
In this article, I want to quickly show you how websites collect data. It’s important to know this for two reasons:
- If you are a website visitor, it’s good to know what sort of data can be collected from you.
- If you are a website owner, it’s good to know what sort of data you can collect from your visitors.
Now, I have to add that, in this article, I won’t go into the legal and ethical aspects of these questions. I leave these to you and your legal professional. I’ll only show you what’s possible with today’s technology and what things are done already by most websites.
Note: this article is available in video format, as well: here.
Back End and Front End
When it comes to a website, the data collection can happen in two major places: on the front end and on the back end.

The front end is basically the website that the visitor sees in her browser. There, different scripts (mostly written in JavaScript) can pick up and send the data points to a data server.
And the back end is the server that serves your website. It’s practically invisible to your visitors, but it’s there, and it collects the data, as well — even if the website’s owner doesn’t know about it. (Most of them don’t.)
Front End Data Collection (with JavaScript)
To make this easy to understand, I’ve created a demo website that you can use to try out the different data collection methods I’ll show you!
LINK: sendatree.eu
Everything that we’ll do on this website can be done on 99.99% of other websites on the internet.
So I encourage you to do this with me:
- Open a Google Chrome browser and a new incognito window.
- Go to sendatree.eu.
3. Right click on the web page and choose “Inspect”
- You’ll see the whole code base of the website on the right side of your browser:
- Choose “Console” on the top menu:

6. Here, instead of sendatree.eu’s HTML code, you’ll see a console where you can run JavaScript code.
And this is really important:
Every single JavaScript code that we run here, can be run automatically by the website itself.
In other words, every data point that you will mine about your own website visit session in this tutorial — could be collected by the website (and can be collected by all other websites) automatically about all its visitors, as well, and sent to a data server to be analyzed.
I’ll show you how, and I’ll focus, of course, on the popular data collection techniques that most websites use nowadays.
Querying and collecting visitor data using JavaScript
document.location
The first and most obvious thing you can get from the console is the information about the web page itself.
Type this into the console:
document.location
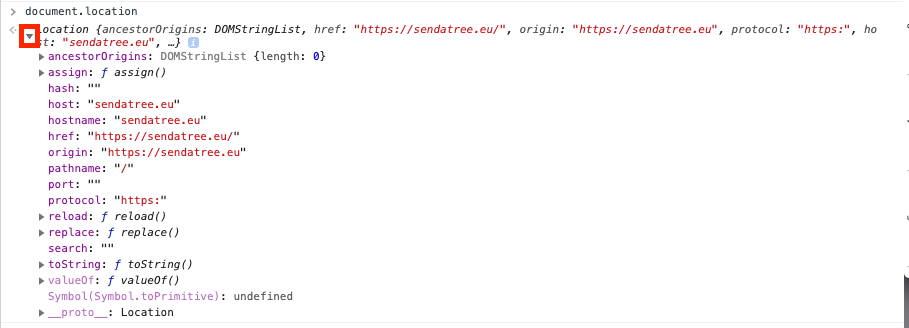
This will return a JavaScript Location object with important datapoints about the web page:
Location {ancestorOrigins: DOMStringList, href: "https://sendatree.eu/", origin: "https://sendatree.eu", protocol: "https:", host: "sendatree.eu", …}
You can go even deeper by clicking the little arrow on the left side:
Or you can just query the exact data point you are interested in, by typing, for example:
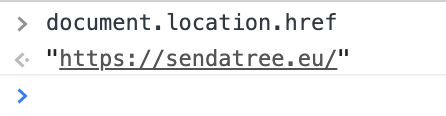
document.location.href
which will return only one thing: the entire URL of the web page:
document.referrer
document.referrer
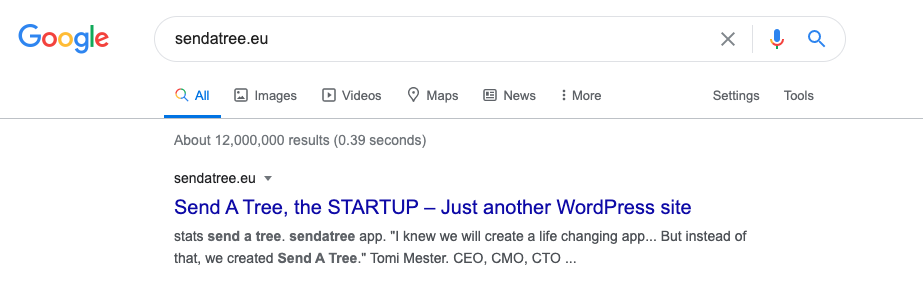
This is another often-used parameter that can be collected. It shows the website the user clicked through from. It’ll be empty for us, because we directly typed in the sendatree.eu URL. But if you Google “sendatree.eu“:
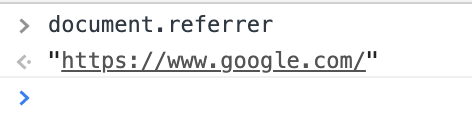
And then click through from there, then type document.referrer in the console. You’ll see that now it returns google.com:
screen
screen
Information about visitors’ screen settings can be collected, too. And it’s not just the resolution of the screen:

But for instance with the screen.orientation.type javascript snippet, one can get the default orientation of the user’s screen… Which can be an indication of whether the user is on mobile or desktop.

navigator.userAgent
Since we are talking about mobile vs. desktop, it’s interesting to take a look at the:
navigator.userAgent
property, too.
This will return something like this:
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
As you can see, it’s mostly about the browser the visitor uses. But you can also find the operating system of her computer (or in this case mine)… which can be an even more direct indication of whether she’s on mobile or desktop.
You’ll find many more things in navigator if you go deeper.
But let me just highlight another frequently collected piece of information:
navigator.languages
navigator.languages
This shows the preferred languages on the computer of the visitor – prioritized:

Let’s talk about cookies, too!
One of the most discussed aspects of data collection is cookies.
As you can see, most websites can collect a bunch of information without cookies, too. But I have to admit that cookies complicate things even more — because they stay in the visitors’ browser even after they close the website.
That means that if you visit a website today — and then one week later visit it again from the same computer and from the same browser… with the help of cookies, the website will know that you are the same visitor.
Let’s see how this works!
On the same top menu where you selected Console, now go to Application. Then select the Cookies menu on the left bar. Within that, select https://sendatree.eu.
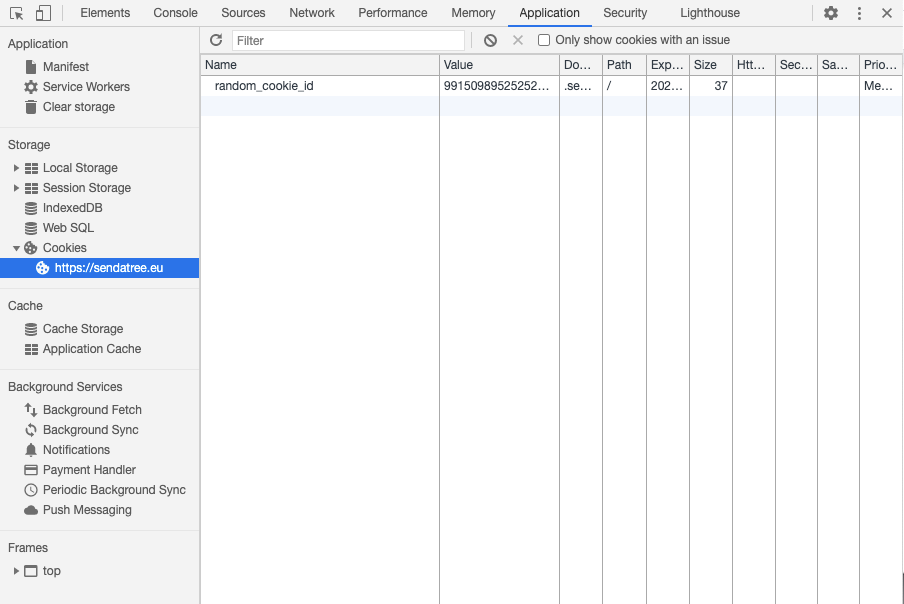
You can do this for any website, and you’ll see a list of all the cookies that the website uses to track its users.
For this example web page, you’ll see only one cookie (random_cookie_id) and I set it only to demonstrate how it works. This random_cookie_id does exactly what I said that cookies do. It saves a cookie with a random variable into your browser that will be used to “flag” that you are the same visitor when you come back and visit this website next week.
It has a size, an expiration date and very importantly, it can’t be used across different domains. So if you visit another website, like data36.com, the cookie that’s created by sendatree.com, naturally, won’t be seen by data36.com.
I won’t go into detail about how this cookie is set. (It’s a few lines of code.)
But I’ll show you how you – and of course a website – can query it with JavaScript.
document.cookie
Just go back to console and type:
document.cookie
And there are all the cookies that are used by the given website in the browser.

This time, it’s only one cookie.
But when you visit a real website, you’ll find many many more — that all store different pieces of information. Just go to your favorite e-commerce site and I bet that you’ll see at least a few of these commonly used cookies:
- Google Analytics cookies (usually called
_ga,_gid) - Facebook cookies (
_fbp) - Twitter cookies (
twid) - and probably many more…
You might know that these cookies are set by tracking scripts that the owner of the website placed there mainly for business purposes: like measuring the website traffic (Google Analytics), running remarketing campaigns (Facebook, Twitter, etc.) and so on. When these marketing-related JavaScript snippets run, they send all the data that I showed you (and more) to these big companies, as well.
Note: Generally speaking, this is not dangerous… But you know, while the data that the website owners can collect from you is mostly anonymous, it isn’t always — when it goes to Facebook, for instance, it can be tied directly to your Facebook profile (but only if you are logged in on Facebook while browsing). So that’s the method these big companies use to collect so much data from you, even on a non-Facebook, non-Google, non-Twitter website.
Is it good or bad? I don’t know — but it’s good to know how it works, for sure.
How the data goes to a data server (e.g. JavaScript + variables + XMLHttpRequest)
As I said, any JavaScript code implemented to a website can query the same data and website usage information about all users — that you have queried in Console about yourself.
How?
There are multiple ways to get this done. But here’s a simple example.
These few lines will store a few important data points into a JavaScript array:
cookie_code="random_cookie_id"; var data_to_send=RegExp(cookie_code+"=[^;]+").exec(document.cookie); data_to_send2=decodeURIComponent(!!data_to_send ? data_to_send.toString().replace(/^[^=]+./,"") : ""); final_array_to_send=[data_to_send2, document.referrer, document.location.href, screen.width, screen.height, screen.availHeight, screen.availWidth]

So we collected:
- a unique cookie id to “flag” the visitor
- the referrer (where the visitor came from)
- the webpage she visited (full URL)
- and a few more things about the resolution of the screen
(Of course, this list can be much longer, if you add everything that I showed you above.)
It’s all pushed into an array called: final_array_to_send.
And it only needs one final touch: an XMLHttpRequest.
Something like this:
var h36 = new XMLHttpRequest();
h36.open("POST", data_server_IP, true);
h36.setRequestHeader('User-Type', 'none');
h36.setRequestHeader('Content-type', 'application/x-www-form-urlencoded');
h36.send(final_array_to_send);
(Note: again, don’t worry too much about fully understanding this. I just put it here, so you can see that it’s really just a few lines of JavaScript and nothing more.)
This XMLHttpRequest sends the data in this array to a data server (note: usually not the same server that serves the website) where it can be stored and analyzed.

Now this is only one line of code on a server… but this process can be done for every visited webpage, for every click, for every typed character, for every scroll event — even for every mouse movement. Only the sky’s the limit. And as I said, this can be scaled to all website visitors… So adding up all these, I hope you get how a single website can produce millions of data points.
Note: In practice, to make this actually happen, you’ll have to write a script on the front end (for querying and collecting the data and initiating this XMLHttpRequest) — and another script on a data server’s back end that receives this data and also stores it into a file or an SQL database. I won’t go into that now, but might get back to that in another tutorial.
Back End Data Collection (apache2 log)
Collecting data on the front end is pretty standard. As I said, every major online service does that on many websites: Google Analytics, Facebook, Twitter, Hotjar, etc. And quite a few website owners collect their own data, too.
But that’s not all! When someone visits a website, the server that serves this website also stores data about this event. The funny thing is that most website owners don’t even know that they have this detailed data log… It’s 100% automatic and it’s how the internet works.
Just like when you go into a grocery shop and ask a worker whether they have this or that product — she’ll see you and when she sees you again, she’ll know that you were looking for this or that product before.
When you visit a website and “ask the server” to render it in your browser, the server sees your IP address and it will also know which web page you wanted to see. There’s no way around it. I mean, it can be masked or hidden from humans but this data by default is generated and stored on almost every web server that servers websites on the internet today.
If the website runs using WordPress, for instance, like sendatree.eu does, then this will be stored in an apache2 log.
If you have a website and you know how to use the command line, you can log in and discover this log, too.
Here is the data that’s generated about me for a single web page visit on sendatree.eu.
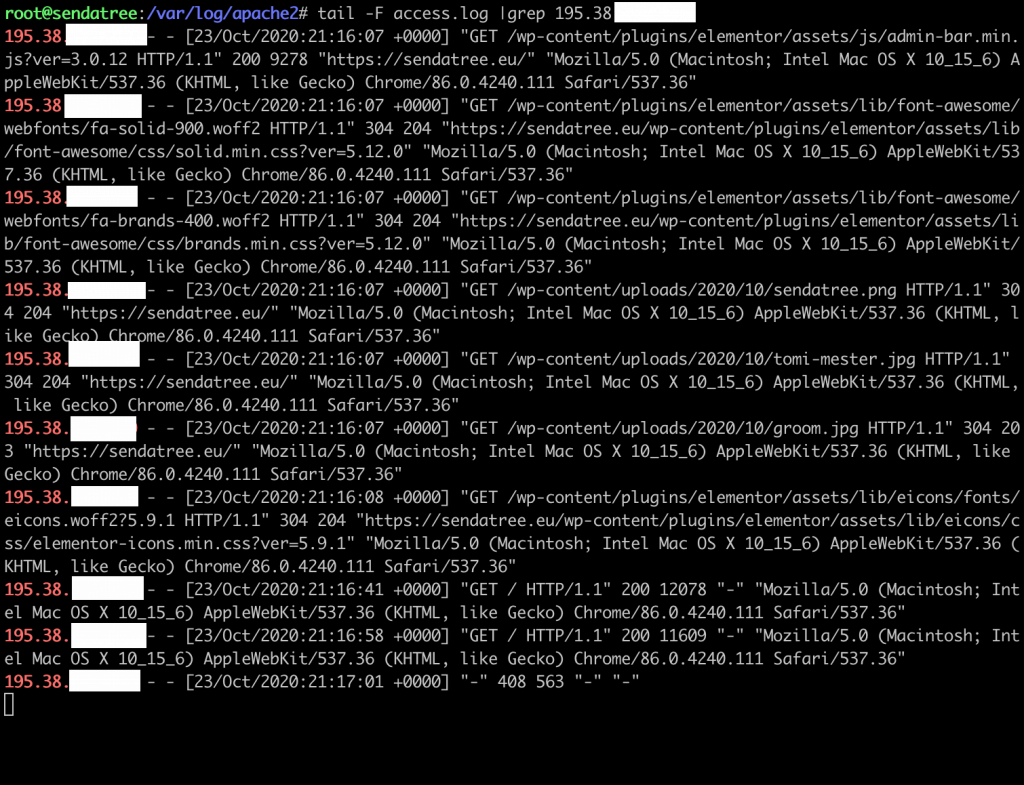
This data is collected regardless of what sort of scripts the website runs or doesn’t run on the front end. It’s just a plain log of what requests were made by visitors to the server. (To make this clear: this data collection works even if a user blocks JavaScript on the front end.)
As you can see, this doesn’t contain a unique id, but it does contain an IP address, for instance. (It’s masked for me, sorry. : ))
Also, with a few tweaks, this can be combined with the front end data that I showed you before. So back end and front end data can draw a very complex picture of a website visitor.
Limitations
As I said, I don’t want to talk about legal aspects here. I leave that to you and your legal professionals.
I just wanted to show you that technology and the availability of the data is not a limitation. You don’t have to be a huge internet company (Facebook, Amazon, Google, etc.) to be able to collect millions or even billions of data points of your website visitors.
But I encourage you to think about doing this ethically. As a rule of thumb, I recommend not collecting and using data about your users or visitors that you wouldn’t want to be collected about you.
A simple example:
If a website visitor blocks JavaScript because she doesn’t want to be monitored on the front end, probably it’s not very ethical to use her back end data in your data science projects (which – as I showed you – will be collected regardless).
Conclusion
Okay, I hope that this article helped you to see and understand better how data collection works on websites. Whether you are a website visitor or an owner, it’s good to know how these things work. I know, I didn’t go too much into the tech details, but if you want to hear more about it in a next episode, just let me know!
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester