
Data Coding in Bash – this is episode 4! Let’s continue with some basic bash best practices. Today I’ll show you 9 tips that will make your data coding life in the command line much easier.
This week I’ll also start experimenting with video format. Feel free to give feedback about whether you liked it or not. I suggest you first watch the video, and I’ll list the tools and commands below anyway. So you can jump on your Terminal and try them after watching the vid!
Note: If you are new here, I suggest starting with these previous data coding and/or bash articles:
- Data Coding 101 – Install Python, R, SQL and bash!
- Data Coding 101 – Intro to Bash ep#1
- Data Coding 101 – Intro to Bash ep#2
- Data Coding 101 – Intro to Bash ep#3
And here’s the video:
Do Bash + Data Coding Faster!
Bash best practice #1 – Tab key
Any time you start typing in the command line and you hit the TAB key, it automatically extends your typed-in text, so you can spare some characters.

Bash best practice #2 – Up/down arrows
They help you to bring back your previous commands. So if you misspelled something or if you want to make a small modification, you don’t have to type the whole command again.

Bash best practice #3 – history
history –» This bash command prints your recently used commands on your terminal screen. (Pro tip: try it with grep! E.g. history |grep 'cut' will list all the commands you have used that contained cut.)
Bash best practice #4 – CTRL + R
CTRL + R or clear: It cleans your screen. Better for your mind, better for your eyes!

Do Bash + Data Coding More Cleanly!
First install CSVKit!sudo pip install csvkit
Note: I first heard about the CSVKit bash tools in this book: Jeroen Janssen – Data Science at the Command Line.
Then try csvlook and csvstat:
Bash best practice #5 – csvlook
csvlook helps you to see your csv files in a much cleaner, much processable-by-humans format. E.g. here’s a short sample from our flightdelays.csv file:cat 2007.csv | head | cut -d',' -f12,13,14,15 | csvlook
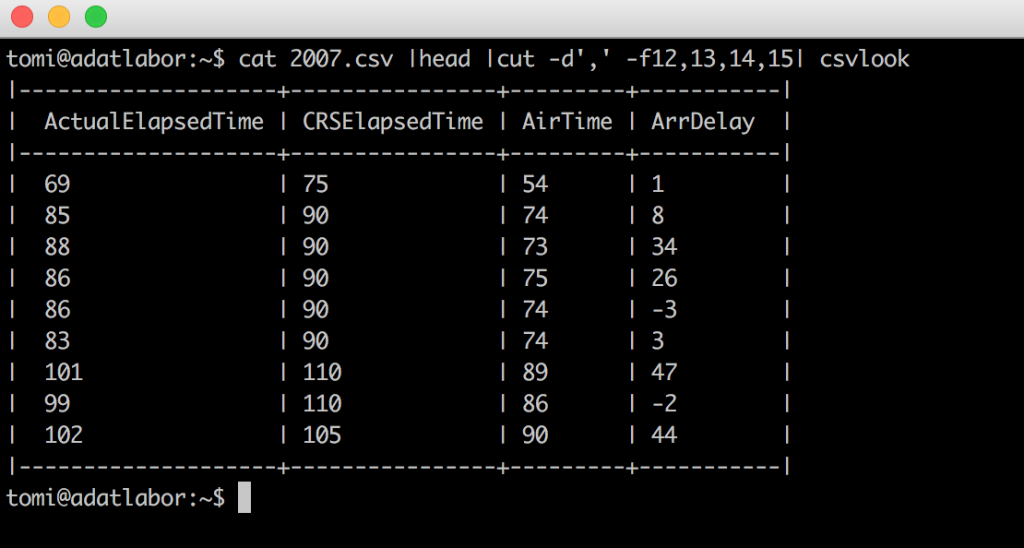
Bash best practice #6 – csvstat
csvstat returns some basic statistics about your dataset. Try:cat demo1.csv | csvstat
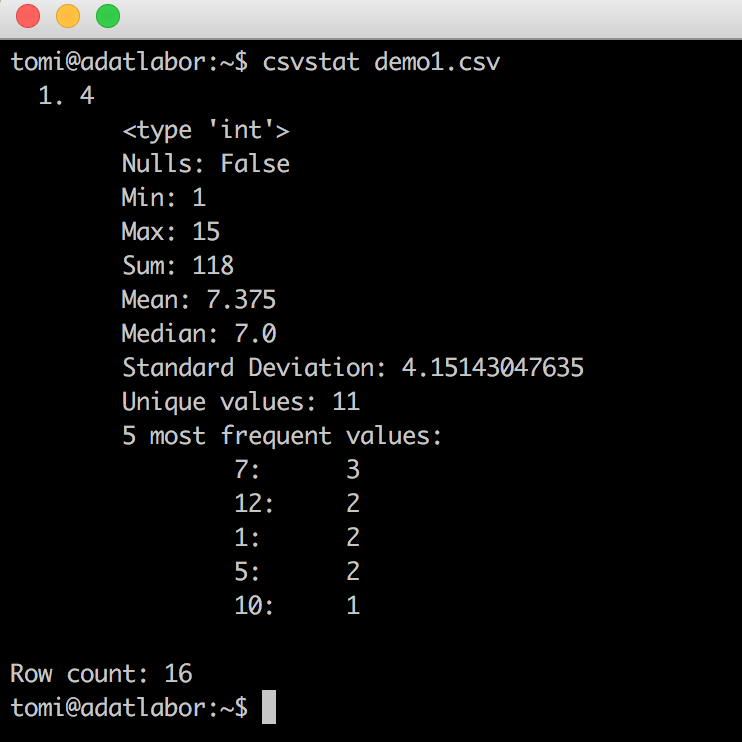
(Even median is there! Remember last time how hard it was to get it?)
Note: csvstat is unfortunately not so great with bigger files. So you can’t use it for the flightdelays.csv for example, because that file is way too big.
Bash best practice #7 – Enter-enter-enter
This will sound ridiculous, but I assure you this is a real problem and this is a real solution for it. This is what data scientists do when they use command line in real life.
The problem: when you cat a file on your screen, then another one right after, it’s really hard to find the first row of the second file. The main reason is that the prompt looks like every other line in your files. If you’ve watched the video above, you have seen that I colored my prompt. That’s part of the solution, but to make sure I will find the first line of my second file, before the second cat I usually hit 10-15 blank enters.
Right?
Do Bash + Data Coding Smarter!
As I’ve mentioned earlier, these articles of mine are just the beginning and they give you the approach and the basic bash tools. But in the long term I suggest 2 major ways to continuously extend your knowledge.
Bash best practice #8 – man
man –» this is a bash command to learn more about specific command line tools. E.g. try:man cat –» and you will get into the manual of cat. It works for almost every command. (man cut, man grep, etc…) The best part is that in each manual you can find a great list of all the options for the given command.
Best practice #9 – Googling + StackOverflow
I know this is something I should not even have to mention, but still: if you have a question, you can be sure that someone has already asked it and another one has already answered it somewhere on the internet. So just don’t forget to use Google first. Most of the answers are on a website called StackOverflow – by the way. If it’s accidentally not there, Stackoverflow is still awesome, because you can also ask questions there. There are many nice and smart people there, from whom you will get an answer fast, so don’t be shy! 😉
A great book about Data Science at the Command Line

And eventually it’s time to mention a great book about Bash!
Jeroen Janssen – Data Science at the Command Line
As far as I know, this is the one and only book that writes about bash as a tool for data scientists. It comes with many great tips and bash best practices! It assumes that you have some initial Python and/or R knowledge, but if you don’t, I still recommend it. If you have read my Data Coding 101 articles about bash so far, it won’t be difficult to understand most of this nice book!
Conclusion
Today we went through some great tools to make your job in bash cleaner, faster and smarter.
Next week I’ll show you two major control flow components of bash: if statements and while loops. (And they are even more important, as we are gonna use the same logic later in Python and R as well!) Update: here’s the new episode!
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester