
I get way too many questions from aspiring data scientists regarding machine learning. Like what parts of machine learning they should learn more about to get a job.
And I don’t want to disappoint you — but the thing is that when you get started as a junior, 95% of your projects won’t be about Machine Learning. At least, that’s a rough average.
So what parts of ML should you learn more about when preparing for your first job?
Well. None? 🙂
Okay, that’s not true. There are some parts that you’ll have to know about. I’ll get back to that soon. But first, I want to explain to you the reasons behind my answer.
Note: this article is available in Youtube video format here — and in podcast format here (and on Spotify, iTunes, Google Podcast, etc.)
Machine learning is for more experienced data scientists
Machine learning is not easy.
In fact, the easiest part of it is the coding part. There are tons of awesome libraries in Python (like numpy, pandas, scipy, scikit-learn, tensorflow and more…) that make the job of a data scientist much easier.
But even so, you can’t ignore the statistical and business considerations behind these machine learning algorithms and projects. To make no mistakes, you should have a few years of experience. And that means that machine learning projects are not really for freshly starting data scientists.
You can still get involved in one. But most likely you will be asked to support a senior data scientist by preparing the project, cleaning the data, writing smaller modules in the code and so on. Working on these minor parts will also help you to see how that senior data scientist approaches the problems. As I said, you’ll learn machine learning by doing it on the job.
And that leads us back to the things that I always say about learning data science. The best way to prepare to get your first data scientist position is not focusing heavily on machine learning… but to master the basic skills:
- being fluent with Python and SQL,
- understanding the business logic behind simpler analytical methods,
- being familiar with the basics of statistics,
- practicing and experiencing the pain of working with a raw and uncleaned data set,
- learning how to automate and so on…
The Machine Learning algorithms Junior Data Scientists should know
With that being said, it’s still worth knowing a few algorithms and concepts. Why? For three reasons:
- Through these, you can understand better how machine learning works in general. Once you get the concept of a simpler model, it’ll be much easier to understand a more complex one later.
- As I said, maybe you’ll have to support a senior data scientist’s work in a machine learning project. If so, you’ll have to be familiar with the basic concepts… even if you don’t know all the tiny details of the exact algorithms she uses.
- It can still happen that you’ll get smaller prediction tasks as a junior. You can do these on your own, if you learn a few basic algorithms.
If you ask me, you should learn only these three models, for now:
#1 Linear and polynomial regression (for prediction)
A simple task that I got as a junior data scientist was this:
“We have 3 years of data about our website usage and support tickets. Please figure out, based on the trends, how many new support agents should we hire?”
You can complicate this task as much as you want. But the truth is that I was able to give a pretty accurate prediction by using a simple line fitting model. And when it comes to line fitting, the simplest machine learning algorithm you can use is polynomial regression.
It can be done in Python, for instance, using the numpy library. Polynomial regression is great! It’s easy to implement it, easy to understand it — so as I see it, it’s the best first machine learning concept that an aspiring data scientist should learn.
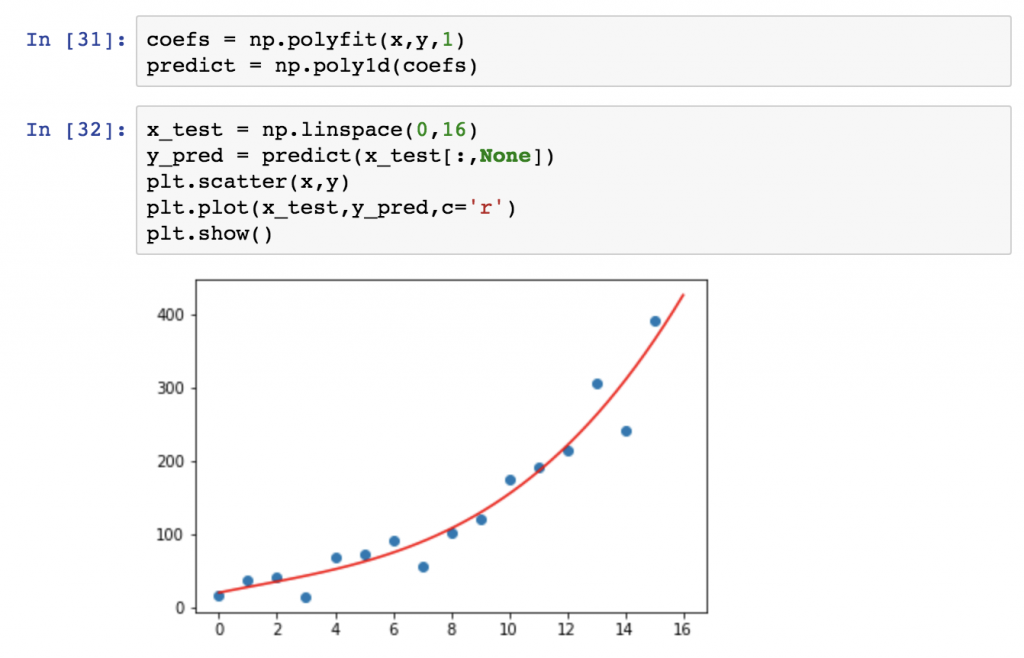
Here’s a very detailed article with code and with a downloadable Jupyter Notebook about linear regression in Python to help you get started.
#2 Random forest and/or decision tree (for classification)
Another easy task that I got in my first year as a data scientist was this:
“Please review the different user behaviours in our database and try to come up with a method to flag users who are likely to cancel their subscriptions.”
There are many ways to solve this problem but at its core, this is a classification task. Classification is one level trickier than prediction was. Still, it’s worth understanding how it works. From the perspective of coding, the easiest algorithm you can use is random forest. It is part of the scikit-learn library and it’s not too hard to implement, either.
The catch is that to exactly understand the logic of the random forest algorithm is a bit tricky — at least this is what I have seen for the students I work with in my 6-week data science course. So I usually recommend learning the concept of the model called decision tree, first.
Especially, that there is an awesome visual online tutorial for it, here.
#3 Clustering
Recently, I ran into an interesting question regarding my data science blog. I wanted to build user segments based on what articles different users read. I’ve used a clustering algorithm to do so — which automatically detected five typical user segments based on their reading behaviours.
You can run into similar tasks as a junior. And it usually can be solved by using clustering algorithms. The most well-known clustering algorithm is K-means. It’s also easy to interpret and implement in Python. So it’s worth taking a look at that, too.
Just so you know, I ended up using a more complex algorithm. It was the networkx Python library. That resulted in something like this.
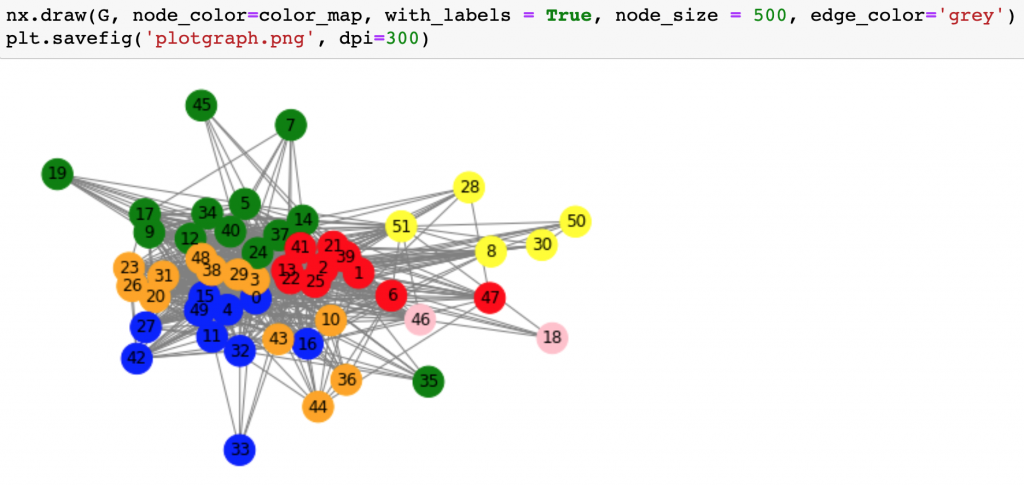
It’s a graph-based clustering solution. You shouldn’t learn about it right now — I was just so excited creating this that I couldn’t not show it to you. 🙂
Machine learning specializations
So if you know these three machine learning algorithms:
- Linear and polynomial regressions
- Decision tree and random forest
- K-means clustering
…you’ll do just fine as a junior data scientist. In your first year, at least.
And as I said, it doesn’t mean that you won’t have to learn new algorithms later, on the job. In fact, it’s pretty likely that you’ll have to. Once you have a solid understanding of the fundamentals, you can specialize in many directions:
- natural language processing (NLP)
- deep learning
- predictive analytics
- and many more…
There are so many different directions and specializations within data science — and each and every of these can be turned into a very successful career.
For instance, if you happen to start to work on self-driving cars, naturally, you’ll become very advanced in deep learning and maybe you won’t learn anything about natural language processing during your career. That’s just fine. But that’s another reason to let this work itself out over the years… and not spend too much time with machine learning before getting your first job.
Conclusion
So what fields of Machine Learning should an aspiring data scientist learn and practice more?
Only the basic ones: simple regression, classification and clustering models.
And right now you should focus more on being better with the basic stuff: Python, SQL, data cleaning, automations, and so on… Leave the more advanced machine learning algorithms until later: you’ll be able to learn them on the job, while getting more senior in data science.
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers,
Tomi Mester
Cheers,
Tomi Mester