
“Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it…” – Dan Ariely
Dan Ariely put it well.
Nowadays, everyone is talking about Big Data, and the reason behind this is not that technology is changing, but that marketing professionals realized they can sell almost anything using these two words.
On the other hand, the real big data professionals who are actually using this technology day-to-day don’t write easy-to-understand articles on the topic… as they are more interested in using technology than writing about it.
Anyway. The aim of this article is to fill this gap.
What is Big Data? I’ll make it clear for you and cut the marketing BS.
Not Big Data
Let’s start with the question: what is small data?
The very basics of data analysis stretch back to censuses, where even thousands of years ago, commissioners asked all kind of questions from people.
The next evolutionary step was polls and questionnaires, which to this day are frequently used in market research. What’s the issue with surveys?
Two things:
- Sampling: Even the most precise, clear-cut sampling can be wrong. How could the response of 2,000 people represent the thoughts of one million people? Of course there are statistical methods to make the results more accurate, but the chance of error is still there.
- The other – more important issue – is the quality of the responses. People lie, and often they don’t even know that they are lying. If I asked you what your favorite color is, today you might say red… then a week later you might realize all your t-shirts are yellow and you then get uncertain. But by then, you have already given your answer, and the business folks at a very important company have already made decisions based on it.
These are the typical issues with small data.
Closer to Big Data
The big data mindset gives answers to these kinds of problems. One of the principles of big data is that we don’t ask people, we just observe their behavior. This way they can’t lie to us (or themselves).
But more importantly, we are not just observing 2,000 people, but all of them.
Obviously the easiest way to carry this out is through IT and related fields, where each click, each tap, even each movement of the cursor generates a new datapoint.
But this collect-every-datapoint principle is conquering more and more industries – not just IT.
- Self-driving cars collect data points every millisecond about the road, the surroundings, and the weather. Everything…
- Stock Traders follow hundreds and thousands of trades every second and try to base their next move on this data…
- Even traditional businesses like factories or agricultural firms collect data through sensors and optimize their processes further and further.
We are talking potentially about a million data points a day – in some cases in an hour – yet this is still not considered Big Data. Technically, there is nothing challenging in processing a million data points – even on a desktop computer.
Think about it: 1 gigabyte is 1,000,000,000 bytes. A lot of data… still: today it doesn’t count as “big”.
But then what is considered “big”?
Big Data
One of the most important trends over the past years (decades) was the constant and significant decrease in the price of data storage and data processing.
We have gotten to the stage where it is so cheap to store information, we save everything and delete nothing.
And this is the key to big data! We store everything we can without deleting anything, for many years back. Usually we store these in databases (e.g. SQL) or in log files (e.g. csv, txt files).
Sooner or later we get to the stage where we create such huge databases that it’s challenging for one computer to store and process.
We obviously won’t even try to open a one-terabyte set of data in Excel or SPSS. But even a normal SQL query can take up to many hours or even days to run on a dataset this big. Whatever we try (R, Python, etc.), we realize that it has reached its maximum computing capacity and can’t process the data in a reasonable time.
That’s when the big data technologies come into play – the main concept of which is that it won’t just be one but dozens (or even hundreds) of computers that work on our data analysis. Often these clusters scale easily and almost endlessly: the more data we have, the more resources we can involve in the processing.
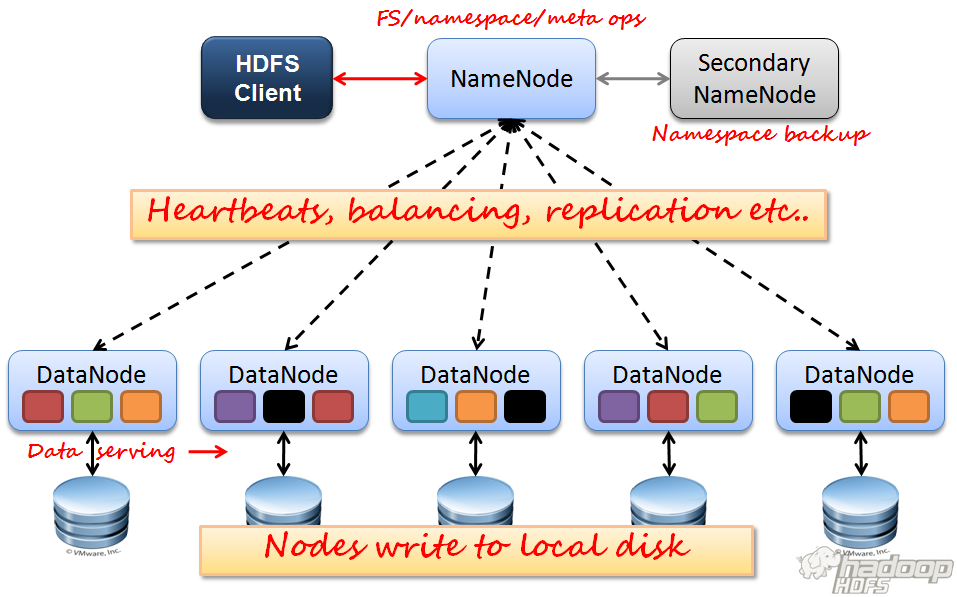
This way we can analyze our data in a reasonable time again. But interconnecting many computers and making them work together on one data task… it has its own challenges. New infrastructure, new technology, new solutions.
This is how big data technologies were born, bringing forth new concepts like Hadoop, YARN, Spark, Pig and numerous cool and important technologies.
Big data evolution within a company
Let’s see how the evolution works in the case of an online startup:
- In the beginning, the company doesn’t have a data analyst, but they don’t want to fly blind. So they set up Google Analytics, Hotjar, etc. and start to analyze their data through these point-and-click tools.
- They get their first 10,000 users. Management realizes that these third-party tools are starting to become very expensive, and they are not detailed and flexible enough to serve the company’s analytical needs. So they start to build their own SQL tables and create event logs. They hire a data scientist, too, who starts to create dashboards, ad-hoc analyses, automated reports, machine learning projects, and whatnot.
- The number of users keeps growing (that’s awesome) and the data team starts to realize that their data scripts that ran in seconds for 10,000 users won’t run even in 10-20 minutes for 1,000,000 users. Finally, they reach a loading time of numerous hours – so they realize they need big data technology and begin to Google whatever Apache Spark is…:-)
Conclusion
I hope this short explanation helps to clear things up about the great big data myth, so now you know what is big data and what isn’t.
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester