
Do you remember when I told you in the first tutorial that “sooner or later you’ll come to a point where you have to collect large amounts of data”? No? Well, I wouldn’t remember either, so don’t lose sleep over it.
Anyway, I didn’t mean it as just an introductory sentence at the beginning of an article. I rather meant it as a promise – because now you’ve arrived to that point where you’ll collect lots of data.
And by lots of data I mean you’ll scrape 1,000+ product pages.
But first you have to get ready by learning something new.
So read on and get ready. 😉
Defining your own User-Agent for web scraping with Requests
A moment of honesty: so far we’ve been lucky enough that we’ve been able to fetch information from Book Depository.
Why? After all, web scraping is just as simple as writing a few lines of code to collect the data we need, right? Well, not exactly. Let me show you why.
See, when we request information from a web server with Requests, this is how we introduce ourselves:

If you type in response.request.headers, you’ll see what web servers detect when we request a page from them. Our User-Agent HTTP header tells it right away that the “person” requesting the web page is… not a person. 🙂
It becomes immediately clear to the web server that we’re scraping the website with the Requests Python library ('python-requests/2.25.1').
(A User-Agent in our case is our browser that represents us, but you can read more about user-agents here.)
You should be familiar with the concept of User-Agents if you plan on scraping other websites as well. The thing is, web servers can block access to their website if they detect that you’re doing some scraping. In such case, you’d encounter a similar message:
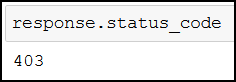
403 means that the web server refuses your request. And we really don’t want that to happen, so let me introduce to you your next favorite tool in your web scraping arsenal, the headers parameter. headers does magic for us; it lets us define how we’d like to introduce ourselves to web servers.
How does the headers variable work?
Let’s create our headers variable:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36",
"Accept-Language": "en-US,en;q=0.5",
"Referer": "https://google.com",
"DNT": "1"
}
With the above code we’ll look like a person using a Mozilla browser on a Windows machine (“User-Agent”) who understands English (“Accept-Language”), comes from Google (“Referer”), and doesn’t want to be tracked (“DNT”:”1”).
Now we just have to add headers to our already known routine:
requests.get(url, headers=headers)

See? We already look more person-like. 😉
This is all you need to know for now, but if you wish to gain a deeper understanding about what we’ve just done, watch John Watson Rooney’s video on this topic.
Of course, there are several other ways web servers can detect web scraping, so changing your User-Agent won’t always be enough. Anyway, for our purposes it’ll suffice, so let’s get back to web scraping.
How to get the URLs of product pages
In the second part of the Beautiful Soup tutorial series we scraped every bestsellers page, and collected the titles, the formats, the publication years and the prices of the bestseller books.
There we have created a while loop that went through all pages and scraped the data we needed. I won’t put the whole script here (because it’s long), only the screenshot of it. But you can find the copy-pastable version in the second part of this series.
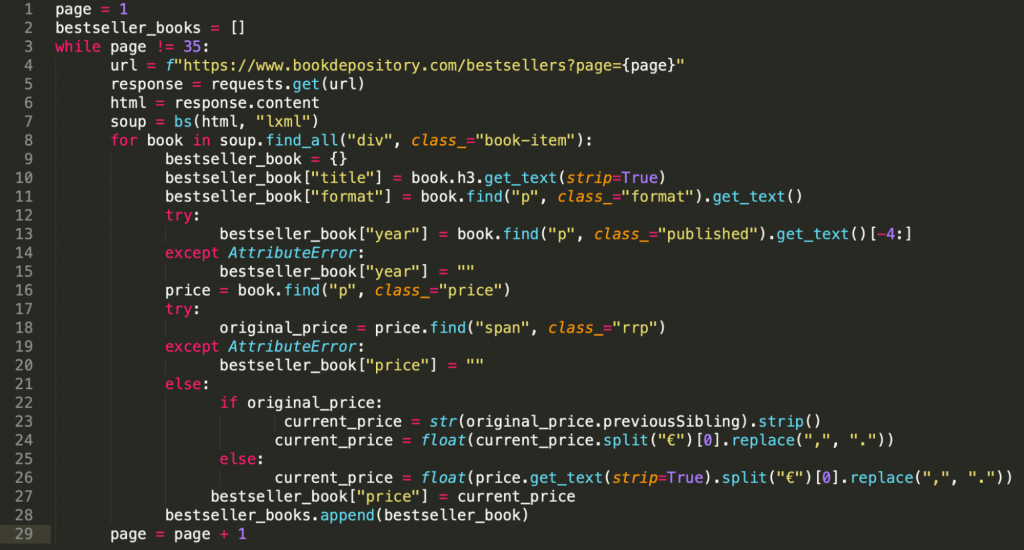
In this article we’ll gather more data, so we can do more analyses and create new visualizations. We’ll get more data by scraping the product pages of the books that made it to the bestsellers list.
