
You have an awesome resume, a jaw-dropping portfolio, and a Pulitzer Prize winning cover letter. What’s next? Now we’re getting to the good stuff: applying for a data science position and preparing for the job interview(s).
For most junior data positions, the application process is relatively straightforward: after submitting your application, the recruiter will reach out and you’ll generally have a phone screen with the recruiter. Then, you’ll often be asked to complete a data science task as part of the technical screen. If you pass that, you’ll usually have a more technical conversation with the hiring manager, followed by the final stage: the onsite interview.
But let me show you the details.
In this article, I’ll discuss the following:
- Where to look for job postings
- How to follow up after submitting your application
- How to prepare for the phone screen with the recruiter
- How to impress the hiring team with the technical data assignment
Before we get started…
This article is part of a five article series called: How to get a job in data science and analytics.
Here are all the articles:
- epsiode #1 — Intro: What is a data analyst/scientist and what skills do you need?
- episode #2 — What do you need to do before you apply? (resume/cover letter/website/GitHub help)
- episode #3 — How to apply and how to prepare for data science job interviews and how to ace the take-home assignment — this article
- episode #4 — Common junior data science job interview questions and how to answer them
- episode #5 — How do you negotiate? Should you negotiate? What is the career trajectory for someone in data science and analytics?
Now, it’s time to get into it:
Where to look for job postings
This will be a pretty short section.
The best places to look for job postings are:
…generally in that order.
Note 1: if you end up using AngelList, you will need to put together a profile similar to LinkedIn. There isn’t a magical one-stop shop for all listings, but if you scour these sites you will definitely see the bulk of the job postings in data science and analytics.
Note by Tomi Mester: The above list applies to the US job market. When we are talking about Europe – in my experience – LinkedIn is pretty much the only go-to place when looking for data science positions. Of course, you can always extend your opportunities relying on your personal network. And direct applications through the website of a favorite company of yours is also possible (although it’s not common).
How to follow up after submitting your application
I consider the advice in this section somewhat optional. I would not do this for all the jobs you apply to, but following up for the select few jobs you are really interested in can make a difference.
Okay. So you submitted your application but you haven’t heard anything back. For job openings you are particularly interested in, I would do the following:
- Find the hiring manager’s email. This is generally pretty easy—you’ll just have to do some digging. You can find emails on LinkedIn, or use something like hunter. If you can’t find the hiring manager’s email, try to find someone on the data team.
- Once you have the email address, write a thoughtful email and attach your resume. Keep the email short, but interesting. Say what job you recently applied for, what you like about the company, how you believe you can make an impact, and end with a soft ask. Something like:
| Subject line—Question about joining the Dunder Mifflin data team Body—Dear Michael Scott, I recently applied for Dunder Mifflin’s open data science analyst position. I admire Dunder Mifflin’s commitment to being the people person’s paper people—and I’d love to be part of the team. I love all things data—from helping a social media marketing start-up make data-driven decisions or using data to help a subscription box company predict when users will churn, I have the skills to help Dunder Mifflin use data to make better business decisions. So with that being said, would you have a chance to talk to see if there might be a place for me at Dunder Mifflin? Best, Peter Pescadero |
- Continue to follow up until you hear a response.
Alternative follow-up strategy
Another strategy that works is to message another data analyst/scientist on the team (either email or on LinkedIn), and say something like:
| Hey Peter! Hope you had a good weekend. I noticed that there was a job opening at your company. I’d love to connect and learn more about your journey into data science and how you like it so far at Dunder Mifflin. Let me know if you’re free this week to chat over coffee. |
I would recommend you send this email out before you apply—if they never respond, apply to the job anyway. However, if they do respond, there’s a good chance you can give your resume to them and they can forward your resume to the recruiter.
I particularly like this strategy—for a few reasons. One, most people are nice—and it’s hard to turn down free coffee (quick note: buy their coffee for them). If/when you meet, keep the conversation light; ask them about their experience, what advice they have for you, and what they like about their company.
How to prepare for a phone screen interview with the recruiter
This stage of the application process — the phone screen — is also always pretty straightforward. The recruiter at this point is trying to check a few things:
- You can clearly speak about the stuff on your resume—the recruiter might ask you to explain a project you worked on that used data.
- The recruiter will most likely ask you what your programming background is—generally, they are looking for keywords like SQL, Python packages like maplotlib, Pandas, and NumPy, etc.
- Always have a few reasons for why you are leaving your current job and why you’re interested in this position/company (in a later section, I’ll go into more detail about how to answer some standard interview questions).
- Also, always have a few questions to ask the recruiter as well! Should be common sense, but definitely something that is overlooked when preparing for recruiter phone screens.
- The recruiter might ask about what salary range you’re interested in—see a later section on how to answer the salary range question.
- Be friendly and sound interested and excited. Recruiters are also trying to gauge if you’d be a “good fit.” It’s easier to check off this “good fit” box when you’re friendly and having an engaging conversation with the recruiter.

(Photo by LinkedIn Sales Solutions on Unsplash)
Remember: the recruiter probably does not know much about the position you’re applying for—meaning, they’re not going to ask you technical statistics questions, or questions about SQL/Python/R. They might have a list of questions they’re given to ask, like “have you worked with window functions?” or “what type of statistical modeling techniques have you used?” but the point of these is to make sure you have the skills the hiring manager is looking for.
Lastly, have an open (email) dialogue with the recruiter. If they set up a time to have you talk to the hiring manager, or come in for an onsite interview, ask them if they have any advice or anything that might be helpful to prepare for. As the application process goes into the later and later stages, recruiters want to get positions filled, and there is a good chance they will offer at least some advice. The more information you can have at each step of the process, the better.
How to impress the hiring team with the take-home data assignment
Oh, the famed take-home data task. In this section, I have a list of DOs and DON’Ts for you, as well as a conceptual discussion on how to ace the take-home assignments. (These are based on real assignments from some of the biggest tech companies.) I’ll also show you how I would approach the questions, how I would approach writing the code, and how I would present my results.
In this technical screening step, there are usually two types of tasks:
- Timed programming challenge. I do not have much advice on how to prepare for these. Most companies (that I know of) do not use this as a step in the application process, but if you find yourself having to complete one of these, just do your best and don’t stress about finishing in the allotted time—just make sure what you can finish is correct and a good representation of your programming skills.
- Data analysis challenge. This is the most frequently used technical screen. It usually involves a dataset and some questions to show off your programming skills as well as your ability to analyze and synthesize results. This section is focused on this type of technical challenge.
The data analysis challenge is used to evaluate the following:
- Can you demonstrate the technical skills you discussed in your resume?
- Are you able to handle and clean messy data?
- Is your code clean, well-written, and well-documented?
- Are you able to clearly communicate and present your results?
This data assignment phase is where you can initially stand out in the interview process.
If you follow my advice, you can set yourself apart from the other applicants with a strong data assignment. Other than the resume/cover letter step, this is the one phase of the application process you have complete control over. You can generally spend as much time on it as you want, troubleshoot your code, look at resources online if you need to, and think through how you want to approach the task and how you want to present your work.
DOs and DON’Ts for the data science take-home assignment
So with that said, here are some DOs and DON’Ts for how to be successful in the take-home assignment stage:
- DO: if you’re really interested in the job, finish the assignment. Not sure why this is the case—but a fair number of the assignments I review are incomplete. If you really want to make a strong impression, finish the assignment.
- DO: make it extremely easy for the team to review your assignment. In 99.99% of cases, all you need to send back are two files: one text-file of your code, and one PDF with the questions you had to answer in bold, and your answers/visualizations/results below.
- DON’T: send a Jupyter notebook, html file, etc. You run the risk of the formatting being off and it will look disjointed and clunky. Just think about this: if you get hired, your job would be to take a question, use data to answer that question, and present and/or communicate your findings to non-technical people. You’re not going to send someone on the marketing team a Jupyter notebook where they have to sift through the code.
- DON’T: send your code without a write-up of your results/findings. The hiring team will not replicate your results; they probably won’t even look at it. You’re wrong if you think people will spend the time debugging your code, making sure the directories are correct, all the packages are installed to run, etc. Again, you’re not going to send an executive a text file saying “make sure to install the following packages to review my findings.” So don’t do that in your data task.
The people looking at your assignments are interested in two things: clean code and clear storytelling ability—so make sure to demonstrate that in your assignments!
Examples of a junior data scientist’s take-home assignment
Now, I’m going to describe two database schemas that are similar to what might be given to you. I’ll discuss:
- potential questions you could be asked to answer using the data or questions you should consider answering if the prompt is vague,
- how you should approach answering those questions, and
- potential “Easter eggs” and things to look out for and consider while doing your data cleaning and analysis.
But first, let’s quickly discuss the two files to send once you’ve completed the data assignment: a text-file with your code, and a PDF of your analysis and results:
The text file you’ll send back
For the text-file, keep it simple, clean, and well-documented. Format it like the example for the personal project code; see the screenshot below for a reminder:
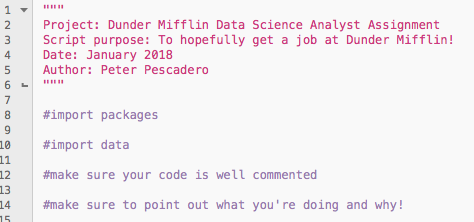
The analysis PDF you’ll send back
For the PDF showing your analysis, keep it organized and easy for whoever is reviewing it to know which question you are trying to answer. See the screenshot below for an example of how to organize and format this page:

Mock Data Assignment #1
Alright, alright, alright. Now I’m going to walk you through the two mock data assignments. I’ll describe a dataset and discuss a few things to consider.
Let’s start with the first one.
(Note: there is no actual data in this section, just a conceptual exercise)
| Column name | Column description |
| Customer_id | Unique alphanumeric ID assigned to customers when they install the application |
| Acquisition_channel | Channel where customer came from before installing application |
| Install_date | Date of application install |
| Account_creation_date | Date of account creation |
| Action_date | Date when user performs an action on platform |
| Action_type | String description of action performed by user on platform |
In most cases, the dataset(s) you are given require at least a little bit of data cleaning. This can be anything from converting variable types, dealing with unnecessary whitespaces, things like that. Not to make you paranoid, but it appears to be relatively common for companies to have a few “Easter eggs” in the data—either in the data cleaning stage or the analysis stage of the assignment. So, it is important to keep this in mind and be on the lookout for things like null or missing values, incorrectly spelled data, and certain IDs acting like “bots” that will screw with your results. When you find these types of things, make sure to document them either in your code comments or in your write-up.
Typical questions
Oftentimes, companies will ask super general questions in the data assignment to gauge what insights you can gather from the data; questions like:
- What trends do you see in the data?
- What insights from the data are actionable?
- If there are multiple datasets, how do the datasets differ?
- What are the most interesting findings?
- Can you use a model to predict X, Y, or Z?
- …
Great answers
After cleaning and checking the above dataset for any errors, there are a number of “low-hanging fruit” visualizations you can put together:
- Bar chart showing number of customers by acquisition channel
- Histogram showing length of time it takes users to go from installing the application to creating an account. (The thinking here is that the user experience is like a funnel—and users go from acquisition channel to installation to account creation—a long installation to account creation time suggests that there is confusion or a pain-point for users.) Similarly, you can make a funnel showing what percent of users go from acquisition channel to installation to account creation
- Plot showing number of actions by day. You can also divide users into cohorts based on when they installed the application. Do different cohorts tend to behave differently?
Obviously, this list isn’t exhaustive. But it should give you a good idea of some simple visualizations you can put together to show companies that you can clean data and present it in an aesthetically-pleasing way.
You can also suggest using the data for prediction. For example, based on when and what action a user takes, can you predict when and what their next action will be?
And lastly—even if they don’t ask, it is also good practice to have a short section at the end with any questions or concerns you have about the data and possible avenues for further analysis. You want to make the most out of the opportunity to showcase that you are vigilant and concerned about data integrity (meaning, you make sure the data is correct/accurate/error-free), and you are thinking about other ways to analyze and glean insights from the data.
Mock Data Assignment #2
Note: there is no actual data in this section, just a conceptual exercise
| Column name | Column description |
| Activity_date | Activity date of an action on platform |
| User_id | Unique alphanumeric ID assigned to user |
| Device_type | Type of device |
| Time_on_page | Length of time user stayed on a specific page |
| Content_genre | String description of content genre |
| Page_title | Title of page |
| Content_length | Length of content on page (i.e., number of words) |
Similar to the mock data assignment #1, here are a few visualization ideas:
- Histogram showing lengths of time users tend to stay on a page—what about segmenting this by content_genre or content_length?
- Bubble chart showing most popular daily content
- Donut chart showing site activity by device type
Can you cluster or segment users based on what content they consume? In addition, if this was a publishing platform, can you tag a user as an “entertainment” or “sports” reader? Does the length of the page title have any effect on how “popular” content is? Does it get more visits if the title is longer/shorter?
Try to push yourself to come up with at least one visualization that you know other applicants will most likely not have—you want to stand out and demonstrate your critical thinking and creativity. You want whoever is reviewing your assignment to think to themselves, “Huh, that’s pretty cool.”
Go on to the next episode!
So this is all you have to know about the application process for a data science position. We covered: where can you look for job postings? We talked about following up after submitting your application. You got some advice to prepare for the phone screen with the recruiter. And we also reviewed how to win the take-home assignment.
If you passed these rounds, the hiring process is not over. It’s time for the onsite interviews. And as of that, in the next article I’ll show you the most common junior data science job interview questions — and also how to answer them! Here.
- If you want to learn more about how to become a data scientist, take Tomi Mester’s 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out the 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Peter Scobas