
Running hobby projects is the best way to practice data science before getting your first job. And one of the best ways to get real data for a hobby project is: web scraping.
I’ve been promising this for a long time to my course participants – so here it is: my web scraping tutorial series for aspiring data scientists!
I’ll show you step by step how you can:
- scrape a public html webpage
- extract the data from it
- write a script that automatically scrapes thousands of public html webpages on a website
- create useful (and fun) analyses from the data you get
- analyze a huge amount of text
- analyze website metadata
This is episode #1, where we will focus on step #1 (scraping a public html webpage). And in the upcoming episodes we will continue with step #2, #3, #4, #5 and #6 (scaling this up to thousands of webpages, extracting the data from them and analyzing the data we get).
Even more, I’ll show you the whole process in two different data languages, too, so you will see the full scope. In this article, I will start with the simpler one: bash. And in future articles, I’ll show you how to do similar things in Python, as well.
So buckle up! Web scraping tutorial episode #1 — here we go!
Before we start…
This is a hands-on tutorial. I highly recommend doing the coding part with me (and doing the exercises at the end of the articles).
I presume that you have some bash coding knowledge already — and that you have your own data server set up already. If not, please go through these tutorials first:
- How to install Python, R, SQL and bash to practice data science!
- Introduction to Bash episode #1
- Introduction to Bash episode #2
- Introduction to Bash episode #6
The project: scraping TED.com and analyze talks
When you run a data science hobby project, you should always pick a topic that you are passionate about.
As for me: I love public speaking.
I like to practice it myself and I like to listen to others… So watching TED presentations is also a hobby for me. Thus I’ll go ahead and analyze TED presentations in this tutorial.
Luckily, almost if not all TED presentations are already available online.
…
Even more, their transcripts are available, too!
…
(Thank you TED!)
So we’ll “just” have to write a bash script that collects all those transcripts for us and we can start our in-depth text analysis.
Note 1: I picked scraping TED.com just for the sake of example. If you are passionate about something else, after finishing these tutorial articles, try to find a web scraping project that resonates with you! Are you into finance? Try to scrape stock market news! Are you into real estate? Then scrape real estate websites! Are you a movie person? Your target could be imdb.com (or something similar)!
Login to your remote server!
Okay, so one more time: for this tutorial, you’ll need a remote server. If you haven’t set one up yet, now is the time! 🙂
Note: If — for some reason — you don’t like my server setup, you can use a different environment. But I strongly advise against it. Using the exact same tools that I use will guarantee that everything you read here will work on your end, too. So one last time: use this remote server setup for this tutorial.
Okay, let’s say that you have your server. Great!
Now open Terminal (or Putty) and log in with your username and IP address.
If everything’s right, you should see the command line… Something like this:
Introducing your new favorite command line tool: curl
Interestingly enough, in this whole web scraping tutorial, you will have to learn only one new bash command. And that’s curl.
curl is a great tool to access a website’s whole html code from the command line. (It’s good for many other server-to-server data transfer processes — but we won’t go there for now.)
Let’s try it out right away!
curl https://www.ted.com/
The result is:
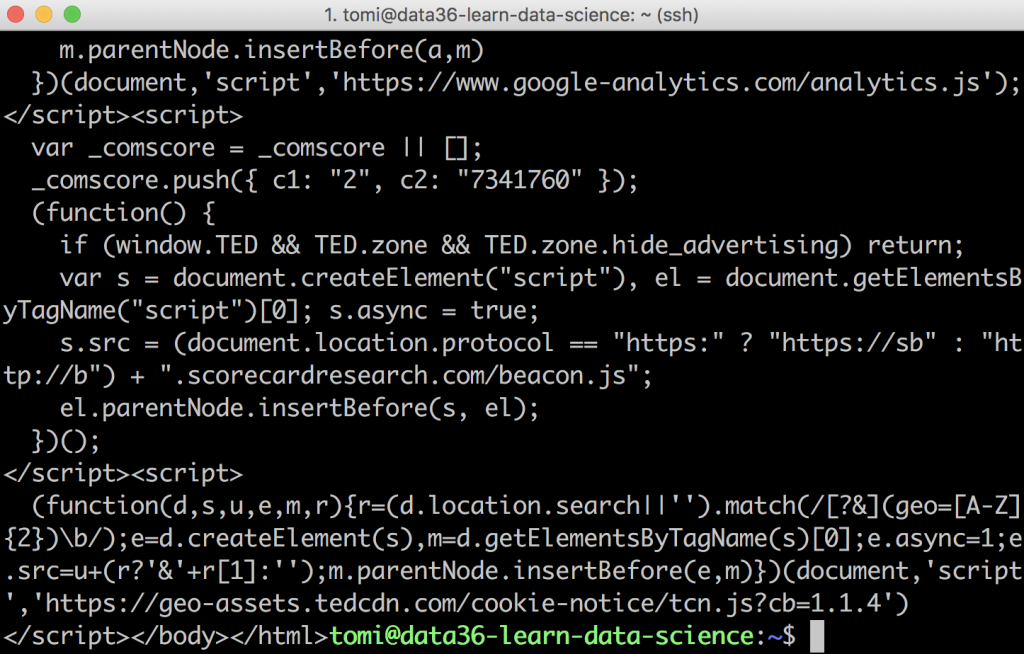
Oh boy… What’s this mess??
It’s the full html code of TED.com — and soon enough, I’ll explain how to turn this into something more meaningful. But before that, something important.
As you can see, to get the data you want, you’ll have to use that exact URL where the website content is located — and the full version of it. So, for instance this short form won’t work:
curl ted.com
It just doesn’t return anything:
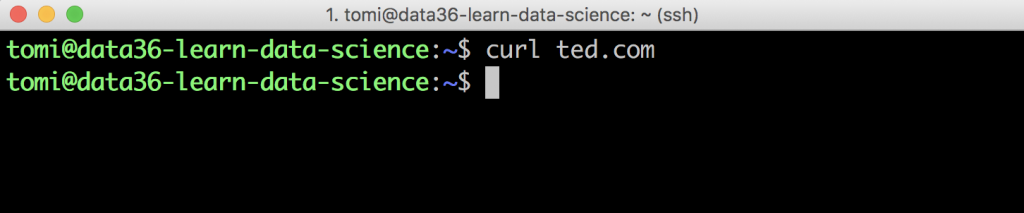
And you’ll get similar empty results for these:
curl www.ted.com
curl http://www.ted.com
Even when you define the https protocol properly but you miss the www part, you’ll get a short error message that your website content “has been moved”:
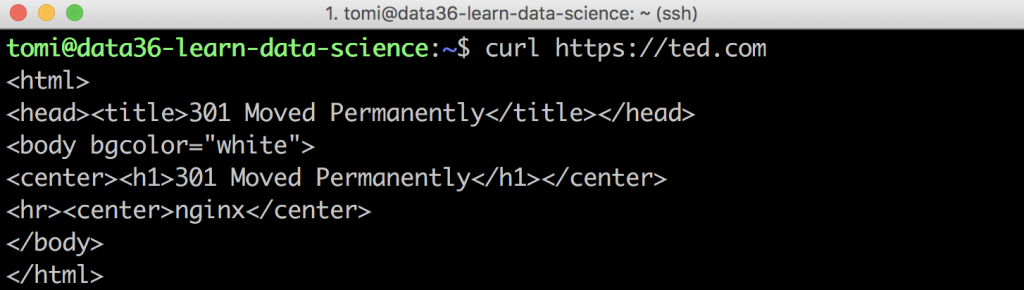
So make sure that you type the full URL and you use the one where the website is actually located. This, of course, differs from website to website. Some use the www prefix, some don’t. Some still operate under the http protocol — most (luckily) use https.
A good trick to find the URL you need is to open the website in your browser — and then simply copy-paste the full URL from there into your Terminal window:
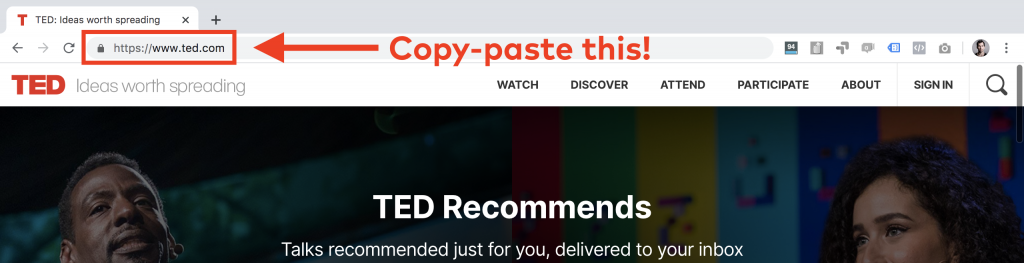
So in TED’s case, it will be this:
curl https://www.ted.com
But, as I said, I don’t want to scrape the TED.com home page.
I want to scrape the transcripts of the talks. So let’s see how to do that!
curl in action: downloading one TED talk’s transcript
Obviously, the first step in a web scraping project is always to find the right URL for the webpage that you want to download, extract and analyze.
For now, let’s start with one single TED talk. (Then in the next episode of this tutorial, we’ll scale this up to all 3,300 talks.)
For prototyping my script, I chose the most viewed speech — which is Sir Ken Robinson’s “Do schools kill creativity.” (Excellent talk, by the way, I highly recommend watching it!)
The transcript itself is found under this URL:
https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript
So you’ll have to copy-paste this to the command line — right after the curl command:
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript
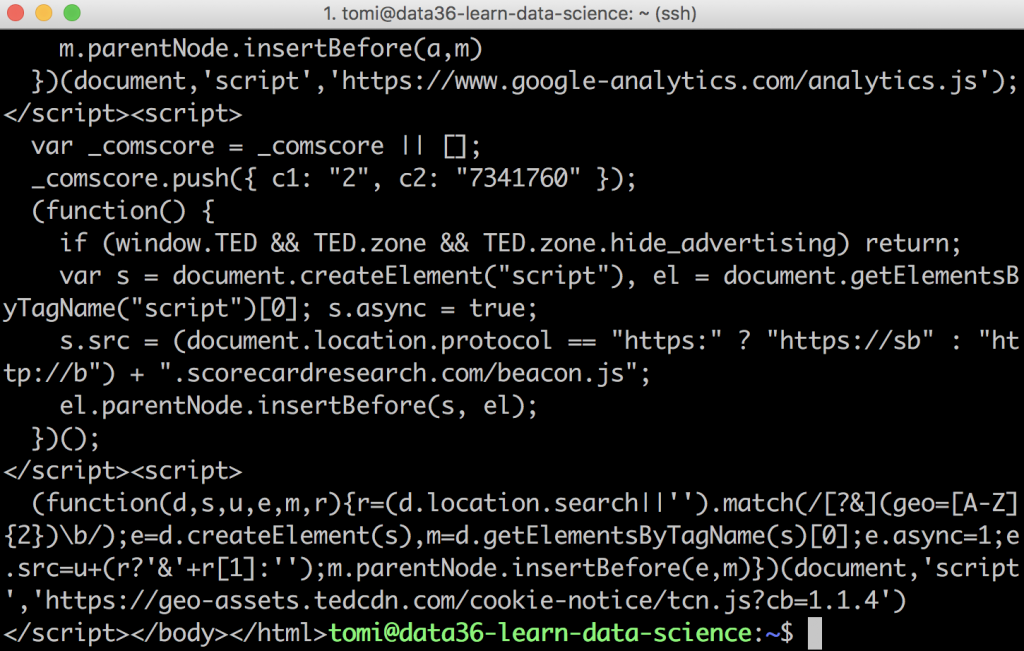
Great!
We got our messy html code again — but this actually means that we are one step closer.
If you scroll up a bit in your Terminal window, you’ll recognize parts of the speech there:
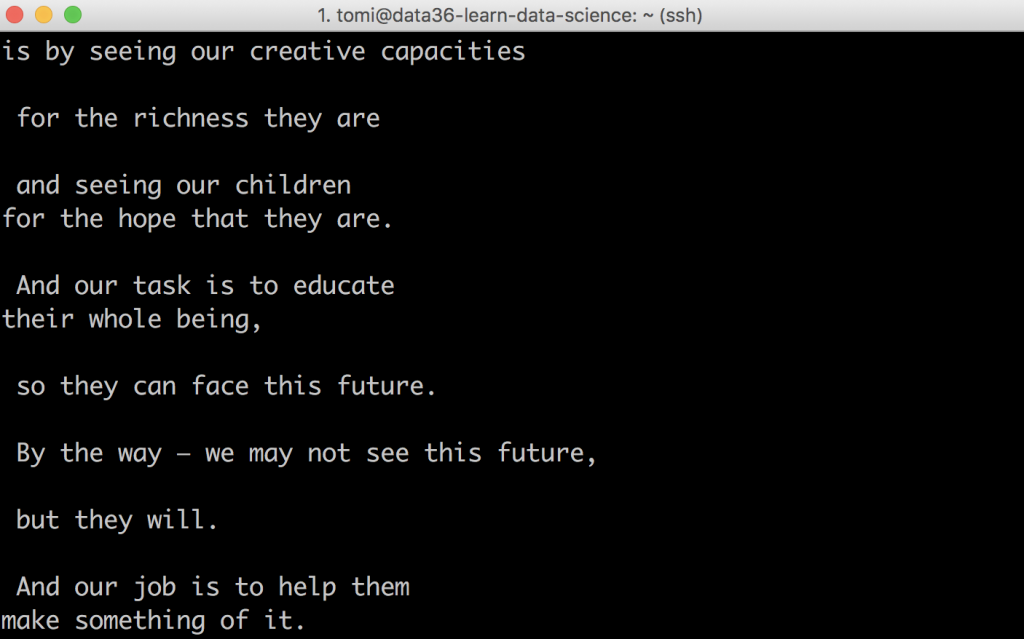
This is not (yet) the most data-analysis-friendly format but we will clean this out very quickly.
Your other favorite web scraping command line tool: html2text
Remember that I said that you’ll have to learn only one new bash command in this web scraping tutorial? Well, strictly speaking that was true because this other command is not a must… But it will make your life so much easier. So let’s just get a grasp on this one as well!
It’s called html2text and it’s designed to clean your data of html codes and return only the useful content (the text we want to analyze) to your screen.
Unfortunately, html2text is not part of your current server setup (it’s not a built-in tool), so before you use it for the first time, you’ll have to install it. (No big deal though. It takes like 10 seconds.)
Type this to your command line:
sudo apt-get install html2text
It will ask for your password (type it!) and then it will quickly install the html2text tool to your server.
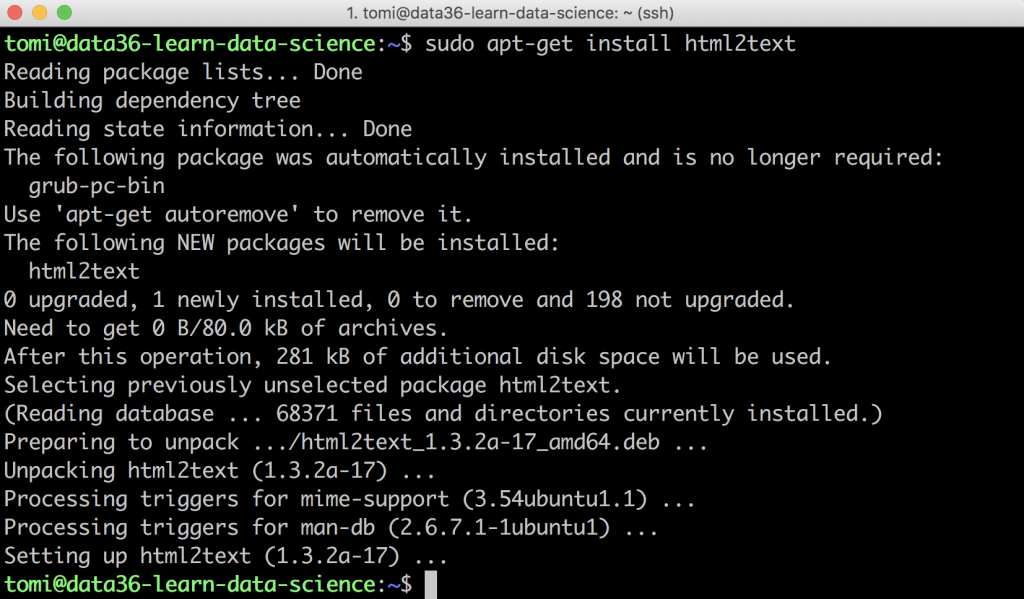
Nice! Let’s see it in action!
Cleaning the data of the .html file
Rerun your previous curl command — but this time let’s put the html2text command with a pipe (|) after it, too.
Type this:
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text
You get your result returned to your screen.
Scroll up a bit and you’ll see this:
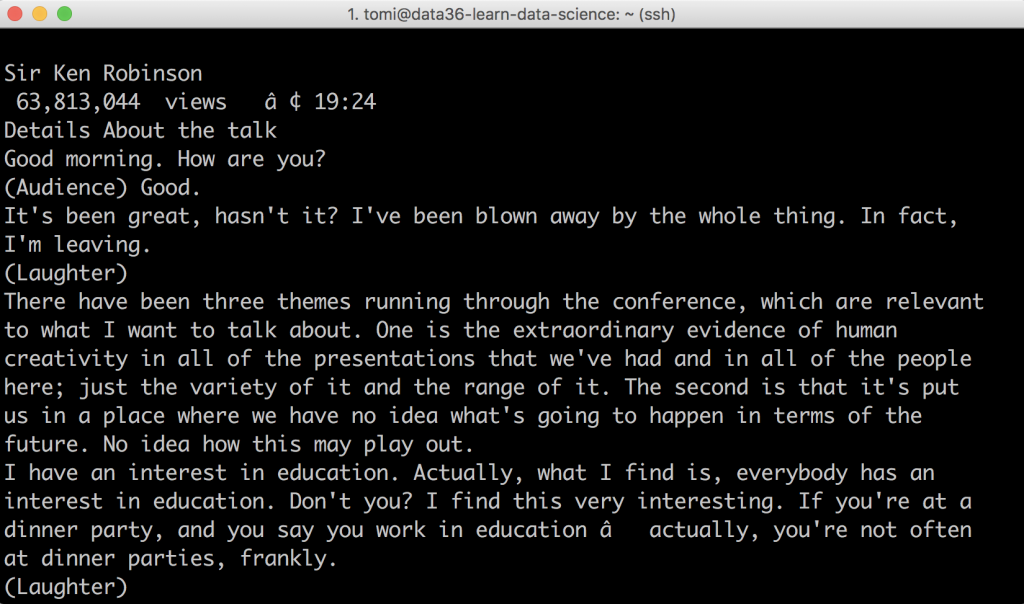
Isn’t it lovely?
The whole transcript of Sir Ken’s TED talk — only in your Terminal window, ready for analysis! (You can double-check it and collate it to what you see on the original website.)
Well, almost ready for analysis.
Actually, if you scroll through the whole data that you have downloaded, you’ll still see some text-snippets that you won’t need.
For example, before the transcript you’ll see this:
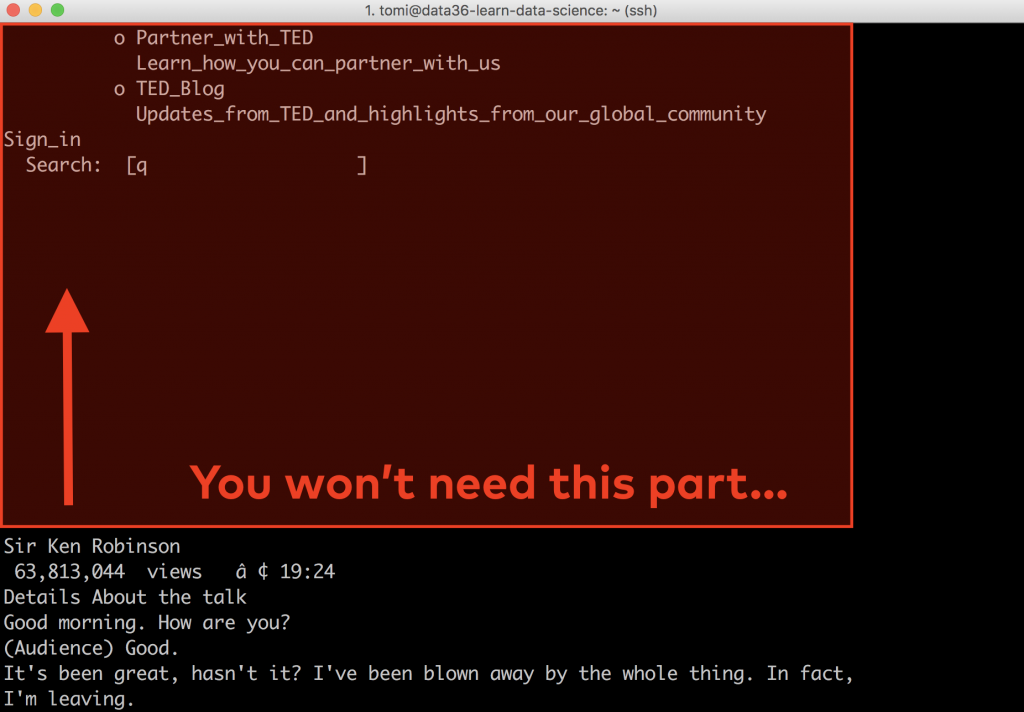
And after the transcript, you’ll see this:
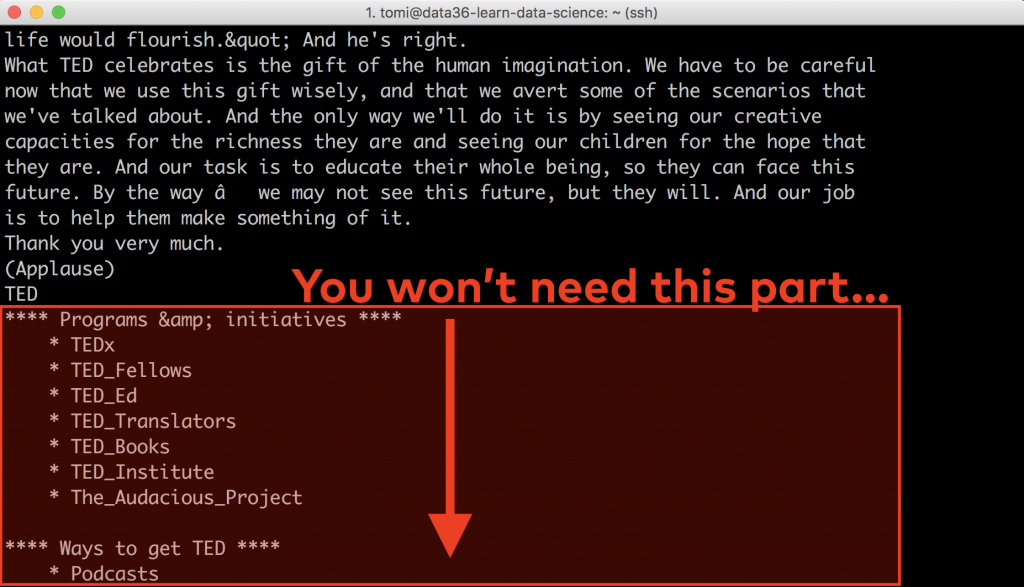
See, when you scrape a website, you scrape its entire contents. This time the texts of the top menu, the footer menu and side menu got included, too. You won’t need them, so the next step will be to get rid of them.
Removing the unnecessary parts of the data (by using the sed command)
We’ll try to find a pattern that’s similar for every single transcript webpage on TED.com and that clearly borders where the useful part of our content (the actual transcript of the talk) starts and ends.
It’s time for data discovery!
Let’s download a few more talks, compare them and figure out what these patterns could be:
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text
curl https://www.ted.com/talks/amy_cuddy_your_body_language_may_shape_who_you_are/transcript | html2text
curl https://www.ted.com/talks/james_veitch_this_is_what_happens_when_you_reply_to_spam_email/transcript | html2text
Lucky for us, it is pretty clear and straightforward:
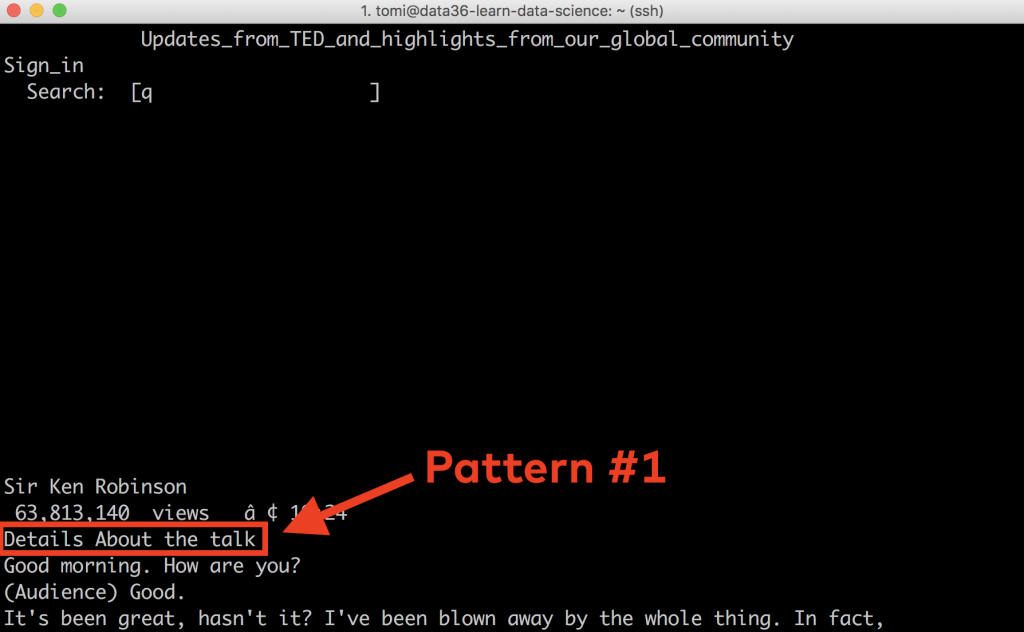
We will have to remove everything before the Details About the talk line because that’s where the transcripts start.
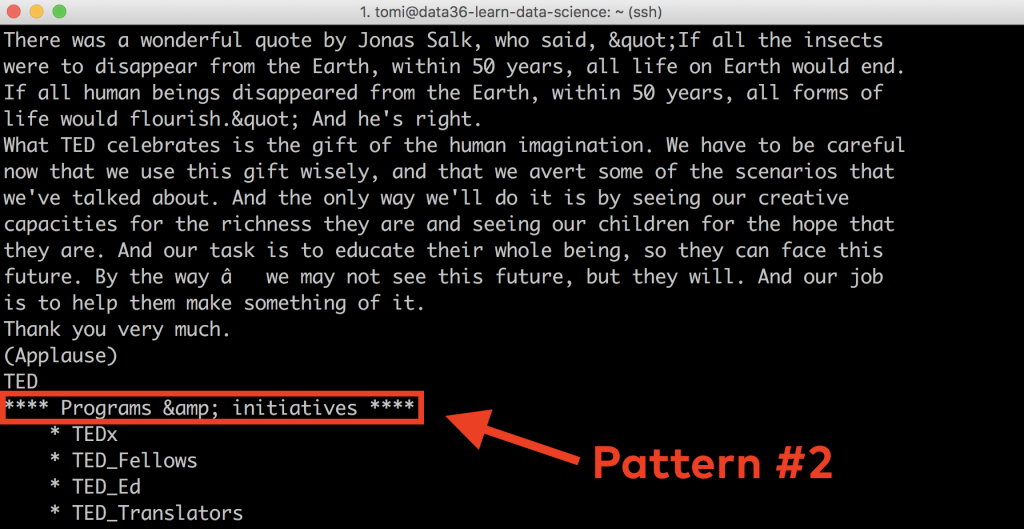
And we will have to remove everything after the **** Programs &. initiatives **** line (including that one as well) as that’s where the transcript ends.
In one of my previous bash tutorials, I have already written about a great command line tool: sed.
For these tasks, sed will become handy for us again!
To remove all the lines before a given line in a file, you’ll have to use this code:
sed -n '/[the pattern itself]/,$p'
And to remove all the lines after a given line in a file, this is the code:
sed -n '/[the pattern itself]/q;p'
Note: this one will remove the line with the pattern, too!
Side note:
Now, of course, if you don’t know sed inside out, you couldn’t figure out these code snippets by yourself. But here’s the thing: you don’t have to, either!
If you build up your data science knowledge by practicing, it’s okay to use Google and Stackoverflow and find answers to your questions online. Well, it’s not just okay, you have to do so!
E.g. if you don’t know how to remove lines after a given line in bash, type this into Google:

The first result brings you to Stackoverflow — where right in the first answer there are three(!) alternative solutions for the problem:
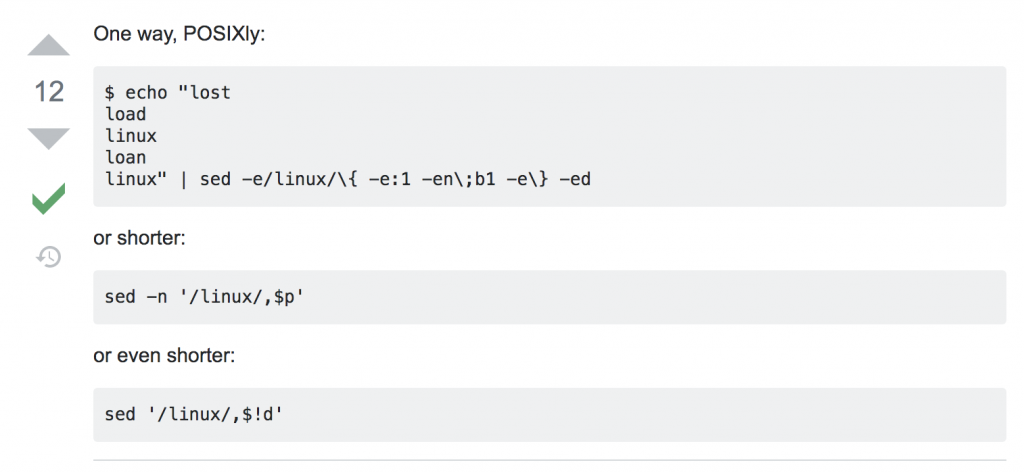
Who says learning data science by self-teaching is hard nowadays?
Okay, pep-talk is over, let’s get back to our web scraping tutorial!
Let’s replace the [the pattern itself] parts in your sed commands with the patterns we’ve found above — and then add them to your command using pipes.
Something like this:
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text | sed -n '/Details About the talk/,$p' | sed -n '/Programs &. initiatives/q;p'
Note 1: I used line breaks in my command… but only to make my code nicer. Using line breaks is optional in this case.
Note 2: In the Programs &. initiatives line, I didn’t add the * characters to the pattern in sed because the line (and the pattern) is fairly unique without them already. If you want to add them, you can. But you’ll have to know that * is a special character in sed, so to refer to it as a character in your text, you’ll have to “escape” it with a backslash first. The code would look like this: sed -n '/\*\*\*\* Programs &. initiatives \*\*\*\*/q;p'
Again, this won’t be needed anyway.
Let’s run the command and check the results!
If you scroll up, you’ll see these at the beginning of the returned text (without the annotations, of course):
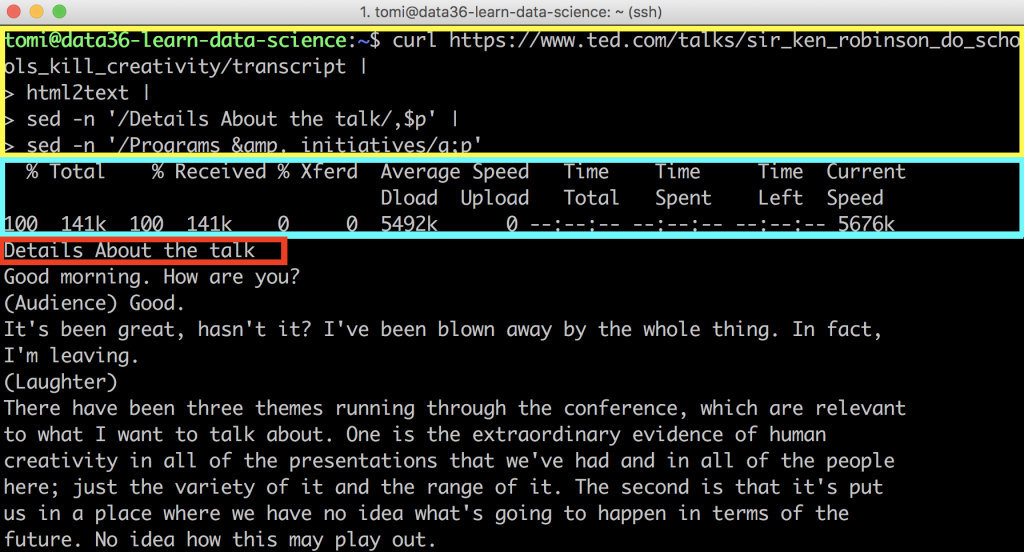
Before you start to worry about all the chaos in the first few lines…
- The part that I annotated with the yellow frame: that’s your code. (And of course, it’s not a part of the returned results.)
- The part with the blue frame: that’s only a “status bar” that shows how fast the web scraping process was — it’s on your screen but it won’t be part of the downloaded webpage content, either. (You’ll see this clearly soon, when we save our results into a file!)
However, the one with the red frame (Details about the talk) is something that is part of the downloaded webpage content… and you won’t need it. It’s just left there, so we will remove it soon.
But first, scroll back down!
At the end of the file the situation is cleaner:
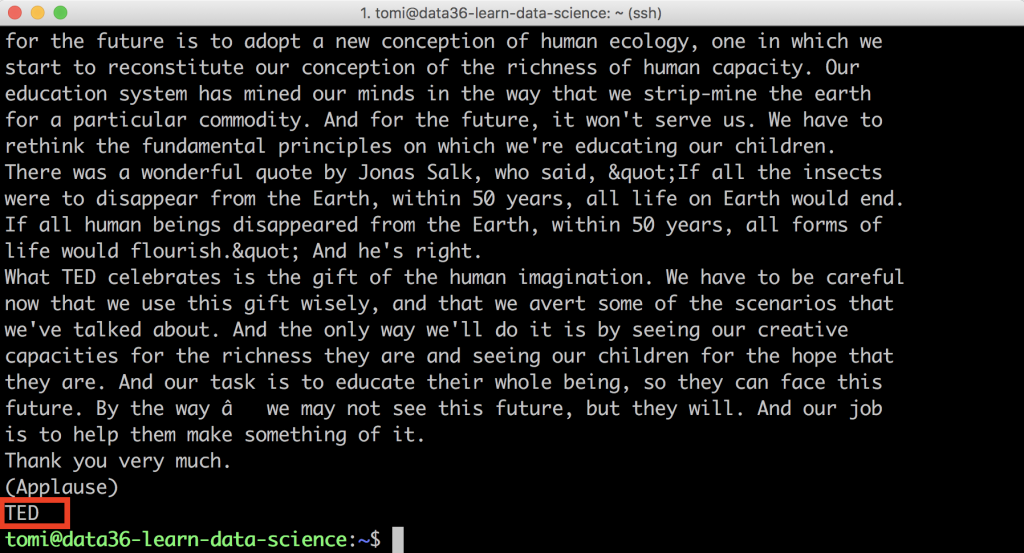
We only have one unnecessary line left there that says TED.
So you are almost there…
Removing first and last lines with the head and tail commands
And as a final step, remove the first (Details About the talk) and the last (TED) lines of the content you currently see in Terminal! These two lines are not part of the original talk… and you don’t want them in your analyses.
For this little modification, let’s use the head and tail commands (I wrote about them here).
To remove the last line, add this code: head -n-1
And to remove the first line, add this code: tail -n+2
And with that, this will be your final code:
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text | sed -n '/Details About the talk/,$p' | sed -n '/Programs &. initiatives/q;p' | head -n-1 | tail -n+2
You can try it out…
But I recommend to save this into a file first, so you will be able to reuse the data you got in the future.
curl https://www.ted.com/talks/sir_ken_robinson_do_schools_kill_creativity/transcript | html2text | sed -n '/Details About the talk/,$p' | sed -n '/Programs &. initiatives/q;p' | head -n-1 | tail -n+2 > proto_text.csv
If you print this freshly created proto_text.csv file to your screen, you’ll see that you have beautifully downloaded, cleaned and stored the transcript of Sir Ken Robinson’s TED talk:
cat proto_text.csv
And with that you’ve finished the first episode of this web scraping tutorial!
Nice!
Exercise – your own web scraping mini-project
Now that you have seen how a simple web scraping task is done, I encourage you to try this out yourself.
Pick a simple public .html webpage from the internet — anything that interests you — and do the same steps that we have done above:
- Download the .html site with
curl! - Extract the text with
html2text! - Clean the data with
sed,head,tail,grepor anything else you need!
The third step could be especially challenging. There are many, many types of data cleaning issues… But hey, after all, this is what a data science hobby project is for: solving problems and challenges! So go for it, pick a webpage and scrape it! 😉 And if you get stuck, don’t be afraid to go to Google or Stackoverflow for help!
Note 1: Some big (or often-scraped) webpages block web scraping scripts. If so, you’ll get a “403 Forbidden” message returned to your curl command. Please consider it as a “polite” request from those websites and try not to find a way around to scrape their website anyway. They don’t want it — so just go ahead and find another project.
Note 2: Also consider the legal aspect of web scraping. Generally speaking, if you use your script strictly for a hobby project, this probably won’t be an issue at all. (This is not official legal advice though.) But if it becomes more serious, just in case, to stay on the safe side, consult a lawyer, too!
Web Scraping Tutorial – summary and the next steps
Scraping one webpage (or TED talk) is nice…
But boring! 😉
So in the next episode of this web scraping tutorial series, I’ll show you how to scale this up! You will write a bash script that – instead of one single talk – will scrape all 3,000+ talks on TED.com. Let’s continue here: web scraping tutorial, episode #2.
And in the later episodes, we will focus on analyzing the huge amount of text we collected. It’s going to be fun! So stay with me!
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester