soup and lxml! 🙂
Let’s create a Beautiful Soup object named soup with the following line of code:
soup = bs(html, "lxml")
Remember, we imported Beautiful Soup as bs, this is the bs() part of the code. The first parameter of the bs() method is html (which was the variable where we saved that hard-to-read HTML content from the fetched bestsellers URL), the second parameter (“lxml”) is the parser that is used on the html variable.
The result is soup (a parsed HTML document) which is much more pleasing to the eye:
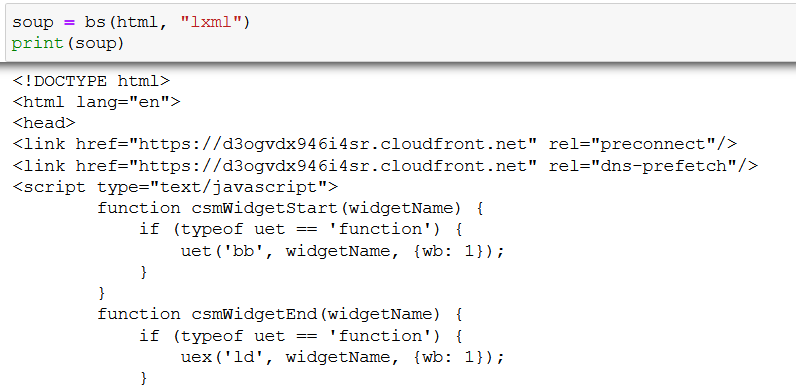
Not only is it satisfying to look at, but soup also gives us a nested data structure of the original HTML content that we can easily navigate and collect data from.
How?
Continue reading to find out.
How to navigate a Beautiful Soup object
First, let’s go over some HTML basics (bear with me, we’ll need this to navigate our soup object).
HTML consists of elements like links, paragraphs, headings, blocks, etc. These elements are wrapped between tags; inside the opening and the closing tag can be found the content of the element.
For instance, a sentence on a web page (in a paragraph (<p>) element) looks like this (only the content is visible for us humans):

HTML elements may also have attributes that contain additional information about the element. Attributes are defined in the opening tags with the following syntax: attribute name=”attribute value”.
An example:

Now that we’ve learned to speak some basic HTML, we can finally start to extract data from soup. Just type a tag name after soup and a dot (like soup.title), and watch magic unfold:

Let’s try another one (soup.h1):

If you don’t need the full element, just the text, you can do that, too with .get_text():

What if you need only an element’s attribute? No problem:

Or another way to do the same task:

Whether you noticed or not, the soup.any_tag_name syntax returns only the first element with that tag name. Instead of soup.any_tag_name, you can also use the .find() method, and you’ll get the exact same result:

Oftentimes you need not just one, but all elements (for example every link on a page). That’s what the .find_all() method is good for:
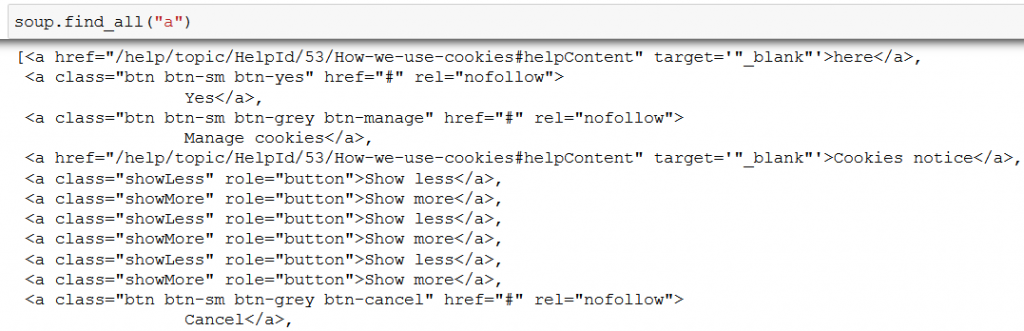
(Actually, .find_all() is so popular that there’s a shortcut for it: soup(“tag_name”), like soup(“a”) in our case.)
What you have to know is that while .find() returns only one element, .find_all() returns a list of elements, which means you can iterate over it:

(In this example I intentionally printed only the first 5 links.)
After all this you’re equipped with enough knowledge to get some more serious tasks done with Beautiful Soup. So let’s do just that, and continue to the next section. 🙂
How to extract data with Beautiful Soup
Within our soup object we already have the parsed HTML content of Book Depository’s bestsellers page. The page contains 30 books with information related to them. Of the available data we’ll extract the following:
- book titles,
- formats (paperback or hardback),
- publication dates,
- prices.
While working with BeautifulSoup, the general flow of extracting data will be a two-step approach: 1) inspecting in the browser the HTML element(s) we want to extract, 2) then finding the HTML element(s) with BeautifulSoup.
Let’s put this approach into practice.
1. Getting the book titles (find_all + get_text)
This one will be really easy – right click on one of the books’ titles, and choose Inspect Element in Firefox (or Inspect in Chrome):
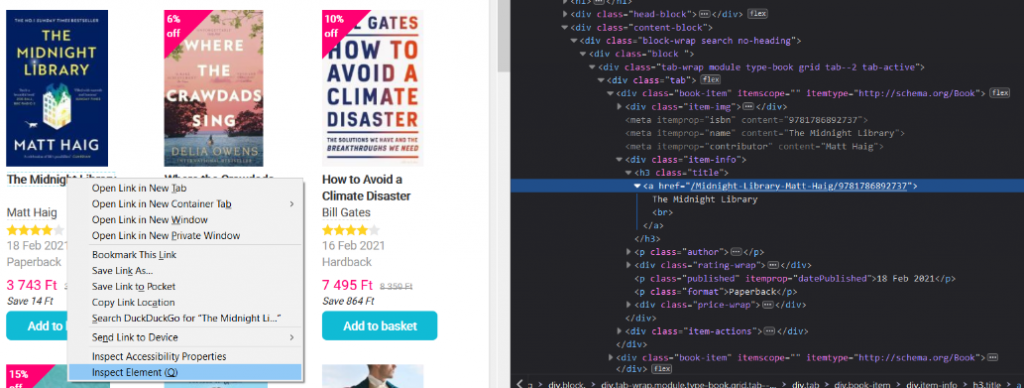
As you can see, the book title is a text in an a element within an h3 element with the class=”title” attribute. We can translate this into Beautiful Soup “language”:
all_h3 = soup.find_all("h3", class_="title")
for h3 in all_h3:
print(h3.get_text(strip=True))
And this is what you get after running the above code:
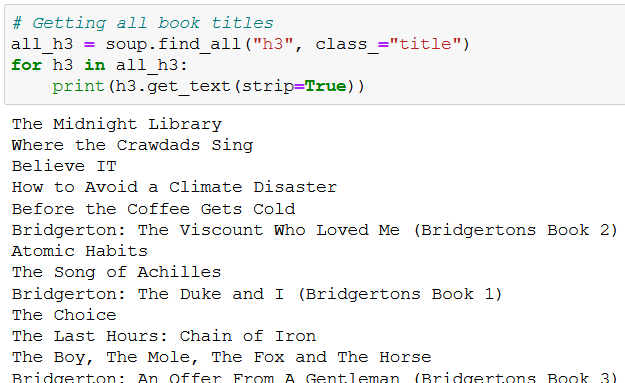
soup.find_all(“h3”) finds every h3 element on the web page; with class_=”title” we specify that we specifically search for h3 tags that contain the class_=”title” attribute (important note: the “_” in class_=”title” is not a typo, it is required in Beautiful Soup when selecting class attributes).
We save the h3 elements to all_h3, which behaves like a list, so we can loop over it with a for loop. At each iteration we pull out only the text from the h3 element with .get_text(), and with the strip=True parameter we make sure to remove any unnecessary whitespace.
Note: If you print out the book titles, in some cases you’ll see titles that are not present on the bestsellers page. Probably it’s a location based personalization thing. Anyway, don’t worry about it, it’s a normal thing. You won’t always encounter this phenomenon, but I thought it was good for you to know that it could happen from time to time. 🙂
2. Getting the book formats
From the previous step we have all book titles from the bestsellers page. But what do we know about their formats – are there more paperback or hardback bestseller books?
Let’s find out by inspecting the book format element:
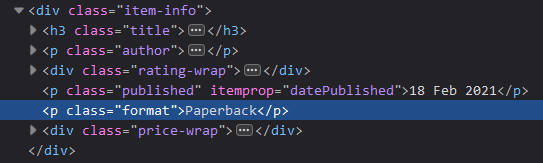
The format data is a paragraph element with class=”format”, and it’s inside a div element with the class=”item-info” attribute. It’s Beautiful Soup time again:
# From now on we’ll use pandas too, so let’s import it now
import pandas as pd
formats = soup.select("div.item-info p.format")
formats_series = pd.Series(formats)
formats_series.value_counts()
It’ll look like this:
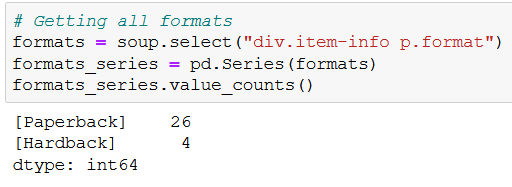
Nice – there are 26 paperbacks and 4 hardbacks on the page. But what is that .select() method and where did .find_all() disappear to?!
.select() is similar to .find_all(), but with it you can find HTML elements using CSS selectors (a handy thing to learn as well).
Basically div.item-info p.format means the following: find all paragraph elements with the class of format that are inside of a div element with the class of item-info.
(.select() is a useful little thing to add to your Beautiful Soup arsenal. 😉 )
The rest of the code uses pandas to count the occurrences of each book format. If you need a refresher on pandas, you should definitely click here (after finishing this article, of course).
3. Getting the publication dates (find_all + get_text)
The same approach applies to extracting the publication dates as well. First, we inspect the element:
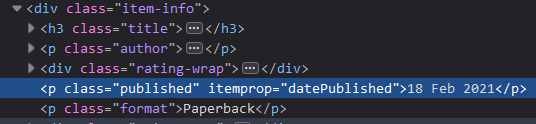
Then we write the Beautiful Soup code to collect the data:
dates = soup.find_all("p", class_="published")
dates = [date.get_text()[-4:] for date in dates]
dates_series = pd.Series(dates)
dates_series.value_counts()
Here’s what you’ll get:
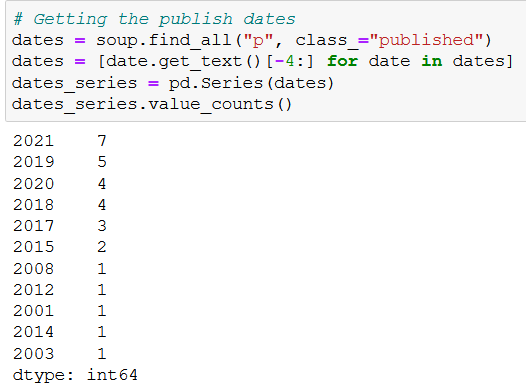
As you can see, it is just a basic .find_all(), nothing new you don’t already know. 😉
But perhaps the rest of the code needs some explaining, so here it goes:
- because
.find_all()creates aResultSetobject, we can’t immediately get the text from the elements in (the first)datesvariable, - so with the help of a list comprehension and
.get_text()we create a list with only the content of the paragraph elements (like 18 Feb 2021), - but we only need the year, which is the last four characters of the text (
.get_text()[-4:]), - then it’s the same steps from the previous section: we create a
pandasseries and count the values (.value_counts()).
4. Getting the prices (find_all + get_text)
This one will be a bit trickier, because a book has either only one (selling) price or two prices at the same time (an original and a discounted/selling price):

In either case, we’ll collect only the selling prices, but before we do that, please set the currency to euro at the top right side of the page (the page will automatically refresh itself):
After a quick check, we’ll find the HTML element for the original price:
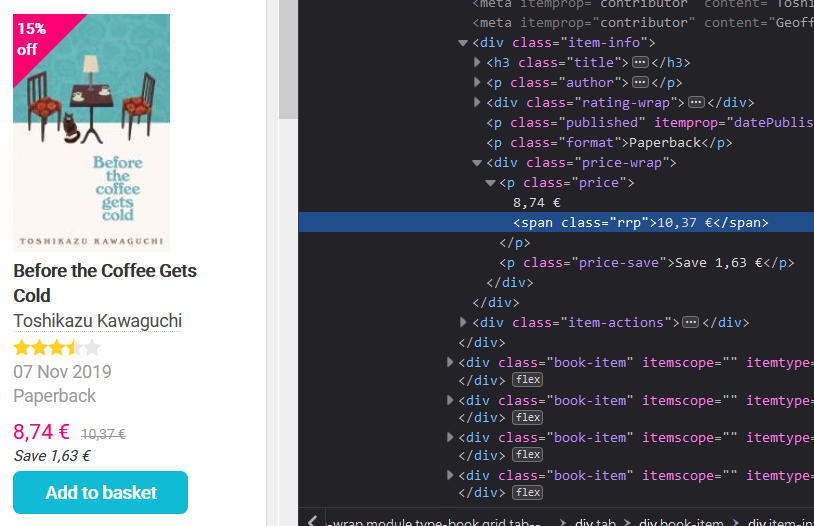
And the selling/discounted price, too:
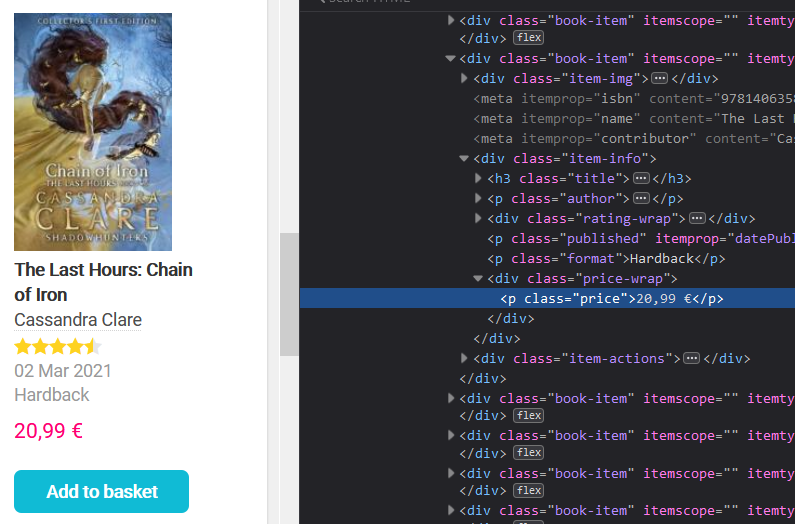
To get the selling prices, we’ll need to run the following lines of code:
final_prices = []
prices = soup.find_all("p", class_="price")
for price in prices:
original_price = price.find("span", class_="rrp")
if original_price:
current_price = str(original_price.previousSibling).strip()
current_price = float(current_price.split("€")[0].replace(",", "."))
else:
current_price = float(price.get_text(strip=True).split("€")[0].replace(",", "."))
final_prices.append(current_price)
If you run the above code and print out final_prices, you’ll see the discounted/selling prices of the books:

And here’s what the code does line by line:
- We create a list (
final_prices = []) to hold the selling prices. - Then we find the HTML elements that contain the books’ prices:
prices = soup.find_all("p", class_="price") - Now we loop through
prices:for price in prices- We save the original price (
original_price = price.find("span", class_="rrp")); it’ll look like this: <span class=”rrp”>19,10 €</span> - If there’s an original price (
if original_price:) in the HTML element, then:- We retain only the discounted/selling price, and save it to
current_price(which looks like this: ‘16,88 €’):current_price = str(original_price.previousSibling).strip() - Then we replace “,” with “.”, and remove the ” €” part, and convert the result to a float type (the result will look like this: 16.88):
current_price = float(current_price.split("€")[0].replace(",", "."))
- We retain only the discounted/selling price, and save it to
- But if there’s no original price, then (
else:) we replace “,” with “.”, and remove the ” €” part, and convert the result to a float type (it’ll look like this 10.27):current_price = float(price.get_text(strip=True).split("€")[0].replace(",", ".")) - Finally, we add only the selling prices to the
final_priceslist:final_prices.append(current_price)
- We save the original price (
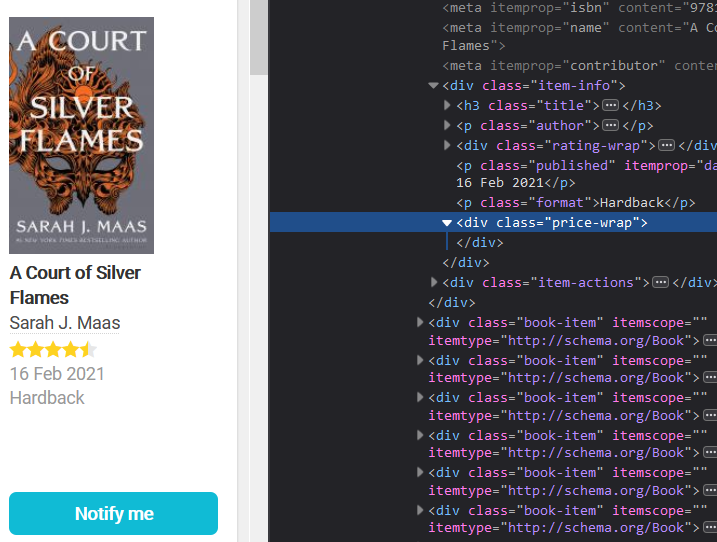
Of course, if a book is sold out, there’ll be no HTML element that holds the price of that book, so our code won’t include it in the final_prices list. Here’s what such a book would look like:
And some dataviz… (adding a histogram)
Based on final_prices, we can easily create a basic histogram out of our data with the following lines of code:
Note: For this code to work, don’t forget to import numpy and matplotlib… And if you work in Jupyter Notebook, don’t forget to add this line as well.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
s_final_prices = pd.Series(final_prices)
plt.figure(figsize=(10, 6))
plt.xticks(np.arange(0, 40, step=2))
plt.yticks(np.arange(0, 11, step=1))
plt.xlabel("Book prices in euro", fontsize = 12)
plt.ylabel("Number of books", fontsize = 12)
s_final_prices.hist(bins=15)
And here’s the result:
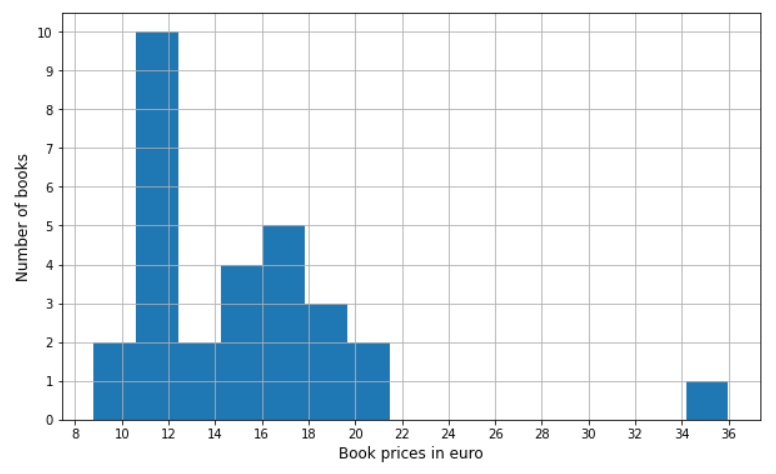
A quick glance at the histogram, and it is easy to see that the most frequent price of bestsellers is somewhere between 11-12.5 €. Cool, isn’t it? 🙂
Conclusion
Give yourself a big pat on the back, because you’ve just scraped your first web page. 🙂 I hope you had some fun reading this article, but what I hope even more is that you gained skills that you’ll proudly make use of later.
Now, have some well-deserved rest, and let your freshly acquired knowledge sink in.
And when you’re ready – and when the next article in this tutorial series will be published – do come back, because we’ll step up your web scraping game even more. No spoilers, but yeah… we will scrape multiple web pages, we will do deeper analyses — it’s gonna be a lot of fun! 😎
- If you want to learn more about how to become a data scientist, take Tomi Mester’s 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out the 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tamas Ujhelyi