

James Rice was a participant in my 6-week data science course (The Junior Data Scientist’s First Month). After finishing the course, he started a cool hobby project and shared it on the internal Slack forum for the course. And I found it to be another perfect example of a hobby project that junior data scientists need to boost their portfolio. It’s about a more advanced SQL method (recursive queries) and a fun game regarding Kevin Bacon… But I’ll let James continue from here on:
I’m excited to share a hobby project I developed involving two of my favorite things: movies and SQL. To understand what my project is, it helps if you first know about the Kevin Bacon game.
Six Degrees of Kevin Bacon
For the uninitiated, the Kevin Bacon game (sometimes called “six degrees of Kevin Bacon”) gives a player the name of an actor and then the player tries to find the shortest path between that actor and Kevin Bacon. Kevin Bacon explains in his TEDx Talk:
“In case you haven’t heard of this game, the idea is that any actor alive or dead can be connected to me, through our work, in six steps or less.”
For example, if the game was played using actor “John Malkovich,” one player might say:
“John Malkovich was in Of Mice and Men with Gary Sinise, who was in Apollo 13 with Kevin Bacon.”
Using a single person to connect them is pretty good, but, they could be beat if another player said,
“John Malkovich was in Queen’s Logic with Kevin Bacon.”
Because the second player uses fewer steps to get to Kevin Bacon, this means their answer wins over the first. You get the idea.
Note: if you are absolutely new to SQL check out this tutorial article series or this video tutorial series to learn the basics.
Using SQL to Win the Kevin Bacon Game
So then what exactly then is my hobby project?
I describe it as a query in SQL that uses a recursive common table expression (‘CTE’) to find the shortest path from that actor to Kevin Bacon. Perhaps put more simply, it’s a way to cheat your way to victory in the Kevin Bacon game!
Here’s what my SQL query looks like for the “John Malkovich” example I mentioned above:
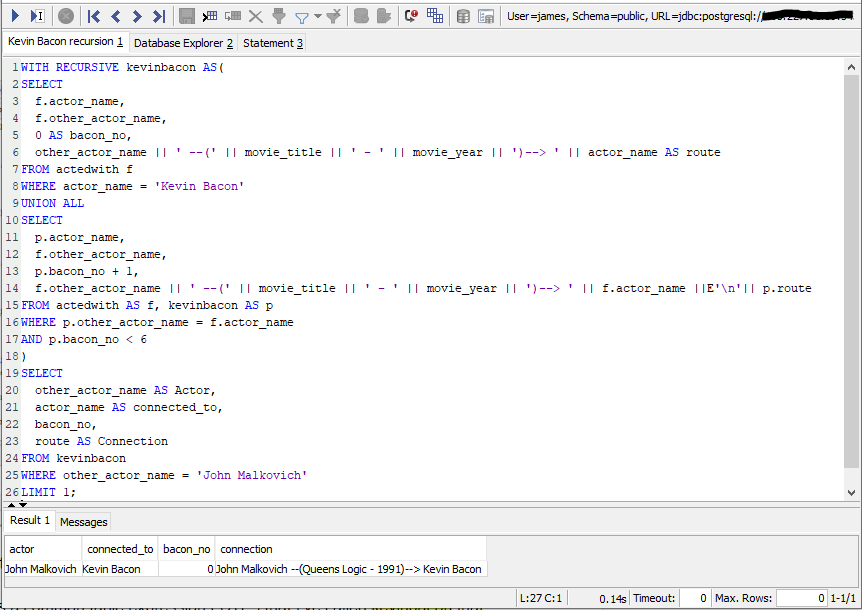
WITH RECURSIVE kevinbacon AS(
SELECT
f.actor_name,
f.other_actor_name,
0 AS bacon_no,
other_actor_name || ' --(' || movie_title || ' - ' || movie_year || ')--> ' || actor_name AS route
FROM actedwith AS f
WHERE actor_name = 'Kevin Bacon'
UNION ALL
SELECT
p.actor_name,
f.other_actor_name,
p.bacon_no + 1,
f.other_actor_name || ' --(' || movie_title || ' - ' || movie_year || ')--> ' || f.actor_name ||E'\n'|| p.route
FROM actedwith AS f, kevinbacon AS p
WHERE p.other_actor_name = f.actor_name
AND p.bacon_no < 6
)
SELECT
other_actor_name AS Actor,
actor_name AS connected_to,
bacon_no,
route AS Connection
FROM kevinbacon
WHERE other_actor_name = 'John Malkovich'
LIMIT 1;
If this is a little intimidating, let me break down what’s going on in the code.
The top portion is a common table expression (‘CTE’) that I’ve named kevinbacon that gets referenced in the query at the bottom. This bottom part is a fairly straightforward SQL query:
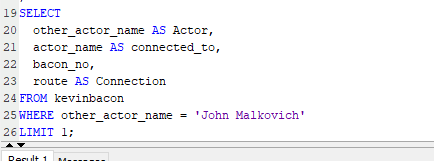
Note that the variable other_actor_name in this bottom part of the query is used to specify which actor I want to connect to Kevin Bacon.
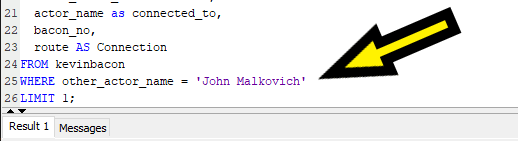
But the real heart of this query is the top part: a CTE that recursively joins itself to grow a list of connections between actors. I have highlighted the name of the CTE and its alias to show the way in which the CTE is recursive, that is, how it refers to itself in its execution:
In this post I’ll explain the approach I took to making this hobby project and some of the challenges I faced, but first I’ll start with my “why.”
0. Inspiration: Learning About Recursion In SQL Server
Near the end of 2020, I worked my way through DataCamp’s Data Analyst with SQL Server Track. One of the courses in the track covers recursive queries in SQL Server. The instructor introduced a clever use for recursive queries: finding the shortest route between two airports when you have a database of flights with departure and arrival airports listed.
But after completion of this SQL Server course I felt like I didn’t really understand how that recursive query actually worked. Like many online coding courses designed for beginners, each lesson involved filling in one or two blanks in a set of code that was largely already set up for me. As a result, I was left craving a deeper understanding of how recursive queries work in SQL.
It’s been said many times that a great way to learn a new technology is to build a hobby project with it. And it struck me that my course’s application of creating the shortest path between airports connected by flights was somewhat similar to six degrees of Kevin Bacon, connecting actors by the movies they were in. Thus, the seed of inspiration was planted.
Borrowing heavily from the recursive airport example, I scrawled my ideas for my Kevin Bacon game app on a notepad:

As you may be able to tell — if you can read my handwriting 🙂 — I had three steps in mind to getting my Kevin Bacon query to work:
- Getting the right data into the database.
- Joining the data to make it usable.
- And of course, setting up the SQL query.
I followed this plan but each step presented unforeseen challenges.
1. Finding the Right Data
The first step in a data science project is to track down the data. I knew that I needed info that could be used to connect actors to the movies that they were in. Initially I considered paying for access to one of several movie database APIs I found. But eventually I discovered a page on IMDb that had what I was looking for without having to shell out any money: www.imdb.com/interfaces/.
They have a dataset called title.principals that I used, after a little manipulation, to connect actors to the movies they starred in.

This data was helpful to establish the relationship between actors (identified with the variable nconst) and films (tconst). However, this dataset is missing other data that I needed, like the names of the actors and the names of the movies. Otherwise, the results of the Kevin Bacon query would be pretty lame: e.g. “nm0000518 was in tt0102741 with nm0000102.”
Also, as I worked on my project, I discovered that title.principals includes a lot of data that I didn’t really want. For example, I only wanted to consider movies, but IMDb’s data includes television shows. And, the data includes both cast and crew, but I only wanted the cast members.
Fortunately, IMDb has additional datasets that I could use to connect tconst and nconst to the information about movies and actors. These datasets contained fields that could help me filter out the extraneous data, too.
The movie information was located in a dataset they call title.basics:

And actor information was located in a dataset they call name.basics:

2. Loading and Transforming the Data
The second step in my project involved putting the data into a format that my recursive SQL query would be able to use. My idea was that the table I would create would have a row for every connection between two actors, showing the movie name and year.
After downloading and unzipping the .gz files containing the three datasets, I filtered them to get only what I wanted:
title.principals:- I used the
categoryfield to filter for only the cast and crew identified as eitheractororactress. This got rid of data for people who were producers, crew, etc. - I dropped the
ordering,category,job, andcharactersfields. - This gave me a table with just two fields:
tconst(the unique identifier for movies) andnconst(the unique identifier for actors).
- I used the
title.basics:- I used the
titleTypefield to select only data identified as ‘movie’. - I dropped the
titleType,originalTitle,isAdult,endYear,runtimeMinutes, andgenresfields. - Ultimately this gave me a table of only movies with the fields for
tconst(the unique identifier for each movie),primaryTitle, andstartYear.
- I used the
names.basics:- I dropped the
birthYear,deathYear,primaryProfession, andknownForTitlesfields. - This gave me a simple table with just the
nconst(the unique identifier for each actor) andprimaryNamefields.
- I dropped the
Next, I joined the data together. I used the nconst field to join my modified names.basics table with my modified title.principals table. I then joined this data to the modified title.basics data, making it so that the movie name and year were included. With this step, I had a table with the actors’ names alongside their unique IDs and the name, ID, and year for the movie, with each row representing an actor’s appearance in a movie.
All of these changes could have been made in SQL, but I happened to use python within a Google Colaboratory notebook. Google Colaboratory will look familiar to you if you have experience using jupyter notebooks. I like using it for exploratory data analysis on projects, especially during the exploratory data analysis stage. My changes to the data were consolidated into a single file, movies.csv, that I transferred over to my remote data server.
Now it was time to insert this data into my Postgres database. Here’s how I accomplished that:
CREATE TABLE movies (
movie_id TEXT,
movie_title TEXT,
movie_year INTEGER,
actor_id TEXT,
actor_name TEXT);
COPY movies FROM '/home/james/kevinbacon/movies.csv' DELIMITER ',';
At this step, here’s what my table (movies) looks like:
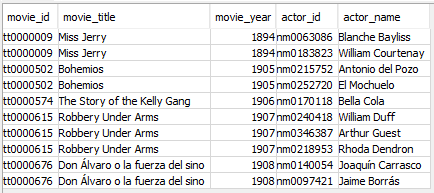
However, what I wanted was a table to represent the connection between each combination of two actors appearing in the same movie. I accomplished this by performing a self-join whereby the actor ID and actor name field would be joined only if the movie ID (tconst) was the same while the actor ID (nconst) was not. The resulting table, which I named actedwith, has a row for every time an actor appeared in a movie with another actor.
CREATE TABLE actedwith (
actor_id text,
actor_name text,
movie_title text,
movie_year text,
other_actor_id text,
other_actor_name text);
INSERT INTO actedwith (
SELECT
a.actor_id,
a.actor_name,
a.movie_title,
a.movie_year,
b.actor_id AS other_actor_id,
b.actor_name AS other_actor_name
FROM movies AS a
LEFT JOIN movies AS b
ON a.movie_id = b.movie_id
WHERE a.actor_id != b.actor_id);
Here’s an example of the layout of my actedwith table’s data for The Room (2000):

3. Setting up the Recursive Query
The final step to my project was to implement the recursive query itself and test it out.
Since my Kevin Bacon game query was largely modeled after the query demonstrated in DataCamp’s course, I was confident that I could make the query work with only some minor tweaks. However, I forgot a crucial consideration: my course was using MS SQL Server syntax, and I was working in PostgreSQL. Therefore a lot of my work in this part of the project involved translating my concept from SQL Server over to PostgreSQL.
I discovered some important differences between SQL Server and PostgreSQL for my project. For one, in SQL Server you use + to join strings but in Postgres you use || to do so. A further important difference is that, when declaring a recursive common table expression (‘CTE’) in SQL Server, you start it using syntax like the following:
WITH kevin_bacon (Actor, AlsoIn, degrees, route) AS (...
But this doesn’t work in PostgreSQL, which I found would throw an error message unless I used a keyword to identify that the CTE was going to be run recursively:
WITH RECURSIVE kevin_bacon AS (...
Between the documentation and lots of Googling, I was able to effectively translate my concept into a format that worked in PostgreSQL:
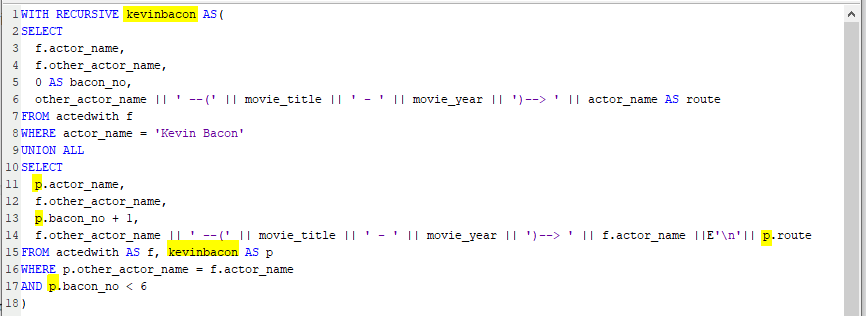
WITH RECURSIVE kevinbacon AS(
SELECT
f.actor_name,
f.other_actor_name,
0 AS bacon_no,
other_actor_name || ' --(' || movie_title || ' - ' || movie_year || ')--> ' || actor_name AS route
FROM actedwith AS f
WHERE actor_name = 'Kevin Bacon'
UNION ALL
SELECT
p.actor_name,
f.other_actor_name,
p.bacon_no + 1,
f.other_actor_name || ' --(' || movie_title || ' - ' || movie_year || ')--> ' || f.actor_name ||E'\n'|| p.route
FROM actedwith AS f, kevinbacon AS p
WHERE p.other_actor_name = f.actor_name
AND p.bacon_no < 6
)
SELECT
other_actor_name AS Actor,
actor_name AS connected_to,
bacon_no,
route AS Connection
FROM kevinbacon
WHERE other_actor_name = 'John Malkovich'
LIMIT 1;
I’ll walk through what each part of the recursive portion of the query does:
- First I tell PostgreSQL that I am going to declare a recursive query aliased as
kevinbacon. [WITH RECURSIVE kevinbacon AS(] - Next I tell the database to give the following info for every row in my
actedwithtable where Kevin Bacon is listed in the fieldactor_name[
SELECT f.actor_name, f.other_actor_name, 0 AS bacon_no, other_actor_name || ' --(' || movie_title || ' - ' || movie_year || ')--> ' || actor_name AS route FROM actedwith AS f ]:
actor_name, which because of theWHEREclause (WHERE actor_name = 'Kevin Bacon'), will all say “Kevin Bacon”;other_actor_name, which is the name of an actor that has been in a movie with Kevin Bacon;- the number 0, aliased as
bacon_no, because sometimes Six Degrees of Kevin Bacon uses the term “bacon number” to communicate an actor’s number of connections away from Kevin Bacon (while I have used 0 as the starting point, others may use 1) - The
routefrom the other actor to Kevin Bacon expressed in the following pattern: “OTHER ACTOR’S NAME –(MOVIE NAME – YEAR)–> Kevin Bacon”.
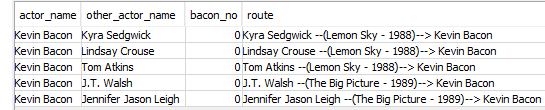
- Next I tell SQL to add additional rows (
UNION ALL) to thekevinbaconquery using information from theactedwithand what’s been pulled up bykevinbaconso far. It has the same columns as in the above part except that:-
bacon_nois increased by 1 each time it runs (p.bacon_no + 1) other_actor_namewill be the actor this time around who matches up in ouractedwithtable from the last timekevinbaconiterated (FROM actedwith AS f, kevinbacon AS p WHERE p.other_actor_name = f.actor_name)- The
routegenerates the “OTHER ACTOR NAME –(MOVIE NAME – YEAR)–> ACTOR NAME” text for this connection and adds that, with a line break, to therouteconnection from the previous iteration ofkevinbacon(f.other_actor_name || ' --(' || movie_title || ' - ' || movie_year || ')--> ' || f.actor_name ||E'\n'|| p.route) - Because I don’t want this query to potentially run for a really long time or run out of space (more on that below), I limit the query to 6 connections away from Kevin bacon (
p.bacon_no < 6)
-
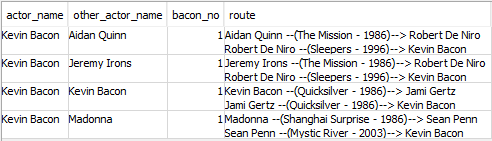

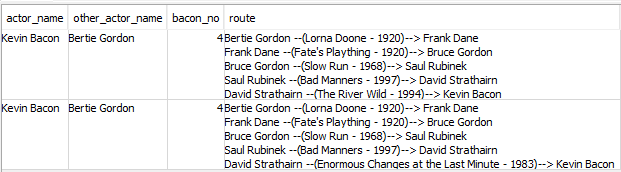
A challenge I needed to overcome was how memory intensive a recursive query can be, especially handling a large dataset. As I encountered while debugging my project, a recursive query will crash whenever it runs out of space. I repeatedly ran into this frustrating error message:

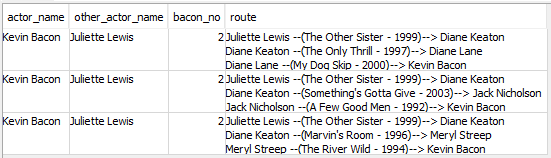
But luckily, I didn’t need every connection between a given actor and Kevin Bacon for my project. In fact, I just wanted the shortest path. By setting LIMIT 1 in the other part of the query that comes after the kevinbacon recursive query, the query stops running as soon as it has the first result from the kevinbacon CTE where the actor name matches. Because of the way the CTE is set up to add connections as it runs, the first match is also the shortest path.
Thus, if I want to find the winning path from Charlie Chaplin (“Charles Chaplin”) to Kevin Bacon, the bottom query (that comes after the kevinbacon recursive CTE) and its results looks like this:
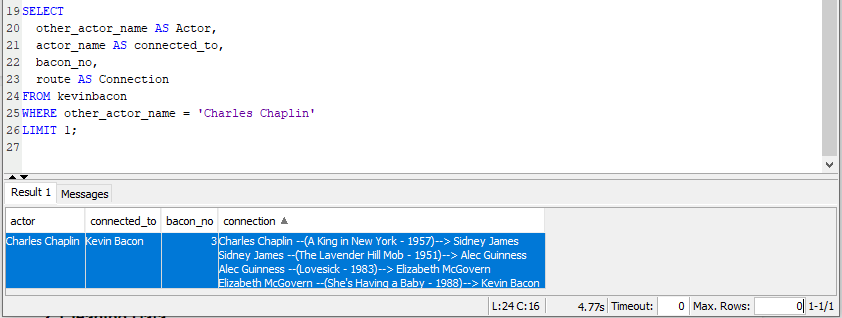
Conclusion
I set out to learn more about recursive queries and this hobby project was a great step toward that goal. I also found it satisfying each time I overcame one of the many challenges that presented themselves along the way.
I hope you enjoyed reading about my hobby project and that you are inspired to build your own.
By the way, if you are interested in other approaches to six degrees of Kevin Bacon, I recommend checking out The Oracle of Bacon and “Six Degrees of Kevin Bacon (with a Graph Database).”
Cheers,
James Rice