
Smaller companies have smaller data teams (maybe just one person), bigger companies have bigger. The tricky thing is that the several different aspects of a data project need several very different kind of skills.
How should you build up your data team to make these skills work best together? I’ll show you through an example of a fictional startup.
Your fictional startup flies! Yay.
Note: For the sake of the example I tried to come up with a startup that definitely doesn’t exist. But you can apply the scheme I am going to show you here to any online businesses.
Okay. Let’s say you are one of the founders of Adtrefa.io (Adopt trees from Australia)! You came up with the wonderful idea of helping people to adopt trees from Australia. Cool. You’ve already built the web application – and it flies! In one month you’ve got 10.000 users. Then next month another 10.000. You are constantly growing, the dream come true.
As a wise startup founder you know that:
- yes, your instincts worked, you’ve built a great thing that people care about, and now
- it’s time to understand your users and get your first data professional on board.
But before you start to hire, it’s worth understanding how data analysis and data science works in online businesses like yours. Here you go!
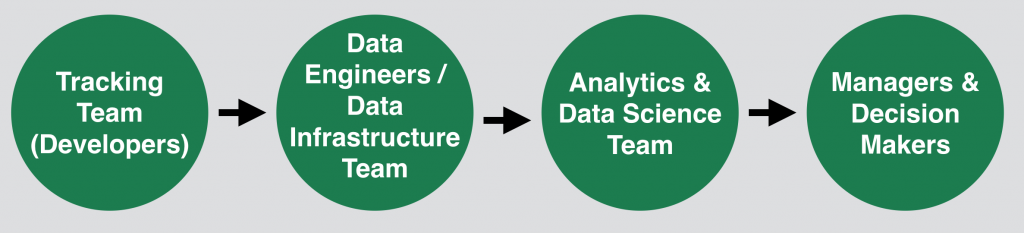
The flow of data in different data teams.
First, let’s see how already established Data Teams are doing it at bigger companies.
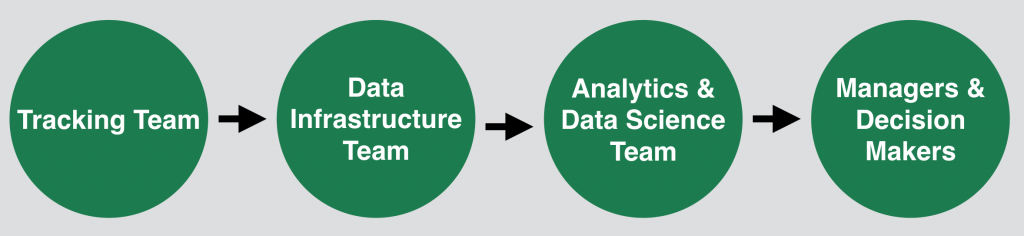
Usually the whole process starts with the Tracking Team, which is responsible for data collection. They pass the data to the Data Infrastructure Team, which takes care of the data storage. From the stored (and sometimes already cleaned, restructured and/or aggregated) data, the Analytics/Data Science Team picks what it needs for its analyses and it turns the data into meaningful insights. Eventually these insights land at the Managers and Decision Makers, who take action based on the findings!
The different tasks – in your data projects
Parallel with the chart above – this is the flow of the data between the different tasks:
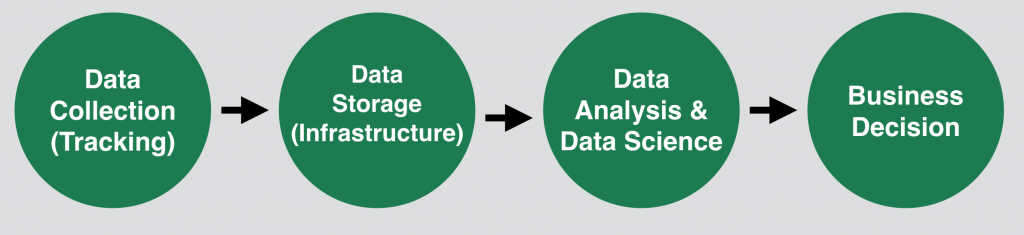
It has four major steps too:
- Collecting the raw data. How to do it right? I’ve written a detailed article about that before: How data collection works
- Storing the data. For business people this step might look banal – but it’s not. In online businesses building a good data infrastructure is not easy or self-evident at all. It’s not necessarily complicated either, but it’s good to know that there could be many technical questions – especially about scaling (which may be the most important factor for a startup).
- Analyzing the data. This is the step in which your data turns into meaningful information after applying different research methods (eg. cohort analysis, funnel analysis, segmentation, predictive analytics, etc…).
- Making a business decision. Never forget, that the original goal of your data project was to understand your users and translate data into actions (eg. optimization efforts).
You can break down this data flow into smaller tasks, but I won’t go into that in this article.
Also, some people would argue that data cleaning should be mentioned here. I left it out, because the data cleaning can happen either as part of the Data Infrastructure or Data Analytics – so I didn’t want to specify who on your data team should do it.
Different skills for the different steps
As I described in the intro: the tricky thing is that different parts of a data project need different skills.
The data collection and storage part requires more engineering skills. The analytics part needs a mix of coding, statistics and business knowledge. And the decision part needs a business mindset, of course.
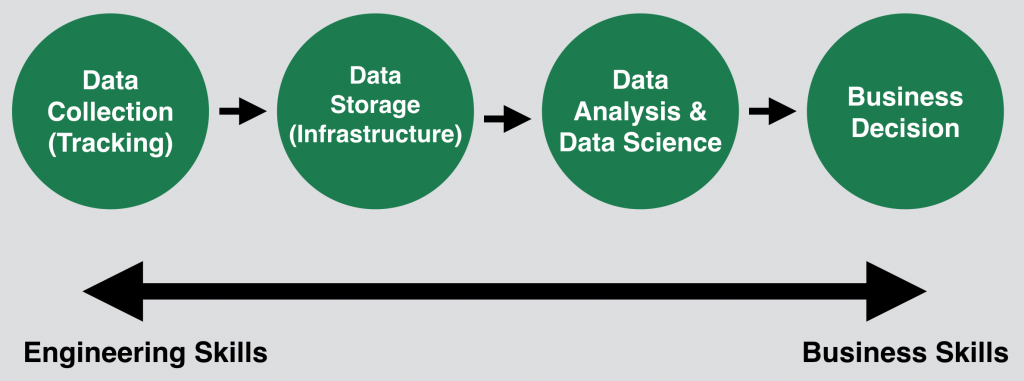
But this is not black or white! E.g. none of the managers can make decisions without at least having a high-level understanding of the engineering process. And none of the engineers can build meaningful easy-to-use infrastructure without knowing the business and analytical needs.
So who does what in your data team?
- As I see it, the data collection (aka tracking) should be done by the same people who are building the codebase of your product/website. Why? The tracking scripts will go into production. As your developers know your codebase the best, they will be able to write those scripts without breaking anything.
- The Data Storage should be built by a data infrastructure expert. The most common name of this position is Data Engineer.
- The Analytics and the Data Science part is done by data research experts. The most common names for this position are: Data Analyst and/or Data Scientist. (There is a slight difference between the two. Learn more in my Youtube video: Data Scientist or Data Analyst)
- And the business decisions are made by the management or other decision makers.
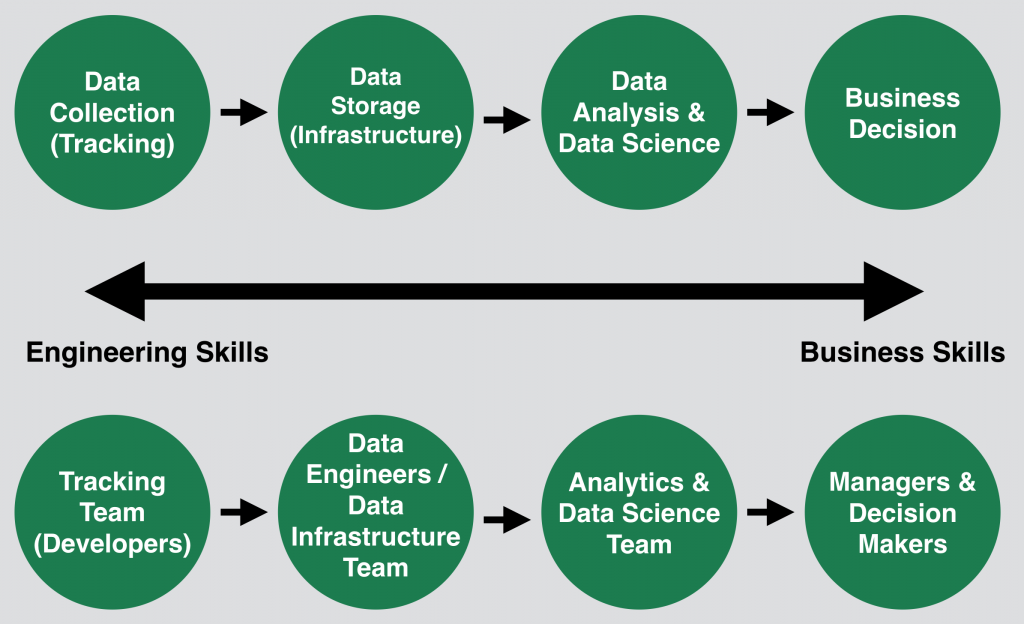
The good thing is that you will already have the first bubble (developers) and the last bubble (decision makers) in your company. So you only need to fill up the Data Engineering and the Analytics positions…
Who to hire first? A Data Analyst or a Data Engineer?
Good question! Let’s get back to the Adtrefa.io fictional startup project!
Mid size companies (~500 employees) usually have at least 3-4 Data Engineers on the Data Infrastructure Team and around 6-10 Data Scientists and Analysts on the Analytics Team (sometimes Data Scientists and Analysts are split into 2 teams). Of course the exact numbers and the exact structures differ from company to company.
Your problem – as a startup – is that you can’t and won’t hire 10 people immediately to do data projects.
In a very ideal case you could hire 2 people though:
- A data engineer who is a great fit with your developers in terms of engineering skills. (Fluent in your platform’s programming language and in the common data languages.)
- And a data analyst who knows SQL and Python or R – and who is very talented in business thinking.
If you can hire only one person, I’d go with the Data Analyst first – but in this case make sure that she/he has above average technical skills as well (preferably fluent in the above mentioned languages: SQL + Python or R). If she has a good understanding of technical things, then she and your developers will be able to build a “bridge” until you can hire your first Data Engineer. And with that, you can start your first data project without a well-established Data Infrastructure (Team).
If you go this way, your second hire on the Data Team definitely has to be a Data Engineer, who can focus on building a Data Infrastructure that will scale with your company, when the growth reaches 1M or 10M users.
If you have done these first two data-hires right, these people will be able to advise you on how to extend your data team in the future – based on their needs.
Working together. Communication across the data team.
Communication is key. And this is true for data projects as well. Across your four data teams – everyone should talk to everyone.
When developers are passing the data to the Infrastructure Team, they talk and create things together. No question about that.
It’s obvious that the same happens when the Infrastructure Team passes the data to Analytics Team and when the Analytics Team provides the insights for Managers.
But here, I’d like to emphasize that subteams who are not in daily contact with each other should communicate as well! For example, managers should know, what Data Engineers are doing. This helps them to understand, for instance, why data servers cost so much and what this means budget-wise for the company (so they can calculate the ROI of the data projects). Or another example: developers should understand, what Analysts/Data Scientists are doing, because it helps them figure out what kind of data to collect. And so on and so forth.
Conclusion
Your data flow goes through these four steps:
- Collection
- Storage
- Analysis
- Decision.
And in parallel with that, these four sub-teams will be working on it:
- Developers
- Data Infrastructure Team
- Data Analytics/Data Science Team
- Managers.
Everyone in this process should have at least a high-level understanding of this whole process. That’s the only way to build an efficient data team and turn your raw data into meaningful, useful and successful decisions!
If you want to be notified first about new content on Data36 (like articles, videos, handbooks, etc.), sign up for my Newsletter!
Cheers,
Tomi Mester