
As an aspiring data scientist you have to deal with the huge responsibility of data privacy every day. Depending on where you work and what data you are working on, practices differ widely, results ranging from bad to worse and tragic.
- You might be touching production data all the time, without thinking about the privacy of the subjects.
- You might be told to take care of data anonymization yourself, as part of the data prep process.
- You might have to fight the status quo and explain to people what is anonymous data and what isn’t.
- In more privacy-sensitive industries, like banking and insurance, you might end up working with data that has been destroyed with old data anonymization tools by IT departments that know next to nothing about data science.
Sounds like fun? Well, if you know some basic rules and what tools to use when, you can be confident in your data privacy decisions.

This article is written by Agnes Fekete from Austria. Agnes works for Mostly.AI — they create safe, accurate, relevant, insightful synthetic data that helps teams collaborate and innovate towards a smarter and fairer future.
What is the definition of anonymous data?
Let’s start with something seemingly obvious, that is actually a subject of hot debate in most organizations. According to GDPR’s Recital 26, a dataset is anonymous when individuals cannot be identified directly or indirectly.
There is no specific methodology recommended for data anonymization, but the text explicitly states that pseudonymization – when direct identifiers are encrypted or masked – is not anonymization. Still, pseudonymization techniques like encryption are often used or personally identifiable information is simply removed from datasets in the name of anonymiz. Does that make a dataset anonymous? Absolutely not!
So-called proxy-identifiers can still identify an individual in the data. According to research, only 15 demographic characteristics are enough to re-identify nearly all Americans. Behavioral or time series data that describes a series of events, such as credit card transactions, location data or patient journeys, is even more difficult to anonymize. A taxi ride can be as telling as a fingerprint.
Even without time-series data, just the quantity of the data itself can cause privacy issues. The more data there is, the harder it is to anonymize without destroying data utility. New attack types, like linkage attacks, where different datasets are linked together with publicly available data to expose individuals’ identities, are also on the rise.
What was once accepted as anonymous data, no longer is. As a data scientist you need to be aware of the potential pitfalls common data anonymization tools could cause and you also need to know what tools to use instead.
The dangers of old school data anonymization tools
Let’s see those pitfalls from up-close!
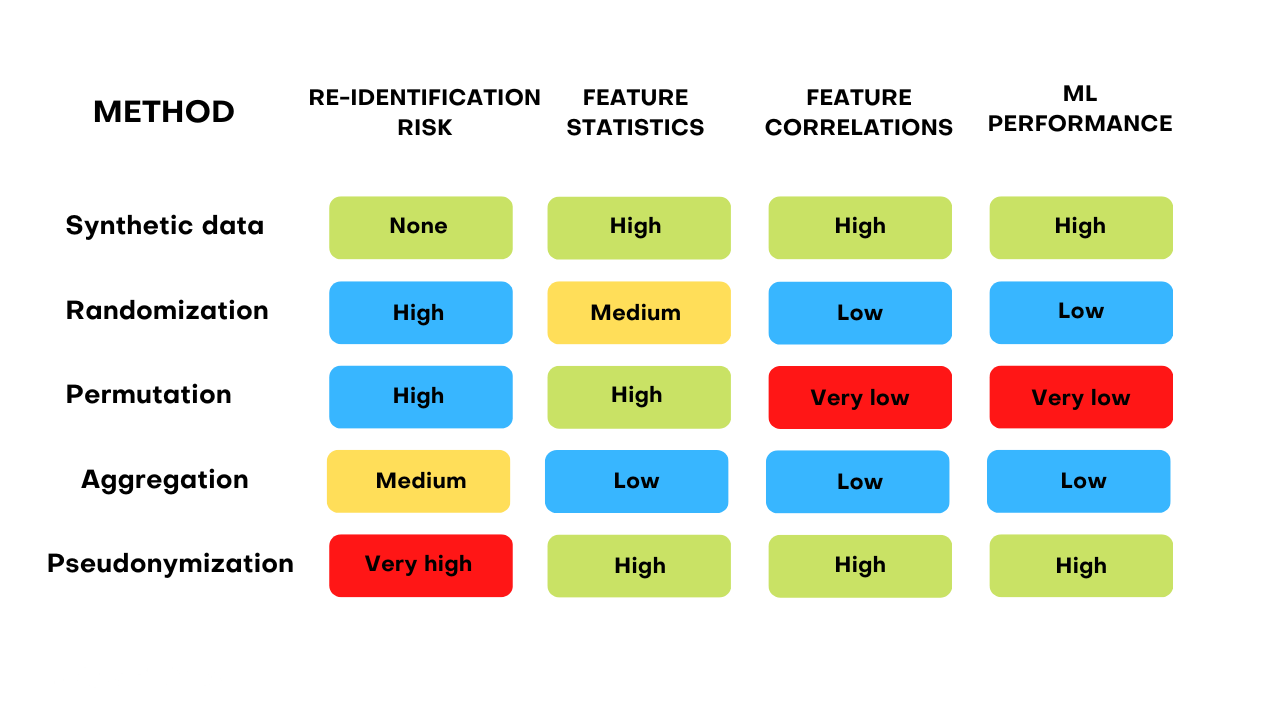
Aggregation
Aggregating data is one of the most common procedures done on data in the name of privacy. At first, it looks like an easy and surefire way to anonymize data – define a minimum threshold for the number of people to be included in the data with the same combination of attributes, like gender and age. The groups not reaching the threshold would be excluded.
