
In this article, I’ll answer a frequently asked question – which is:
“What does a data scientist’s day look like?”
This article is available in video and podcast formats, too!
Would you prefer watching this in a video format? Here you go:
Do you like podcasts even better? Here:
Also available on iTunes, Spotify, Google Podcast and in many more podcast applications.
Or just simply go on with the article… 😉
A typical day of a data scientist…
First off, I wouldn’t say that there is a “typical” day for a data scientist. It’s a complex profession and what exactly you are doing as a data scientist really depends on a few things:
- What type of a data project are you working on? (This can change from month to month or from quarter to quarter, of course.)
- What does the organization and the company you are in look like? (Is it a small or a big one? Is it flat or hierarchical?)
- What’s your role within the team? (Are you a junior? Are you a senior? Are you the only data scientist on the team? Or do you have 2-3 data professionals next to you?)
So there are quite a few variables here.
Regardless, I’ll go ahead and try to answer the question… but this will be more of a broad average than the exact day of each and every data scientist out there.
What does a data scientist’s day look like?
Usually, a data scientist’s day is a combination of these three things:
- coding (which as a rough average will take ~70% of your time)
- meetings, presentations, talking to others (that’s ~15% of the time)
- thinking (it’s ~15% of your time)
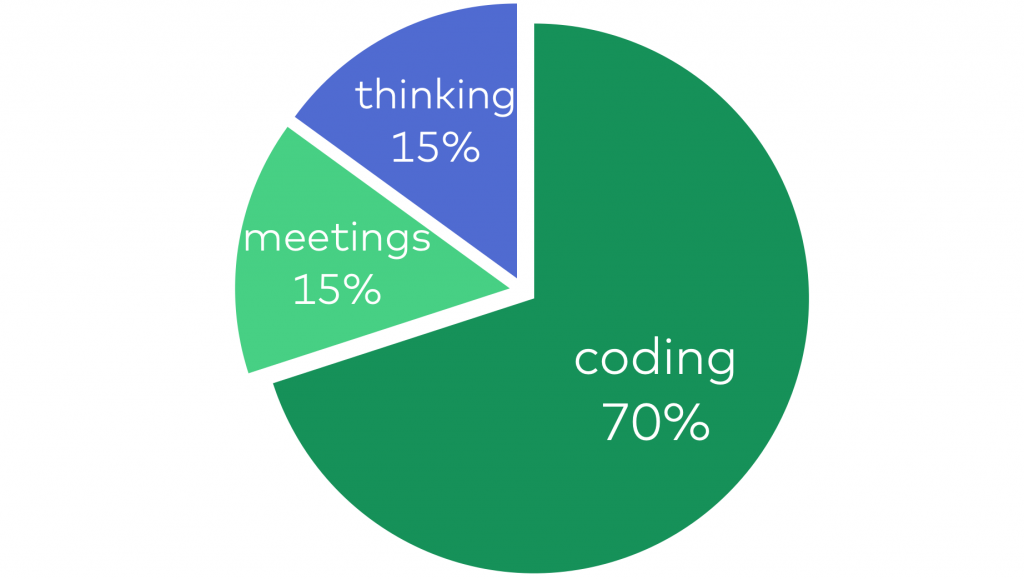
Obviously, a data science project is longer than one day, it usually takes more like a few weeks or even a few months. So you arrive at the office, you drink your coffee, you sit down and… and most days you will start off simply by picking up where you left off the day before. As I just said, it can be coding, a meeting or thinking. So let me talk about these in detail.
Coding (~70% of the time)
The biggest chunk of a data scientist’s day is spent coding. I’d say it’s ~70%… or maybe even more. It makes sense, right? A painter also spends most of her day with a brush in her hand. And Python, SQL and bash are the tools that a data scientist “paints” with.
I keep telling aspiring data scientists that out of the 3 key skills (which are statistics, coding and business thinking), coding is the number one they should learn first and the most. And this is not by accident.
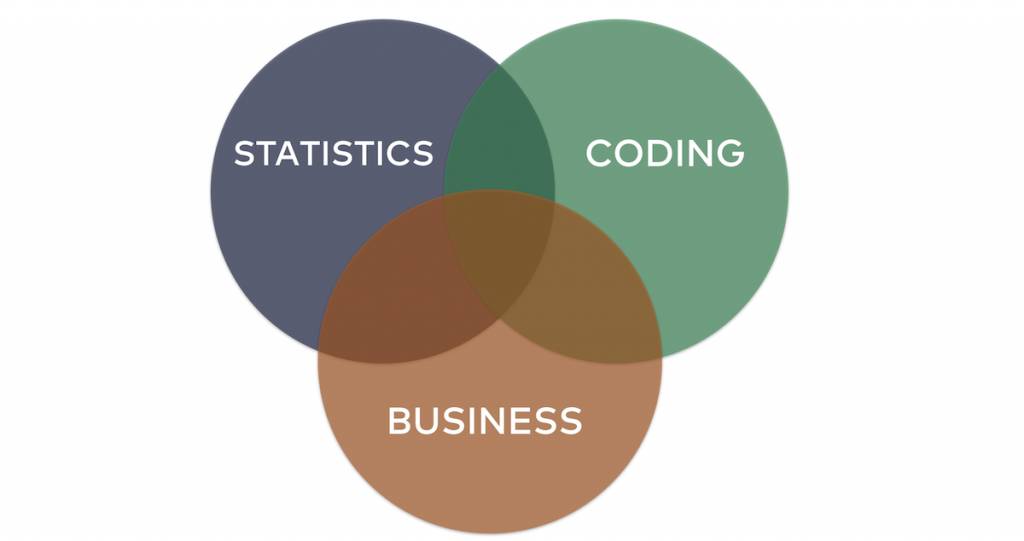
Coding is significant. But even within coding, there are several typical tasks when it comes to data science.
Let me highlight a few of these:
Data cleaning and data formatting is the first that comes to my mind, since usually these are the most time-consuming tasks. There is a half-funny, half-true saying amongst data professionals which goes:
“80% of the data scientist’s job is data cleaning… The other 20% is complaining about data cleaning.”
And while it’s obviously a bit of an exaggeration, it’s partially true, too… Simply put, you have to bring data into a format you can work with in the next steps of your project. And that takes more time than you would imagine.
Once data cleaning and formatting is done, another typical task is prototyping. When you prototype, you test out which exact type of analytics methods or machine learning models fit the best for your given task. This is challenging, but it’s also one of the most exciting parts in every project. This is where you find out how exactly you’ll turn your data into value. Prototyping can be done in a Jupyter Notebook when using Python, in an SQL manager tool when using SQL, in the command line when using bash, or, well… anywhere else you prefer. Feel free to pick any tools or environment you feel comfortable working with at this step. Prototyping is not about making things perfect, it’s about figuring out what will and won’t work — as fast as you can.
When this part is done, the final step can vary based on the exact goal of the project.
If it’s a one-off analysis for a meeting for instance, you’ll have to visualize your data, articulate the findings — and turn these all into a presentation that everyone can interpret easily.
If it’s a report or a dashboard that your colleagues will use in the future, you’ll have to figure out how you can automate it and make it accessible for everyone at the company.
And if you are working on something like a machine learning project that will be turned into a product, you’ll have to figure out how to implement it. But at this step you’ll most likely have help from developers, too.
The point is that the greatest proportion of a data scientist’s day is spent coding… which can be:
- data cleaning and data formatting,
- prototyping
- creating data visualizations
- creating automations
- implementing your models into the product
…and, by the way, several other things that didn’t fit in this section — like bug fixing, maintaining your previously written scripts, learning about new packages and libraries and so on…
Meetings, presentations, talking to others (~15%)
Another big slice of a data scientist’s day is communicating with colleagues. I’d say, it’s ~15% of the time. Whether we are talking about meetings, 1-on-1s, presentations or chit-chatting in the cafeteria, talking to your fellow teammates is extremely important.
Let’s be honest here, most of your coworkers won’t even know what a data scientist does. That’s okay, but it also means that it’s your responsibility to bring them onboard. If you do so, you’ll get more support for your data projects and you can make more impact, too.
So it’s really important that you communicate with your colleagues… even if you feel that you are a more introverted type of personality.
But there’s a flipside to this coin, too: it’s getting involved too much and sitting in meetings all day long. It’s more typical at bigger companies, by the way… But it can happen everywhere. The obvious problem here is that when you are sitting in a meeting, you can’t get things done. And while being in sync with your co-workers is crucial, beyond a limit, it can turn out to be counterproductive.

I guess most of you can relate to this problem. I’ve been there, too. I know, it’s an annoying issue. For me, the solution was to sit down with my manager, and agree that it would be more beneficial for everyone if I just skipped the meetings that I didn’t find useful to be in. And then I just started to mercilessly cut those off. The idea sounded scary at first, but it turned out that nothing bad happened. And at the same time, the number of things that I could actually get done in a day went up.
It’s important to talk to others — too little will make people ignore your projects, too much will eat your productivity… And, in my experience, the sweet spot lies somewhere around 15% of a data scientist’s day.
Thinking (~15%)
And the third big thing — however funny it sounds — is thinking.
Data science is hard. Figuring out the right statistical model, understanding findings or writing the best data script takes a lot of mental energy. And thus when working on a data project, I often find myself just sitting and thinking. Which can look funny to your colleagues. Still, without that, you couldn’t move in the right direction.
For me, thinking is more efficient if I can sketch in the meantime. It can be on a whiteboard, on a paper or in a fancy online mindmapping tool (like Miro). Either way, visualizing my thoughts always helps me to see things more clearly. (And hey, at least, your colleagues will also know that you are actually working, too. ;-))
I’ve said before that a significant proportion of the job is coding. But sketching, thinking and coding together is much more efficient. Just think about the prototyping stage that I talked about before. When writing your code, you always focus on the small problems (e.g. a bug or a compatibility issue in your code). But if you stop for a second, take a step back and draw your thoughts on paper, you’ll immediately see the connections between things. It’ll be easier to spot the important things, find more creative solutions, fix the obvious mistakes and see the big picture.
So thinking is important, you should dedicate time to it. And don’t worry when thinking seems like you are not “working.” It’s actually the most important boost for a data scientist’s productivity.
The end of the data scientist’s day
I like to close my day by doing three things:
- answering my emails,
- reviewing my day and
- setting the plans for tomorrow
Why am I answering my emails at the end of the day?
Well, this is more like a personal productivity tip, but it worked for me very well.
It’s a bit different now that I’m also teaching data science. But when I worked full time as a data analyst, my rule was not to touch my inbox until the end of the day. The reason is simple: emailing drains creative energy. So it’s better to finish the productive tasks first, then go and finish off your emails.
Planning the next day at the end of the day is also an important productivity trick for me. It just feels good to check out that way. It frees my mind — and on the day after it also gives me the opportunity to jump right into the most important tasks. I don’t have to think about what to do, just start and go to the most important thing to be done.
Conclusion
So what does a data scientist’s day look like?
It has three big segments:
- coding (~70%)
- talking to others (~15%)
- thinking (~15%)
As I said, these are just broad averages, based on my experience. So if you are a practicing data scientist, feel free to let me know your thoughts on the topic!
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester