
Yesterday was the live final of our data science competition. One of our finalists pulled out a trick that I think everyone should take note of…
By the way, our top three finishers were:
- Roland Nagy 🏆
- Bernadett Horváth
- Tamás Berki
Congratulations and a big thank you to all three! I’ll be posting pictures from the event on my LinkedIn soon.
But let’s get back to the secret trick. (Well, it won’t be so secret after this post!)
What Makes a Dog Run Fast?
Just for context, let me quickly (and in a pretty simplified way) explain the problem that our contestants had to solve:
- We have a large dataset containing information from dog relay races (the specific sport is called Flyball. The goal is for 4 dogs to run as a team on a track, each taking turns. Multiple teams compete in a race, and the team of four that finishes the fastest wins).
- The question is: What factors most influence the dogs’ running performance?
At first, the task seems simple.
We might start by examining whether bigger or smaller dogs run faster…
Then, we could look at which age group of dogs performs the best…
Or analyze which dog breed is the most skilled…
But then, the question starts to get more complicated:
- What time of day does the team perform best?
- Does the sequence of neutered vs. non-neutered dogs affect race time?
- And does alternating between male and female dogs have an impact?
- Does it matter if the dogs know each other in terms of their race time?
- And let’s not forget to factor in the weather conditions…
- …
- …
The more analyses we run, the more new questions arise.
I’m sure our data science competition participants could tell you a lot about that.
But the truth is, this is almost exactly what happens in real-world business projects as well.
This is where a small Machine Learning technique can come in handy.
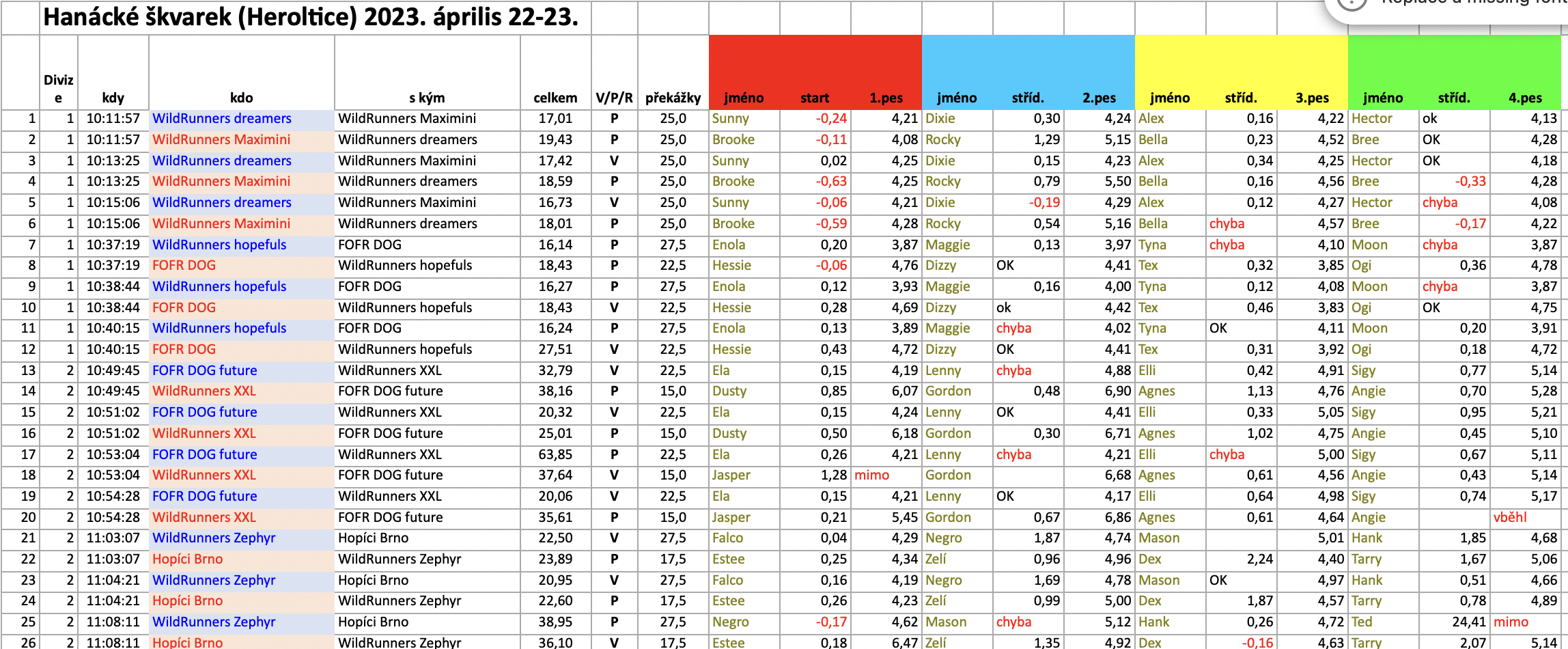
By the way, here’s a screenshot/snippet of the delightfully challenging dataset that had to be analyzed in the competition. (Thanks a lot for the data for the Flyball Club of the Czech Republic!)