However, knowing the total number of people in the column would make it easy to figure out how many people were in the excluded group. Even without knowing the total for each column, data produced over time could identify a single individual who for example was added to the dataset from one month to the next. And the bigger and more complex the data, the messier this gets. One thing is for sure, aggregation is not a sure-fire way to protect privacy. What’s more, due to the exclusion of certain, smaller groups, the statistical usefulness and granularity of the data is massively reduced.
Randomization
Randomization is also frequently used in the form of adding noise to datasets. However, the noise only makes it harder for attackers to identify subjects in a dataset – not impossible. Adding noise can only be a complimentary measure and should never be used on its own. Permutation – when data points, such as names are switched around to protect privacy can be easily undone. What’s more, correlations might be completely destroyed by applying column-wise permutation, making your machine learning models less smart, more covertly biased and more prone to mistakes.
What’s next for data anonymization?
Ok, so we established that the above mentioned old tools no longer cut it in today’s world of complex data structures and increasingly sophisticated attacks. There are new tools with entirely new approaches to privacy driven by the technological advances we see around us.
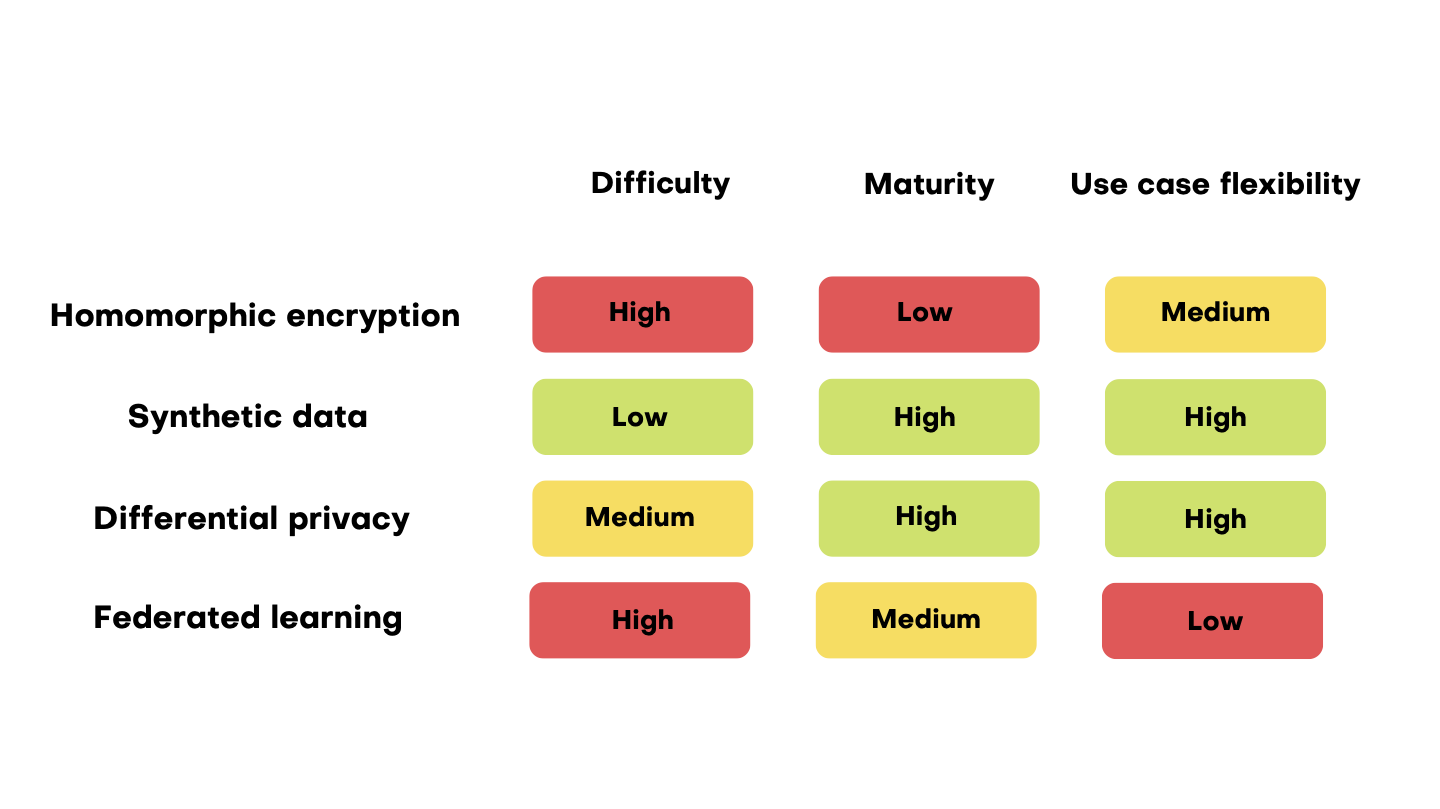
Privacy enhancing technologies or PETs for short include some of the latest innovations from the fields of encryption, statistics and AI. Some of them are still in early stages and only the most tech-savvy companies have access to, like homomorphic encryption, which is computationally very intensive. (More about that soon…)
The most popular privacy enhancing technologies:
- Homomorphic encryption
- AI-generated synthetic data
- Differential privacy
- Federated learning
Let’s see them one by one!
Homomorphic encryption
The technology of homomorphic encryption lets you do analytics on encrypted data without ever decrypting it. You won’t be able to access homomorphic encryption tools from your bedroom, but for example, some large banks are already running pilot projects on training predictive models on homomorphically encrypted data.
AI-generated synthetic data
Not to be confused with mock data that is generated based on rules, AI-generated synthetic data is generated based on data samples. Deep learning is set to revolutionize many things, data privacy included. Synthetic data generation is a great way to retain statistical properties of a dataset without any of the original datapoints.
How does it work?
The AI needs a large enough data sample to learn the patterns and correlations. Once the training has taken place, the algorithm can generate as much or as little of statistically similar data as the original. As with any data privacy method, synthetic data should be generated with great care. If the AI overfits, it can learn original data by accident. If outliers are not properly handled, some privacy can still leak.
There are open source synthetic data generators out there that require coding skills and a high-level of knowledge for accuracy and privacy monitoring. Proprietary synthetic data generators offer an easier alternative with no-code interfaces. Since they are fairly easy to generate, the main synthetic data use cases include test data generation as well as training data generation for machine learning models.
The process of synthesization can also be used for data augmentation purposes, for example to upsample minority groups in a datasets. Since the AI learns all the patterns and correlations, your new synthetic subjects will look realistic.
Differential privacy
Differential privacy is a bit of an odd-ball in the list of privacy enhancing technologies, since it’s not so much a privacy-making process, but a mathematical definition of privacy. An algorithm is differentially private if its output doesn’t differ if any individual’s data was included in the original dataset. This number is called the epsilon value.
The higher the number, the more likely it is that there is a privacy leak. Anything below 1 can be considered a privacy-safe value of epsilon. However, you’ll rarely see such values in the wild, which is an issue in itself. Companies like Apple boast about using epsilons as high as 8.
Hey, but at least they are transparent about it, unlike most other big techs. Differential privacy can only ever be an additional measure of privacy. Most often it is used in conjunction with another PET, like synthetic data or federated learning.
Federated learning
Federated learning is often used in mobile technology where machine learning models can be trained and operated locally on devices, so the data doesn’t have to travel at all. These local model updates feed into a central model. Although data is never moved from one place to another, privacy can still leak through the models. In this case, differential privacy is perfect for monitoring the privacy-level of the models. Other anonymous computing technologies also exist and work on similar principles, such as secure multi-party computation, where different parties can work on the same encrypted data, that is kept private from participants. It’s a pretty complicated process and as such, not a low-hanging fruit of the PET-world.
The conclusion: out with the old, in with the new
While some legacy data anonymization techniques can still be useful in certain, low-data volume situations, it’s good to be aware of the limitations. Data masking techniques such as pseudonymization, randomization, deletion and so on are masking important details and insights as well as privacy issues that could be important. Just because you can’t see it, it doesn’t mean it’s not there. Play around with new PETs, starting with the easily accessible technologies, like differential privacy or synthetic data.
Privacy regulations are getting stricter every day and companies are increasingly looking for data privacy implementation skills in their hiring processes to protect not only their customers’ data, but their own reputation.
Buckle up folks, privacy is here to stay and we better get good at it.
Cheers,
Agnes