First, we’ll have to find the product page URLs of the books. As a matter of fact, we could have already collected these URLs if we had wanted to, but up until now, we didn’t really need them. Let’s fix that:
bestseller_book_url = f'https://www.bookdepository.com{book.h3.find("a")["href"]}'
bestseller_book["url"] = bestseller_book_url
Yes, this is all the code we need to add to our big while loop code from the previous article to get each book’s product page URL. But don’t start scraping just yet, we’ll write more code throughout this article; I’ll let you know when you can start.
Fixing the URLs (url + href)
book.h3.find("a") finds us the a tag in the h3 tag, then ["href"] gets the URL. Well, only part of the URL, as you can see:

Because the href attribute doesn’t hold the whole product page URL, we insert “https://www.bookdepository.com” to get a valid URL. This is what we do with:
f'https://www.bookdepository.com{book.h3.find("a")["href"]}'
Our new web scraping while loop works like this…
After successfully creating the product page URLs, our code from the second tutorial works like this:
whilewe are on a bestsellers page,- we get the URL of the bestsellers page we are currently on with Requests, and create a
soupobject that represents the HTML of the page, - so we can
for loopthrough every book on the bestsellers page, - and as a new thing, we save every book’s product page URL to
bestseller_book["url"]. (Remember,bestseller_bookis a dictionary that holds every piece of scraped information about a given book, like title, format, etc. We add everybestseller_bookto thebestseller_bookslist, so we can later do analyses on them.)
Here’s a screenshot showing part of our already written code (from the previous articles) with our new addition (saving product page URLS):
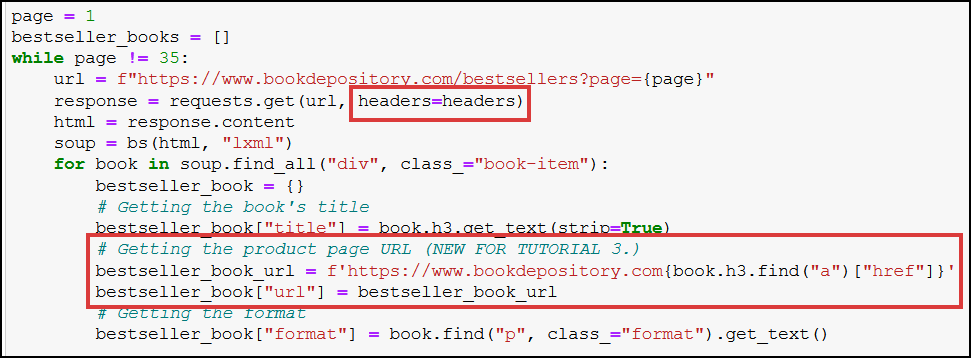
(Yes, I’ve already included headers in our initial request, it’s a good practice worth getting used to. 🙂)
Truth is, we’re not completely done yet with the product page URLs – we also need to scrape them, because we need data that’s only available on product pages.
This piece of code will be familiar to you:
bestseller_book_url_response = requests.get(bestseller_book_url, headers=headers)
bestseller_book_soup = bs(bestseller_book_url_response.content, "lxml")
It’s nothing special, just requesting the product page, then creating a soup object out of it. It should go after the part where we deal with books’ prices in our “old” code:
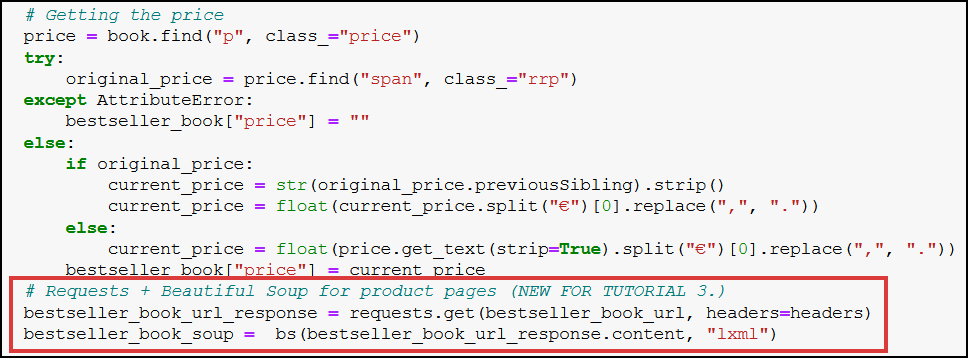
Nice. We’re fully prepared now to start fetching data from product pages. We’re after the book’s:
- author,
- publisher,
- publication city/country,
- length (number of pages),
- categories a book is categorized into.
Scraping author, publisher, publication city/country and length information from product pages
First, let’s get that author information. Here’s where it can be found on the product pages:
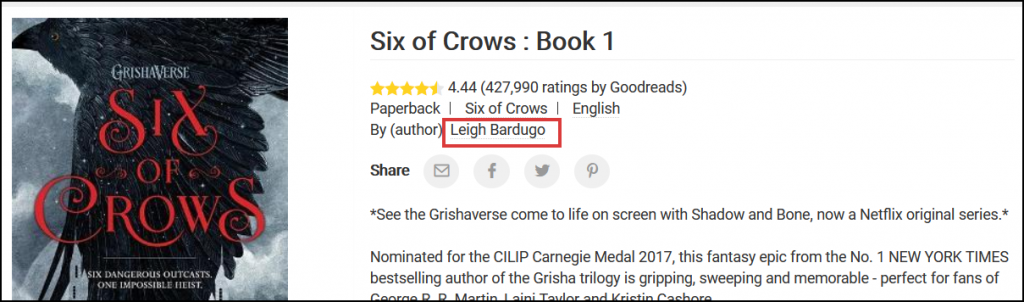
Let’s inspect it in the browser:
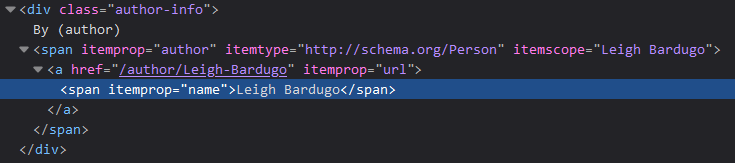
Now we should have a good idea how we can pick this data with Beautiful Soup, and save it to a variable:
bestseller_book["author"] = bestseller_book_soup.find("span", {"itemprop":"author"}).find("span", {"itemprop":"name"}).get_text(strip=True)
bestseller_book_soupholds the HTML content of the product page (see the previous section),.find("span", {"itemprop":"author"})locates the firstspanelement whoseitempropattribute is equal toauthor. Then.find("span", {"itemprop":"name"})searches for aspanwhereitempropisnamein thespanfrom the previous step.- Finally, we get the author data with
.get_text(strip=True), and remove any unnecessary whitespaces (strip=True). The result will be a string, like this: “Leigh Bardugo”.
Try-except for missing scraped data
Naturally, it can happen that no author information is available in which case we’d run into an AttributeError; to handle such cases, we’ll use a try-except block that we’ve already used in the previous article:
try:
bestseller_book["author"] = bestseller_book_soup.find("span", {"itemprop":"author"}).find("span", {"itemprop":"name"}).get_text(strip=True)
except AttributeError:
bestseller_book["author"] = ""
What the above code does is this: if it finds the author information (try block), it’ll save it to bestseller_book["author"], otherwise (except AttributeError) it’ll only keep an empty value (bestseller_book["author"] = "").
The rest is the same…
In a similar vein, we can get the publisher and the length data of a given book. Here’s where they are in the product pages:
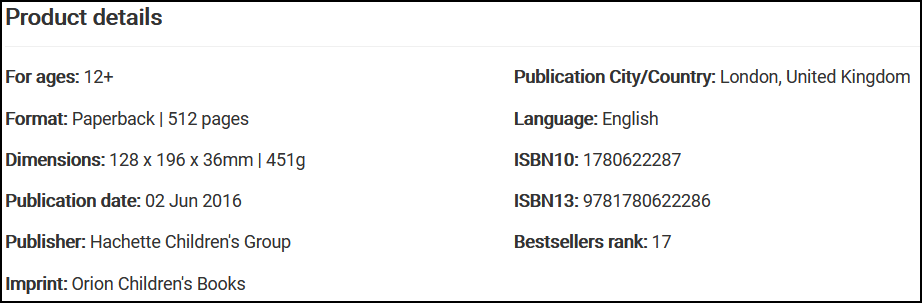
The code for the publisher information:
try:
bestseller_book["publisher"] = bestseller_book_soup.find("span", {"itemprop":"publisher"}).find("span", {"itemprop":"name"}).get_text(strip=True)
except AttributeError:
bestseller_book["publisher"] = ""
The code for the length information:
try:
bestseller_book["length"] = int(bestseller_book_soup.find("span", {"itemprop":"numberOfPages"}).get_text(strip=True).split(" ")[0])
except AttributeError:
bestseller_book["length"] = ""
The code for getting the length data is a bit different, so let me explain why that is:
.get_text(strip=True)gets us both the number of pages and the"pages"text, for instance:“512 pages”,- so we split the string at the space with
.split(" "), - and keep only the first part (
[0]); the result will be:“512”, - but the result is a string, so we convert it to an integer with
int()(it’s needed for later analysis).
Scraping the publication city/country information is as easy as:
try:
bestseller_book["city/country"] = bestseller_book_soup.find("ul", class_="biblio-info").find("label", text="Publication City/Country").find_next_sibling("span").get_text(strip=True)
except AttributeError:
bestseller_book["city/country"] = ""
I believe no explanation is needed here; if you’ve completed the previous two Beautiful Soup articles, then you should have enough knowledge to understand everything. 😉
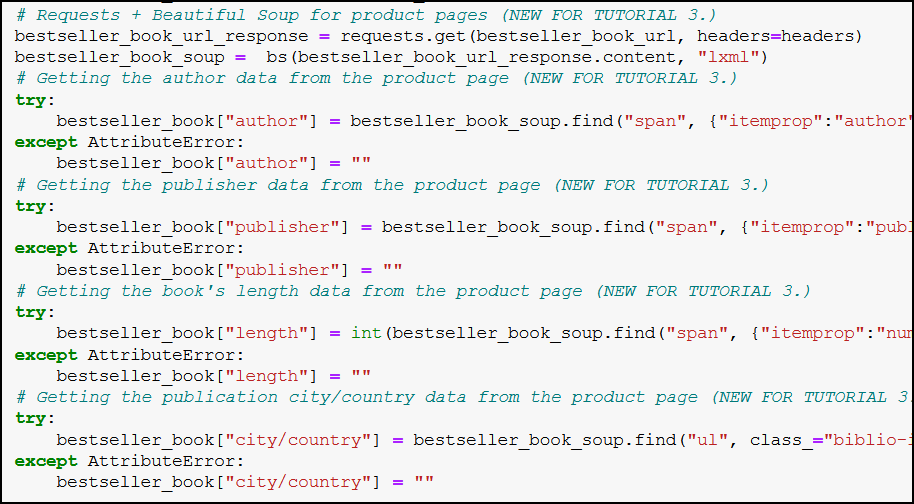
All of these together:
The lines of codes we’ve written in this section should be placed after the bestseller_book_soup part in our code, as shown in the screenshot:
Scraping categories data from product pages
Don’t stop here. Let’s gather more data for our analyses! This one will be a piece of cake. The categories of a book are located at the top of the product page:
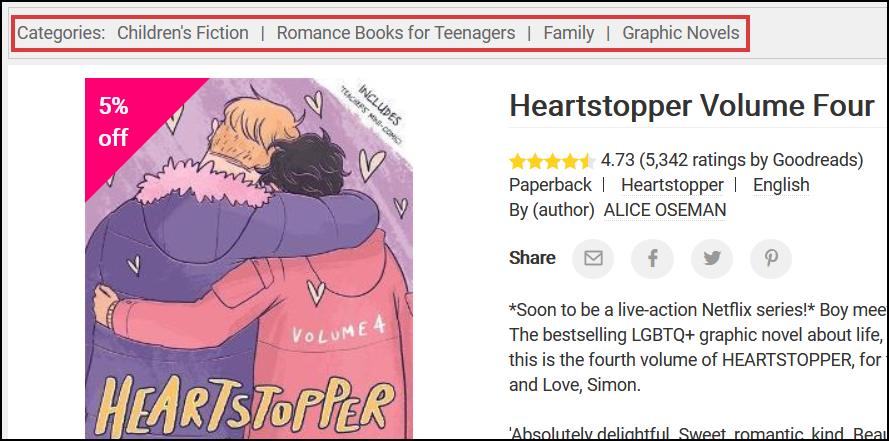
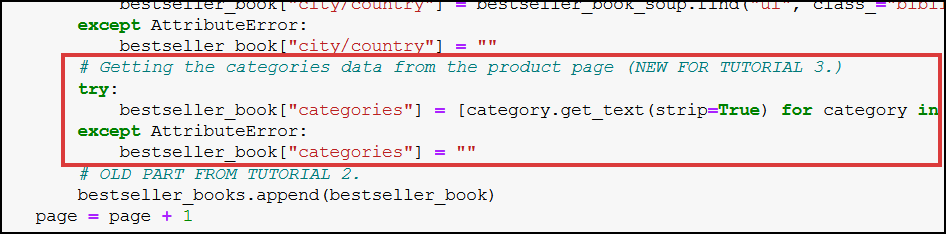
This is the full code that fetches us the categories:
try:
bestseller_book["categories"] = [category.get_text(strip=True) for category in bestseller_book_soup.find("ol", class_="breadcrumb").select("li a")]
except AttributeError:
bestseller_book["categories"] = ""
As you can see, it’s basically a list comprehension:
- we locate the categories with
bestseller_book_soup.find("ol", class_="breadcrumb").select("li a"), - then we add every category (
category.get_text(strip=True)) to thebestseller_book["categories"]list, - and if there’s no category, we leave our list empty (
bestseller_book["categories"] = "").
This code goes almost at the end of our “old” code:
Scraping 1,000 product+ pages, and using time.sleep()
For convenience’s sake, here’s our whole scraping code completed with the lines we’ve written in this article:
page = 1
bestseller_books = []
while page != 35:
url = f"https://www.bookdepository.com/bestsellers?page={page}"
response = requests.get(url, headers=headers)
html = response.content
soup = bs(html, "lxml")
for book in soup.find_all("div", class_="book-item"):
time.sleep(1)
bestseller_book = {}
bestseller_book["title"] = book.h3.get_text(strip=True)
bestseller_book_url = f'https://www.bookdepository.com{book.h3.find("a")["href"]}'
bestseller_book["url"] = bestseller_book_url
bestseller_book["format"] = book.find("p", class_="format").get_text()
try:
bestseller_book["year"] = book.find("p", class_="published").get_text()[-4:]
except AttributeError:
bestseller_book["year"] = ""
price = book.find("p", class_="price")
try:
original_price = price.find("span", class_="rrp")
except AttributeError:
bestseller_book["price"] = ""
else:
if original_price:
current_price = str(original_price.previousSibling).strip()
current_price = float(current_price.split("€")[0].replace(",", "."))
else:
current_price = float(price.get_text(strip=True).split("€")[0].replace(",", "."))
bestseller_book["price"] = current_price
bestseller_book_url_response = requests.get(bestseller_book_url, headers=headers)
bestseller_book_soup = bs(bestseller_book_url_response.content, "lxml")
try:
bestseller_book["author"] = bestseller_book_soup.find("span", {"itemprop":"author"}).find("span", {"itemprop":"name"}).get_text(strip=True)
except AttributeError:
bestseller_book["author"] = ""
try:
bestseller_book["publisher"] = bestseller_book_soup.find("span", {"itemprop":"publisher"}).find("span", {"itemprop":"name"}).get_text(strip=True)
except AttributeError:
bestseller_book["publisher"] = ""
try:
bestseller_book["length"] = int(bestseller_book_soup.find("span", {"itemprop":"numberOfPages"}).get_text(strip=True).split(" ")[0])
except AttributeError:
bestseller_book["length"] = ""
try:
bestseller_book["city/country"] = bestseller_book_soup.find("ul", class_="biblio-info").find("label", text="Publication City/Country").find_next_sibling("span").get_text(strip=True)
except AttributeError:
bestseller_book["city/country"] = ""
try:
bestseller_book["categories"] = [category.get_text(strip=True) for category in bestseller_book_soup.find("ol", class_="breadcrumb").select("li a")]
except AttributeError:
bestseller_book["categories"] = ""
bestseller_books.append(bestseller_book)
page = page + 1
There’s a very important addition at the beginning of the code: time.sleep(1)
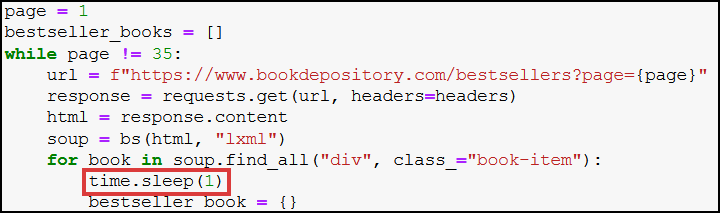
time.sleep(1) stops our code from running for one second. It’s important to use it, because without it our program would just simply request too many web pages too fast, which is a sign for web servers that not-a-person is doing the requests.
Why is that a problem?
See it for yourself:
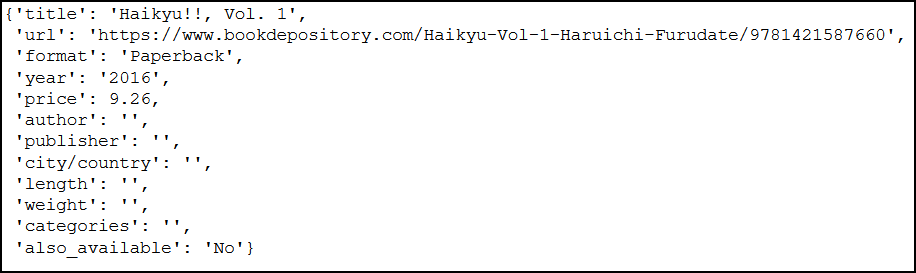
The web server denied to give us several requested data (for example length, publisher, etc.), while the product page clearly contains them:
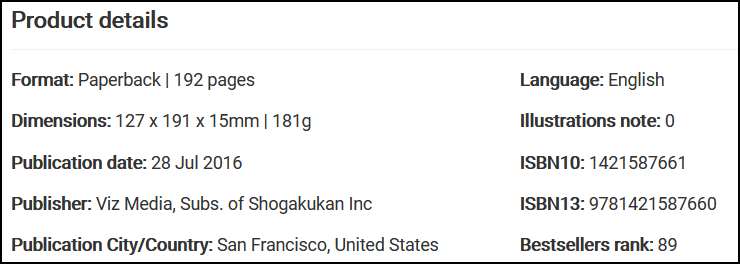
To use time.sleep(), just import Python’s time module with import time.
Now, you are ready to run your new scraping code. Do note that it will scrape more than 1,000 URLs, which will take time (it took me around 20-25 minutes).
If you don’t want to wait that long, just decrease the number of product pages you want to scrape from 35 to 10 (or to any number you are comfortable with scraping; just rewrite this part of the code: while page != 35:).
If you loop through bestseller_books after you’ve finished scraping, you’ll get a similar list:
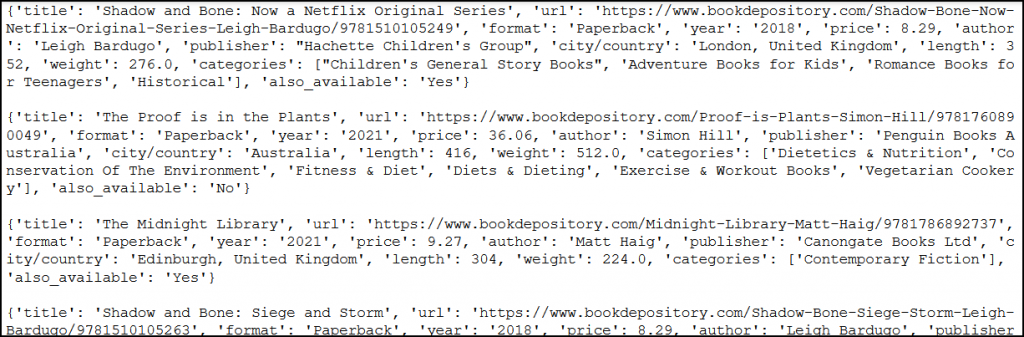
Conclusion — we scraped 1,000+ URLs with Python!
Yes, this is exactly what we did. Let that sink in, because it’s no small achievement. 😉
Now you can be confident enough in your web scraping skills to easily gather data from the web – and large amounts of data for that matter.
But data in and of itself is not useful; what matters is the insights you extract from it. And this is what we’ll focus on in the next article: you’ll learn how to save your scraped data, and then how to analyze it with pandas so you can amaze your friends/colleagues/boss even more!
- If you want to learn more about how to become a data scientist, take Tomi Mester’s 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out the 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tamas Ujhelyi