Machine Learning Recap
Before I dive into the specific method, let’s quickly go over some basics of ML.
We typically turn to Machine Learning algorithms when:
- We want to predict something (e.g., in a factory: “This machine is likely to break down within a month”)
OR - We need to classify (e.g., in a SaaS business: “This non-paying user is very similar to paying users”)
OR - We might want to do a bit of clustering (e.g., in a store: “These products are typically bought together by a certain customer group”)
…
(These are just a few examples, but I’ll dive deeper into this in a future blog post.)
The core idea behind Machine Learning projects (at least for most predictive and classification tasks) is that:
- we have a bunch of input variables
- and one output variable that we want to optimize for
Here’s a simple, everyday example:
SITUATION AND PROBLEM TO SOLVE:
You walk into a store, make your purchases, and want to decide which checkout line to join.
OUTPUT VARIABLE (what you’re optimizing for):
Time spent waiting in line. (You want this to be as short as possible, so you can leave the store quickly.)
INPUT VARIABLES (factors that could influence your output):
- How many people are in each line
- How many items are in the carts of the people ahead of you
- The average age of the people in the line (I didn’t say this, algorithm said it! 🙃)
…
If we were to solve this problem using a Machine Learning approach, we’d feed the algorithm, say, two years of past data, and it would calculate how much each input variable impacts the output. Based on that, it would estimate the waiting time for each line in the current situation, allowing us to choose the best one.
Note: Of course, I’m simplifying—there are a lot of nuances and challenges in ML, but I think this example works well as a comparison.
The Importance of Input Variables
And here’s the key takeaway that we can bring into any analysis project from a Machine Learning (ML) project.
Often, the greatest business value isn’t knowing which specific line to join, but rather understanding how each input variable impacts the output.
(Often, it’s not the “what?” but the “why?” that’s most interesting.)
…
Going back to the dog example, Roland, the winner of our DS competition, told me during the coffee break that although he mostly worked with basic retrospective analyses, he did use a bit of Machine Learning to verify if the algorithm identified the same important variables for a dog’s running time as he did. This is what he got:
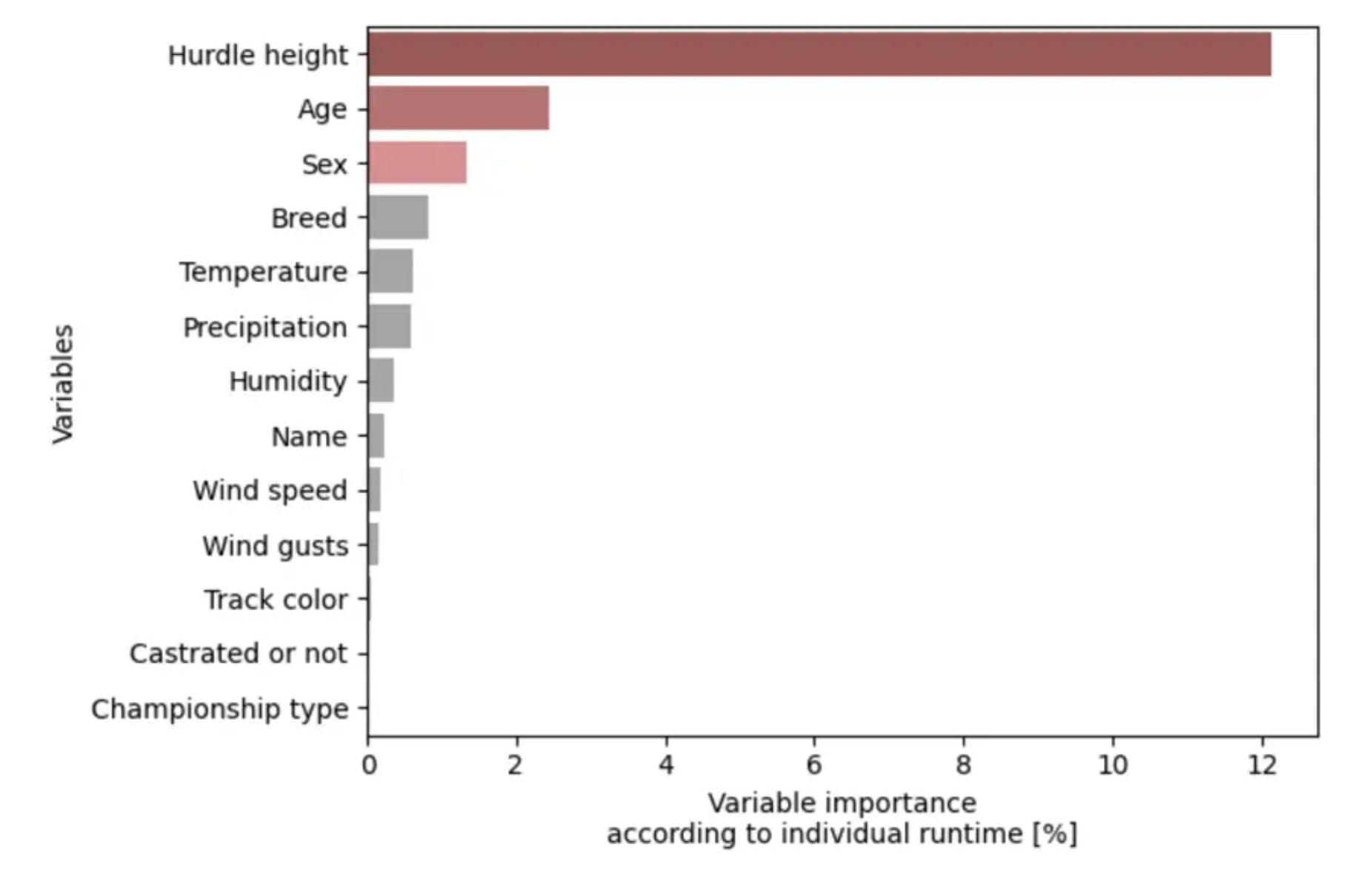
Of course, this was just a small step in his otherwise very complex analysis, but it definitely caught my attention (and I know the judges liked it too).
And how cool is it in any real-life data project when you get a chart like this? It helps point you in the right direction when dealing with a seemingly endless dataset.
A Business Example
Let me show you another example.
On my blog (data36.com) I was consistently writing articles for a while. Naturally, I was curious to see which articles had the biggest impact on later conversions (in my case, course purchases).
I had the data, so I quickly ran my own analysis:
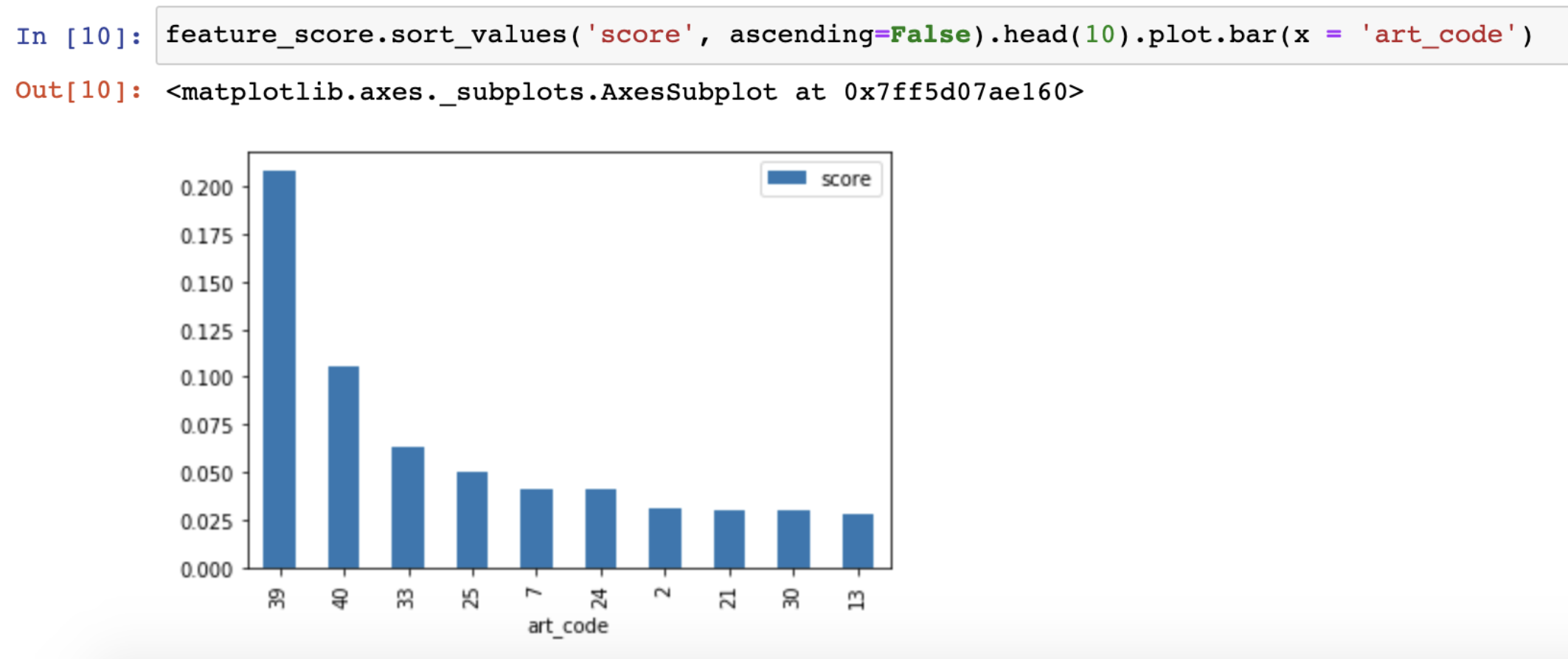
The method is quite similar to Roland’s—except, in my case, each column represents the reading of a specific article. It’s coded in the chart, but for example, column 39 represents my article “Learning Data Science (4 Untold Truths).” This article had the largest impact on whether a reader would later become a customer. (Interestingly, the next three articles were also similar in being introductory and topic-related.)
This quick and simple insight helped me a lot in deciding what new articles to write – and also in identifying which ones to promote more heavily to my audience through my international newsletter, ads, etc.
What Methods Are Available for Evaluating Variables Importance?
There are many ways to perform this kind of analysis on the importance and weights of input variables in Python.
Several methods and implementations exist, each with its own strengths. They differ slightly from one another (and can produce different results) – plus, not all methods can be applied to every model.
…
- In the competition, Roland used the SHAP methodology/library. (LINK)
- In my article example, I ran a function called feature_importances_ (LINK)
- I’ve also seen senior data professionals use a method called Partial Dependence Plots (PDP) (LINK)
- …
So, there are plenty of solutions, each suited for different cases and backed by different math.
I had ChatGPT create a handy little table to help you get started: here.
…
Summary
I think this input variable analysis is a super useful trick. I even use it in projects where I wouldn’t necessarily apply machine learning in the traditional sense.
To wrap things up, let me add a general data science reminder:
Although you’ll see that running one of these solutions in Python can be done easily in just a few lines (especially if you already have your ML model), it’s crucial to deeply understand what each method is actually telling you about the importance of the variables. This will prevent any misinterpretation. (The little table from ChatGPT above is a good starting point, but it’s also worth diving deeper into the documentation of these methods.)
That’s all for today!
I hope you found it interesting!
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester