
For the record: I’m a big fan of third-party data tools (e.g. Google Analytics, Hotjar, Crazyegg, Optimizely, Google Optimize). I like them because they are easy to use and easy to set up.
But sooner or later every online business reaches a size where it’s growing out of these services – and you’ll have to build your own data infrastructure.
This article will help you figure out when and why is it useful to move on from Google Analytics and build your own tools!
When third-party data tools are good enough
When you’re kicking off your online business, you don’t have the time to create proper data analyses – or the money to hire a data analyst. To be fair, in these first few months, you probably won’t need to, either.
However, if you are smart and prescient, you’ll think about at least collecting the data for future research projects. And for that, setting up Google Analytics, Hotjar and the other “point-and-click” services seems to be the perfect solution.
Note: But keep in mind that you won’t be able to export raw data from them later! I’ll get back to that in this article.
As these tracking tools require only the implementation of a small code snippet into your website code, you don’t need to spend too much time or engineering resources on them. Copy-paste the tracking code, finalize some settings (e.g. setting up goals in Google Analytics, starting polls in Hotjar, launching heatmaps in Crazyegg, etc…) and you’re done. Doable in 2-3 hours tops.
When your business starts to grow, you will start analyzing this data. I won’t go into details of why it is needed. If you are reading this blog, I’m pretty sure you know the importance of that: data helps you to grow your business better and faster.
After a while, you start to use these data tools on a daily basis. That’s great. Maybe you also upgrade your favorite tools into pro versions. Nice. You are doing things how they should be done: in a data-driven way.
But sooner or later (usually after 2 or 3 years) you will realize that these third party tools are not scaling with your online business anymore. You’ll have 3 major problems:
- These tools are not flexible enough. (You can’t connect all the dots.)
- You can’t run proper machine learning and predictive analytics projects with them.
- You will see data discrepancies between the different 3rd party tools, so you won’t be able to fully trust your data
These are exactly the problems you can easily fix by building your own data infrastructure.
But what does “my own data infrastructure” mean?
My students like to say that it’s like building your own Google Analytics. But it’s better than that in so many ways.
Every data project has 6 typical steps. When you create your own data tools, you have to think about these:
- Data Collection
- Data Storage
- Data Cleaning
- Data Analysis
- Communication, data visualization
- Data-driven Decision
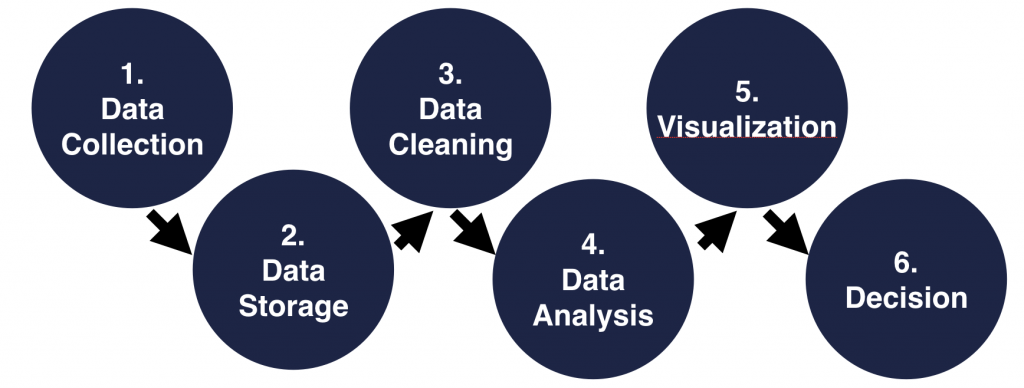
The first step, data collection, is basically about implementing your own tracking scripts. These won’t direct your data to Hotjar or Google Analytics anymore, but into your data warehouse: usually into SQL tables or plain-text files (.csv, .tsv, .txt, …) – or both. (Read more here: Data collection.) There are many more solutions for data collection, but let’s not go there yet.
Once you have the data, you have to think about storing it in a useful form and figure out the data cleaning part, too.
Without any doubt the most exciting part will be the data analysis! You can implement and automate your own SQL scripts to create retention analysis. You can build your own machine learning projects in Python. You can create smart automation. There are literally infinite possibilities for taking advantage of your data. Since it’s yours, you won’t have any limitations!
The final steps will be the data visualization and decision parts. (You can use business intelligence tools – like Tableau, Power BI or Google Data Studio – for that.)
“But wait! that sounds too difficult and tech-heavy! Why would I do that?” – you might ask…
Most of my clients who hear my pitch on this “build your own Google Analytics” project are afraid that it will take too many engineering resources and the investment won’t be returned.
That’s a fair concern, so let me give you four major reasons why you should build and use your own data tools to show you how it pays off in the long term!
Reason #1: You’ll own your data.
The first big problem with third-party tools like Google Analytics is that they are black boxes. This means that you don’t own your data and you can’t use it for everything you want. This is not an issue as long as you only want to check simple reports, like how many people scrolled down to the bottom of your landing page, or how many sessions resulted from paid ads in the last month.
But if you want to combine these metrics, things become tricky. E.g.:
“What was the bounce rate and time spent on page for each of my A/B test buckets?”
Of course, you can solve the smaller problems by using integrations, APIs or some hacks. (Note: Although let me tell you from my own experience, this could become a real pain in the neck if you start to integrate more than 2 tools together.) E.g. for this specific question above, you can connect GA to Optimizely. Sure.
But as you do more and more advanced analyses, you will reach the point where you’ll understand:
Every third-party data tool is created to measure one specific part of your website. That’s their superpower and their limitation at the same time. Even if you manage to connect them, you will never be able to see the full picture. They won’t enable you to connect all the dots!
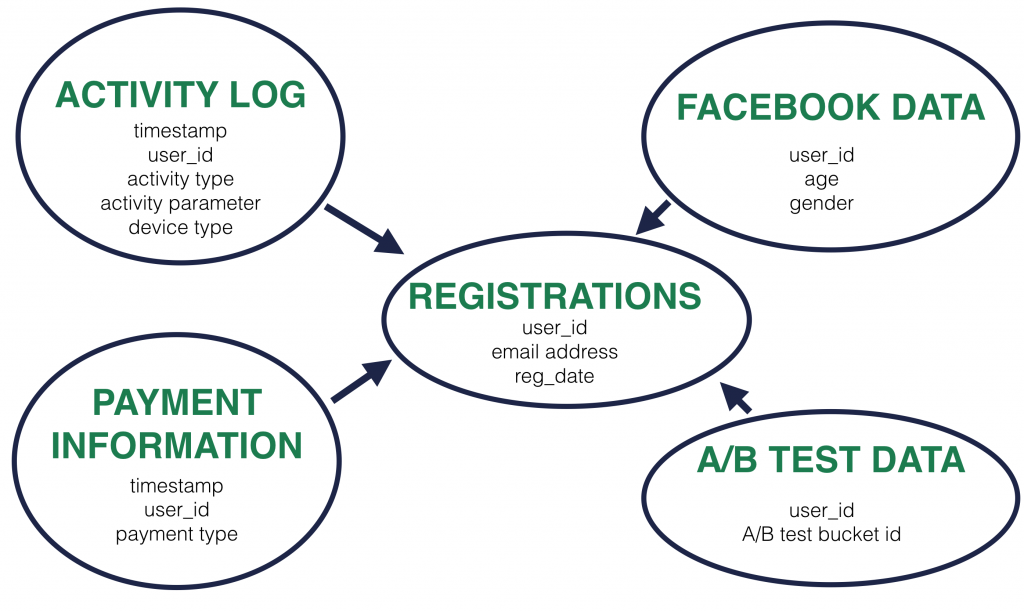
And eventually this will lead to more and more poorly answered – or even unanswered – questions. In a competitive market like online businesses this can be catastrophic.
Reason #2: Machine learning and predictive analytics projects
A part of the “not-having-your-own-data” issue is that you can’t use your data for predictions or machine learning projects either. Predictive Analytics projects are complex and you need to have clear and well-structured data tables with many features and variables to do things right. To create a useful prediction, you need to be very flexible with your data and access it at the datapoint level.
And third-party tools are not flexible at all. (No wonder you’ve never seen a data scientist who created predictions from Mixpanel, Kissmetrics or similar tools.)
Reason #3: Data discrepancies. Can you trust your data?
“Why doesn’t Mixpanel show the same numbers as Optimizely?”
“Why are the Adwords conversion numbers different from the GA conversion numbers?”
“How come Crazyegg shows 30% bounce rate and Mixpanel shows 50%?”

In the last few years I’ve been working and consulting with quite a few startups and ecommerce businesses. The questions above tend to come up from time to time. The exact answers tend to differ from problem to problem. A few examples:
“The different tools define that metric differently.”
“XY tool has recently changed its conversion tracking method.”
“XY has a different conversion attribution model than ZW.”
“XY uses sampling.”
“XY hasn’t been set up properly.”
Either way the ultimate answer is:
If you can’t trust your data, the single source of truth is always the data infrastructure you built. With your own definitions, your own tracking snippets, and your own structure — and without sampling and black-box secrets.
Note: having your own data tools will make it easier to debug the third-party data tools you use when you need to, too.
Reason #4: Way more detail
Building your own solution will give you the ability to collect every datapoint you need. Every click, every page view, every extra parameter. If you are using Google Analytics, you are compromising on not having email addresses connected to activity data. If you are using Mixpanel, you are compromising on which exact data-points you want to collect (if you collect everything, you will reach the limit very quickly and Mixpanel will get super expensive).
If you build your own data infrastructure, you don’t have to compromise on anything. You can have data that’s as detailed and abundant as you want. And you can use and analyze that data anytime and any way you want.
Con #1: Simplicity
However, the “building your own Google Analytics” project is not always the best decision. In fact, there is one great counterargument against it.
That’s simplicity.
Using third-parties like Google Analytics is incredibly easy: both the tracking implementation and the data analysis parts.
My rule of thumb here is: simple tools for simple questions – advanced tools for complex questions.
As long as you are looking only at the number of sessions per traffic source, for instance, you won’t need to spend time or money to set up your own data infrastructure. Google Analytics will serve you well. There are businesses (eg. solo entrepreneurs or smaller e-commerce websites), where Google Analytics will cover the data needs forever! And that is cool!
But once you are out of the “simple questions” phase, and you encounter more and more complex problems, please don’t hesitate to start to build your own data tools.
Hiring questions
Different tools need different skill sets.
For using Google Analytics, Hotjar, or Optimizely, you have to hire a digital marketer or a digital analyst. (Or you can do it by yourself if you have time for that.)
For building data collection scripts, SQL-tables, python scripts and the rest – you need to hire a data scientist with strong coding skills.
A typical question: How big of a financial investment is this? It’s hard to give exact numbers, but if you look around websites like Indeed.com or Glassdoor.com, you will see that data scientist salaries are ~20% higher than digital marketer or digital analyst salaries. Obviously this can differ by country, by market, by company, by the exact role, etc…
Anyways, hopefully, regardless of whether a digital analyst or a data scientist you hire, she will create much more value for your business than she costs.
Is the price of the tools a question?
For sure.
But you’d be surprised!
Here’s a small calculation for an SaaS startup!
Let’s say you have 5,000 registered users, 500 daily active users and 1,000 new daily visitors. In this case you will pay:
Optimizely: ~400$/month (link: https://www.optimizely.com/plans/)
Mixpanel: ~150$/month (link: https://mixpanel.com/pricing/)
Crazyegg: ~50$/month (link: https://www.crazyegg.com/pricing/)
Hotjar: ~30$/month (link: https://www.hotjar.com/pricing)
Google Analytics: free
Altogether: $630/month — if you use 3rd party tools.
If you use your own data tools, for the same number of users, you can collect, store and process all your data on a data server for ~$50/month. The rest of the tools (Python, SQL, bash) are free. (Yes, even machine learning libraries are free in Python… It’s an open-source technology. Isn’t that cool?)
This means that even for smaller startups, building their own data tools can be cheaper than using 3rd party data tools… (And the more they scale the bigger this difference will be.) On top of that, they will be able to use their own tools to create much better and more useful analyses.
Note: I have to mention here that you can’t forget to count the salaries of the different professionals you’ll hire for the job. (See above: data scientists cost more than digital analysts.)
When should you build your own data tools?
I guess you get the point now! When you have grown out of the third-party tools like Google Analytics, SQL and Python and the other more advanced tools will be your new best friends.
But when exactly should you start to build your own data infrastructure?
In my experience the best possible time to hire a data scientist and start to build your own data tools is when your company has between 15 and 30 employees. This is a great average. You can tell the time has definitely come:
- when you’ve filled the must-have roles (engineers, designers, marketers) and when you have to start to be smarter and smarter to optimize your online business
- when you’ve reached a reasonable size of audience (users or/and visitors)
- when building a data-driven culture is still possible and manageable at your company
Note: If you don’t have (or can’t yet afford) a data scientist on board but you have engineering resources, I still recommend that you think about collecting interaction data (clicks and pageviews), at least in plain-text format, to your own servers from day one. Believe me, 3 years later you will thank yourself for not letting this information be lost today.
Conclusion
I hope this article gave you a good overview about when and why to build “your own Google Analytics.” Use third-party data services, but don’t get stuck with them. Once you need to, don’t be afraid to start to build your own data tools – and create a better, more detailed, more flexible and easier to use data infrastructure for yourself than any third-party tool on the market!
If you want to learn more, check out these articles:
- Data Science for Business
- Learn SQL from Scratch
- Learn Python from Scratch
- Evangelize the Data-Driven Culture within your Company
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester