As I have mentioned several times, Data Science has 3 important pillars: Coding, Statistics and Business. To succeed, you have to be well-versed in all three. In this new series, I want to help you to learn the most important parts of Statistics. This is the first step – and in this episode we are going to get to know the most basic statistical concept: statistical averages.
the 3 pillars: statistics, coding, business
Statistics. What is it for?
A few weeks ago, I ran into an excellent article about data vizualization by Nathan Yau. He writes about dataviz, but I love how he puts the importance of Statistics at the beginning of the article:
“Data is a representation of real life. It’s an abstraction, and it’s impossible to encapsulate everything in a spreadsheet, which leads to uncertainty in the numbers. How well does a sample represent a full population? How likely is it that a dataset represents the truth? How much do you trust the numbers? Statistics is a game where you figure out these uncertainties and make estimated judgements based on your calculations.”
Statistics is all about “compressing” a lot of information into a few numbers so our brain can process it more easily.
For example: More than 500 million people are living in the European Union’s 28 countries. If we want to compare salaries between countries, we won’t compare each of the salaries one by one. That’s nonsense. We will calculate and compare average salaries instead. That’s a helpful abstraction.
However, if you follow this article series about statistics, you will also see that describing a whole dataset with only one number can often yield misleading results. Taking average salaries is cool, but it doesn’t let us see, for instance, the range of the data. In one country the difference between the poorest and richest people could be way bigger than in another, and that could be important to know, too.
A good data scientist can always find those few numbers that describe her data in the simplest, but still the most meaningful way. Join me and I’ll show you the statistical tool-set necessary to be the best at that!
Statistical Averages
Let’s start simple! Statistical averages. It’s an easy-to-understand concept, and very commonly used. The point of using averages is to get a central value of a dataset. Of course, there is more than one way to decide which value is the most central… That’s why we have more than one average type.
In everyday language, the word ‘average‘ refers to the value that in statistics we call ‘arithmetic mean.‘ When calculating arithmetic mean, we take a set, add together all its elements, then divide the received value by the number of elements. For example, the arithmetic mean of this list: [1,2,6,9] is (1+2+6+9)/4=4.5.
This is middle-school mathematics, so I assume that you are very well aware of this calculation anyway.
Note: calling the ‘arithmetic mean’ the ‘average’ is improper. The word ‘average’ can refer to any of the average types — mode and median are averages, too. If you hear anyone using ‘average’ wrong in the coffee shop, don’t correct her… but in a data science meeting (or especially in a job interview), please stick to ‘arithmetic mean.’
Note 2: “But Tomi, in the header of this section you have written ‘Mean’ and not ‘Arithmetic Mean.’ What’s going on here?” Okay, you are right. We don’t really say ‘arithmetic mean’ during data meetings. We just say ‘mean.’ But we think ‘arithmetic mean.’ The only reason for this is that we are lazy. And to be honest, it’s not the best practice because there are other types of means, too (like geometric mean or harmonic mean. More info: here.). Bottom line is:
“Average.” No good.
“Mean.” Okay.
“Arithmetic mean.” Perfect.
Median
Here comes the most commonly used metaphor for showing the importance of the Median!
Ten workers sit in a room. Their yearly salaries are:
Worker #1
€15.000
Worker #2
€18.000
Worker #3
€18.000
Worker #4
€18.000
Worker #5
€18.000
Worker #6
€19.000
Worker #7
€20.000
Worker #8
€22.000
Worker #9
€22.000
Worker #10
€22.000
What’s the central value of their salary?
Let’s try arithmetic mean first! The result is €19.200. Is it a good enough “compressed value” of the information in the table above? Can we say that these 10 workers are all making around €19.200 per year? I’d say: yes, $19.200 is not too far from €15.000 nor €22.000.
But here comes the trouble: Worker #10 goes home, and the CEO of the company comes in instead. She makes €100.000 per year.
Worker #1
€15.000
Worker #2
€18.000
Worker #3
€18.000
Worker #4
€18.000
Worker #5
€18.000
Worker #6
€19.000
Worker #7
€20.000
Worker #8
€22.000
Worker #9
€22.000
CEO
€100.000
Now, the arithmetic mean changes to €27.000. Is it still a good enough value to describe the average salary? Well… Not really. 9 out of the 10 people make less than €27.000 a year – so saying that €27.000 is a good central value doesn’t sound right.
Now, the CEO goes home, and Bill Gates comes in.
Worker #1
€15.000
Worker #2
€18.000
Worker #3
€18.000
Worker #4
€18.000
Worker #5
€18.000
Worker #6
€19.000
Worker #7
€20.000
Worker #8
€22.000
Worker #9
€22.000
Bill Gates
€1.000.000.000
The arithmetic mean is €100.017.000! Is everyone in the room making 100 million Euros yearly!? Not even close.
When there are extreme values – or in statistics-language: outliers – in a data set, arithmetic mean is not a good-enough representation of the data anymore.
That’s when median comes into play! You get the median of a set by simply arranging all the elements of it from smallest to greatest, then taking the middle value. Here’s an example:
sample_data=[9,11,5,7,1]
What’s the median of this list? First, sort it in ascending order: [1,5,7,9,11]. Then take the middle value of the list. In this case, it’s 7. That’s the median.
Note: the mean of this sample_data list is 6.6, which is pretty close to the median.
But what happens when we have a list with an even number of elements? Let’s take a look at our workers again:
Worker #1
€15.000
Worker #2
€18.000
Worker #3
€18.000
Worker #4
€18.000
Worker #5
€18.000
Worker #6
€19.000
Worker #7
€20.000
Worker #8
€22.000
Worker #9
€22.000
Worker #10
€22.000
Luckily, this data is already sorted, so we just have to pick the middle value. Is it Worker #5 or Worker #6? The answer is: it’s the mean of the two, so €18.500. The general rule is that if you have a list with an even number of elements, you can calculate the median by:
sorting the list
taking the mean of the middle two elements.
What’s the median when the CEO comes in? It’s the exact same: €18.500.
And when Bill Gates comes in? Same: €18.500.
Now you can see, that in these two last cases, the median was a better central value for the whole dataset than the arithmetic mean would have been.
Note: even if it was, median by itself is not a good enough number to describe a data set with outliers, mainly because only by looking at the median value, we don’t even suspect that Bill Gates is in the room, too. And in real life data science problems, you want to know about “Bill Gates”-es in the rooms. I’ll get back to this problem in the next few articles.
Mode
The third famous average type is Mode. The definition is simple: mode is the element that occurs most often in a list. In theory, it’s useful when the numerical values in your data set are used as categorical values. But to be honest, we rarely use it; and even when we do, we don’t really call it the mode. We just say: the most frequent element in a list.
However, I wanted to add it to the list because, you know… if you are asked during a job interview, at least now you will know what to answer. 🙂
What to use? Mean, median or mode?
There is no definite answer for this question. Based on my experience, mean and median will be used equally often, and mode almost never… But when to use which one? That really depends on the particular case. There are some rules of thumb, but as I mentioned above, I don’t really see the point of using only one number to describe a dataset anyway… so let’s get back to this question when we have learned more about variance, standard deviation, standard error, about different distributions, and more – in the upcoming articles!
But now…
Test yourself!
Okay, now that you know all three famous average types – mode, median and mean – it’s time to test yourself! This assignment was actually used a few years ago at junior data analyst job interviews, too…
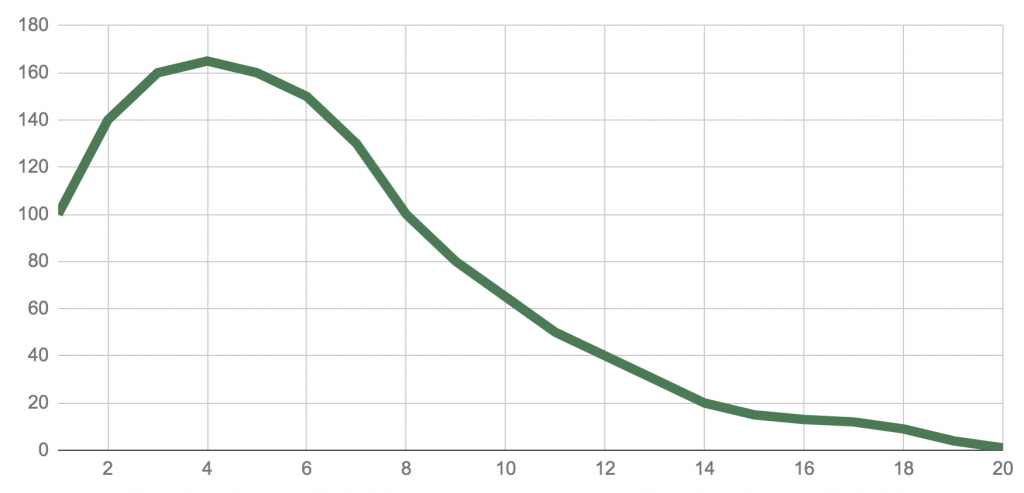
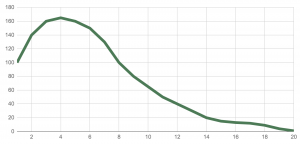
Take a distribution that’s skewed to the right. Here it is on a chart:
In this data set we have elements from 1 to 20. Every element occurs more than once. (E.g. We have around one hundred 1 values, around one hundred forty 2 values, and so on… and at the end of the list, we have around ten 19 values and one or two 20 values.)
The x-axis marks the different elements of the list: numbers from 1 to 20. The y-axis shows the number of occurrences of each of these elements.
The task is:
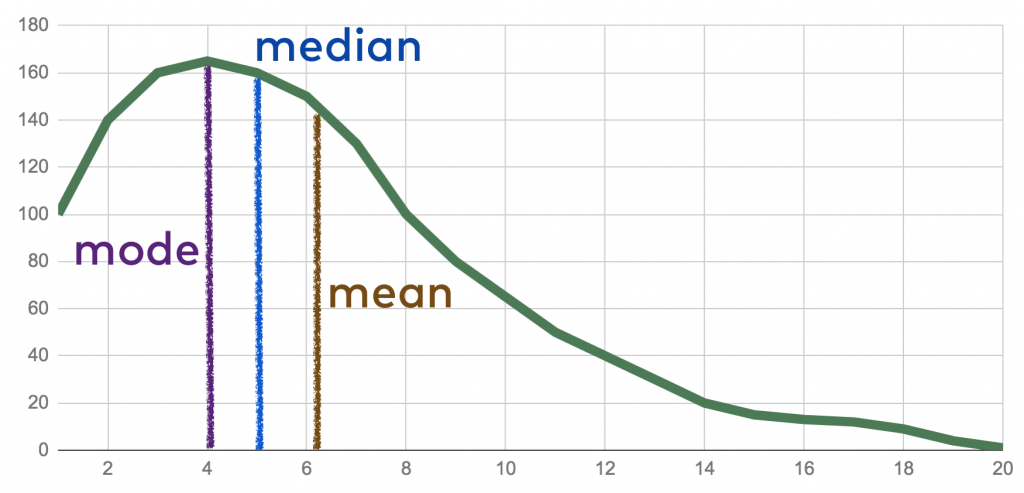
Draw a vertical line on the chart where you estimate the mode, the mean and the median values to be. What’s the order of the values from left to right?
Solution
The solution is this: mode < median < mean.
Since you don’t have the data, you can’t calculate the exact values to get this answer. But you can do two things:
You can create your own sample data that would result a similar skewed-to-the-right chart. Here’s a very simple example: [1,1,2,2,2,3,3,4,5,6]. If you calculate the mode (2), the mean (2.9) and the median (2.5) for this sample data set, you will already know the answer to the original question: mode < median < mean.
You can think out the solution, too! First, try to figure out the relationship between mode and median. Imagine that we are chopping off the right side of the x-axis. The mode would be 4, and, because this part of the chart is almost symmetrical, the median would be around 4, too. Let’s put back the right side of the chart. Now, we have a lot of greater values than 8, and these values push up the median value – while mode doesn’t change. So the relationship between mode and median is mode < median. What about median vs. mean? We already know that mean is more sensitive to extreme values. So the one or two 20 values at the end of the list will have an effect on the mean, but it probably won’t change the median value (just as in the Bill Gates example). This means that median < mean. All in all: mode < median < mean.
Conclusion
The 3 most common statistical averages are (arithmetic) mean, median and mode. You will use mean and median all the time, so it’s good to be confident in calculating them!
This was our first baby step in discovering the great universe of statistics for data science! The next step is to understand statistical variability.
If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.Ok